Go入门
Go介绍
环境配置
安装
- 下载源码编译安装
- 下载相应平台的安装包安装 下载地址:https://golang.org/dl/
- Linux上的
apt-get,yum,Mac上的homebrew安装
安装完成后命令行输入go,如果显示帮助信息则安装成功
GOPATH
GOPATH:用来存放用户的Go源码,Go的可运行文件,以及相应的编译之后的包文件
- src 存放源代码,使用go get下载的代码会放到这个目录
- pkg 编译后生成的文件(比如:.a)
- bin 编译后生成的可执行文件
go命令和常用工具

go install:编译并把编译好的结果移到$GOPATH/pkg或者$GOPATH/bin
go build :编译(项目和文件)
常用参数:
-o 指定输出的文件名,可以带上路径,例如 go build -o out main.go
-i 安装相应的包,编译+go install
-v 打印出来我们正在编译的包名
go get:安装第三方包
常用命令:
-d 只下载不安装
-u 强制使用网络去更新包和它的依赖包
-v 显示执行的命令
go clean:移除当前源码包和关联源码包里面编译生成的文件
go fmt:格式化代码
godoc:文档
godoc -http=:端口号 比如godoc -http=:8080然后打开127.0.0.1:8080可以在浏览器中查询pkg文档
godoc net/http:查看http包的文档
godoc -src fmt Printf:查看fmt.Printf的代码
go run 编译并运行Go程序
开发工具
个人喜欢用vscode,装个插件可以实现包自动导入、代码自动格式化、错误提示等功能
JetBrains最近刚出了一个GoLand
Go语言基础
Hello,world
package main
import "fmt"
func main() {
fmt.Printf("Hello, world! 你好,世界
")
}
输出:Hello, world! 你好,世界
基础类型
变量
// 定义变量
var v1 int
// 定义多个变量
var v1, v2, v3 string
// 定义多个变量并赋值
var enabled, disabled = true, false
v1 := "go"
go语言里定义的变量、声明的包必须要使用,否则编译会报错;_这个变量比较特殊,任何赋予它的值都会被丢弃
常量
const Pi float32 = 3.1415926
基础内置类型
1、Boolean
2、int, uint
Go同时支持int和uint,这两种类型的长度相同,但具体长度取决于不同编译器的实现。Go里面也有直接定义好位数的类型:rune, int8, int16, int32, int64和byte, uint8, uint16, uint32, uint64。其中rune是int32的别称,byte是uint8的别称
3、float32, float64
浮点数的类型有float32和float64两种(没有float类型),默认是float64
4、string
Go中的字符串都是采用UTF-8字符集编码。字符串是用一对双引号("")或反引号``括起来定义,它的类型是string
5、error
Go内置有一个error类型,专门用来处理错误信息,Go的package里面还专门有一个包errors来处理错误
6、complex
复数类型。它的默认类型是complex128(64位实数+64位虚数)。如果需要小一些的,也有complex64(32位实数+32位虚数)。复数的形式为RE + IMi,其中RE是实数部分,IM是虚数部分,而最后的i是虚数单位。
分组声明:在Go语言中,同时声明多个常量、变量,或者导入多个包时,可采用分组的方式进行声明。
例:
import "fmt"
import "os"
const i = 100
const pi = 3.1415
const prefix = "Go_"
var i int
var pi float32
var prefix string
可以分组写成如下形式:
import(
"fmt"
"os"
)
const(
i = 100
pi = 3.1415
prefix = "Go_"
)
var(
i int
pi float32
prefix string
)
Go程序设计的一些规则
Go之所以会那么简洁,是因为它有一些默认的行为:
- 大写字母开头的变量是可导出的,也就是其它包可以读取的,是公有变量;小写字母开头的就是不可导出的,是私有变量。
- 大写字母开头的函数也是一样,相当于class中的带public关键词的公有函数;小写字母开头的就是有private关键词的私有函数。
数组、切片和映射
数组
数组声明
var arr [10]int // 声明了一个int类型的数组
arr[0] = 42 // 数组下标是从0开始的
arr[1] = 13 // 赋值操作
fmt.Printf("The first element is %d
", arr[0]) // 获取数据,返回42
fmt.Printf("The last element is %d
", arr[9]) //返回未赋值的最后一个元素,默认返回0
声明并赋值
a := [3]int{1, 2, 3} // 声明了一个长度为3的int数组
b := [10]int{1, 2, 3} // 声明了一个长度为10的int数组,其中前三个元素初始化为1、2、3,其它默认为0
c := [...]int{4, 5, 6} // 可以省略长度而采用`...`的方式,Go会自动根据元素个数来计算长度
二维数组
// 声明了一个二维数组,该数组以两个数组作为元素,其中每个数组中又有4个int类型的元素
doubleArray := [2][4]int{[4]int{1, 2, 3, 4}, [4]int{5, 6, 7, 8}}
// 上面的声明可以简化,直接忽略内部的类型
easyArray := [2][4]int{{1, 2, 3, 4}, {5, 6, 7, 8}}
切片
在很多应用场景中,数组并不能满足我们的需求。在初始定义数组时,我们并不知道需要多大的数组,因此我们就需要“动态数组”。
slice并不是真正意义上的动态数组,而是一个引用类型。slice总是指向一个底层array,slice的声明也可以像array一样,只是不需要长度。
声明:
// 和声明array一样,只是少了长度
var fslice []int
// 声明并赋值
slice := []byte {'a', 'b', 'c', 'd'}
// 声明一个含有10个元素元素类型为byte的数组
var ar = [10]byte {'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'}
// 声明两个含有byte的slice
var a, b []byte
// a指向数组的第3个元素开始,并到第五个元素结束,
a = ar[2:5]
//现在a含有的元素: ar[2]、ar[3]和ar[4]
// b是数组ar的另一个slice
b = ar[3:5]
// b的元素是:ar[3]和ar[4]
从Go1.2开始slice支持了三个参数的slice,之前我们一直采用这种方式在slice或者array基础上来获取一个slice
var array [10]int
slice := array[2:4]
// 里面slice的容量是8,新版本里面可以指定这个容量
slice = array[2:4:7]
也可以用make创建一个slice
var s = make([]int, 5) //长度是5,容量是5
var s = make([]int, 5, 10) //长度是5,容量是10
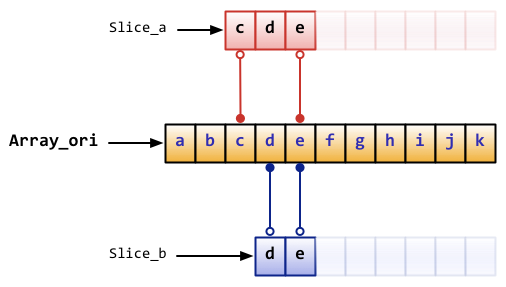
对于slice有几个有用的内置函数:
- len 获取slice的长度
- cap 获取slice的最大容量
- append 向slice里面追加一个或者多个元素,然后返回一个和slice一样类型的slice
- copy 函数copy从源slice的src中复制元素到目标dst,并且返回复制的元素的个数
slice是引用类型,所以当引用改变其中元素的值时,其它的所有引用都会改变该值,例如上面的aSlice和bSlice,如果修改了aSlice中元素的值,那么bSlice相对应的值也会改变。
从概念上面来说slice像一个结构体,这个结构体包含了三个元素:
- 一个指针,指向数组中slice指定的开始位置
- 长度,即slice的长度
- 最大长度,也就是slice开始位置到数组的最后位置的长度
映射(map)
map也就是Python中字典的概念,它的格式为map[keyType]valueType
我们看下面的代码,map的读取和设置也类似slice一样,通过key来操作,只是slice的index只能是`int`类型,而map多了很多类型,可以是int,可以是string及所有完全定义了==与!=操作的类型。比如 bool, 数字,string, 指针, channel, 还有 只包含前面几个类型的 interface types, structs, arrays
// 声明一个key是字符串,值为int的字典,这种方式的声明需要在使用之前使用make初始化
var numbers map[string]int
// 另一种map的声明方式
numbers = make(map[string]int)
numbers["one"] = 1 //赋值
numbers["ten"] = 10 //赋值
numbers["three"] = 3
fmt.Println("第三个数字是: ", numbers["three"]) // 读取数据
// 打印出来如:第三个数字是: 3
使用map过程中需要注意的几点:
- map是无序的,每次打印出来的map都会不一样,它不能通过index获取,而必须通过key获取
- map的长度是不固定的,也就是和slice一样,也是一种引用类型
- 内置的len函数同样适用于map,返回map拥有的key的数量
- map的值可以很方便的修改,通过numbers["one"]=11可以很容易的把key为one的字典值改为11
- map和其他基本型别不同,它不是thread-safe,在多个go-routine存取时,必须使用mutex lock机制
map也是一种引用类型,如果两个map同时指向一个底层,那么一个改变,另一个也相应的改变:
m := make(map[string]string)
m["Hello"] = "Bonjour"
m1 := m
m1["Hello"] = "Salut" // 现在m["hello"]的值已经是Salut了
make、new操作
make用于内建类型(map、slice 和channel)的内存分配。new用于各种类型的内存分配。
内建函数new本质上说跟其它语言中的同名函数功能一样:new(T)分配了零值填充的T类型的内存空间,并且返回其地址,即一个*T类型的值。用Go的术语说,它返回了一个指针,指向新分配的类型T的零值。有一点非常重要:
new返回指针。
内建函数make(T, args)与new(T)有着不同的功能,make只能创建slice、map和channel,并且返回一个有初始值(非零)的T类型,而不是*T。本质来讲,导致这三个类型有所不同的原因是指向数据结构的引用在使用前必须被初始化。例如,一个slice,是一个包含指向数据(内部array)的指针、长度和容量的三项描述符;在这些项目被初始化之前,slice为nil。对于slice、map和channel来说,make初始化了内部的数据结构,填充适当的值。
make返回初始化后的(非零)值。
零值(默认值)
关于“零值”,所指并非是空值,而是一种“变量未填充前”的默认值,通常为0。 此处罗列 部分类型 的 “零值”
int 0
int8 0
int32 0
int64 0
uint 0x0
rune 0 //rune的实际类型是 int32
byte 0x0 // byte的实际类型是 uint8
float32 0 //长度为 4 byte
float64 0 //长度为 8 byte
bool false
string ""
流程和函数
if
Go里面if条件判断语句中不需要括号,如下代码所示
if x > 10 {
fmt.Println("x is greater than 10")
} else {
fmt.Println("x is less than 10")
}
Go的if还有一个强大的地方就是条件判断语句里面允许声明一个变量,这个变量的作用域只能在该条件逻辑块内,其他地方就不起作用了,如下所示
// 计算获取值x,然后根据x返回的大小,判断是否大于10。
if x := computedValue(); x > 10 {
fmt.Println("x is greater than 10")
} else {
fmt.Println("x is less than 10")
}
//这个地方如果这样调用就编译出错了,因为x是条件里面的变量
fmt.Println(x)
多个条件的时候如下所示:
if integer == 3 {
fmt.Println("The integer is equal to 3")
} else if integer < 3 {
fmt.Println("The integer is less than 3")
} else {
fmt.Println("The integer is greater than 3")
}
for
go语言里没有while,可以用for实现while的功能
for循环的语法:
for expression1; expression2; expression3 {
//...
}
for循环例子:
package main
import "fmt"
func main(){
sum := 0;
for index:=0; index < 10 ; index++ {
sum += index
}
fmt.Println("sum is equal to ", sum)
}
// 输出:sum is equal to 45
有些时候如果我们忽略expression1和expression3:
sum := 1
for ; sum < 1000; {
sum += sum
}
其中;也可以省略,那么就变成如下的代码了,是不是似曾相识?对,这就是while的功能。
sum := 1
for sum < 1000 {
sum += sum
}
在循环里面有两个关键操作break和continue ,break操作是跳出当前循环,continue是跳过本次循环。当嵌套过深的时候,break可以配合标签使用,即跳转至标签所指定的位置,详细参考如下例子:
for index := 10; index>0; index-- {
if index == 5{
break // 或者continue
}
fmt.Println(index)
}
// break打印出来10、9、8、7、6
// continue打印出来10、9、8、7、6、4、3、2、1
break和continue还可以跟着标号,用来跳到多重循环中的外层循环
for配合range可以用于读取slice和map的数据:
for k,v:=range map {
fmt.Println("map's key:",k)
fmt.Println("map's val:",v)
}
由于 Go 支持 “多值返回”, 而对于“声明而未被调用”的变量, 编译器会报错, 在这种情况下, 可以使用_来丢弃不需要的返回值 例如:
for _, v := range map{
fmt.Println("map's val:", v)
}
swich
i := 10
switch i {
case 1:
fmt.Println("i is equal to 1")
case 2, 3, 4:
fmt.Println("i is equal to 2, 3 or 4")
case 10:
fmt.Println("i is equal to 10")
default:
fmt.Println("All I know is that i is an integer")
}
Go里面switch默认相当于每个case最后带有break,匹配成功后不会自动向下执行其他case,而是跳出整个switch, 但是可以使用fallthrough强制执行后面的case代码。
integer := 6
switch integer {
case 4:
fmt.Println("The integer was <= 4")
fallthrough
case 5:
fmt.Println("The integer was <= 5")
fallthrough
default:
fmt.Println("default case")
}
函数
函数通过关键字func来声明:
func funcName(input1 type1, input2 type2) (output1 type1, output2 type2) {
//这里是处理逻辑代码
//返回多个值
return value1, value2
}
变参
Go函数支持变参。接受变参的函数是有着不定数量的参数的。为了做到这点,首先需要定义函数使其接受变参:
func myfunc(arg ...int) {}
arg ...int告诉Go这个函数接受不定数量的参数。注意,这些参数的类型全部是int。在函数体中,变量arg是一个int的slice:
for _, n := range arg {
fmt.Printf("And the number is: %d
", n)
}
传值与传指针
当我们传一个参数值到被调用函数里面时,实际上是传了这个值的一份copy,当在被调用函数中修改参数值的时候,调用函数中相应实参不会发生任何变化,因为数值变化只作用在copy上。如果想要在函数中修改传入的参数,就要传入地址
defer
Go语言中有种不错的设计,即延迟(defer)语句,你可以在函数中添加多个defer语句。当函数执行到最后时,这些defer语句会按照逆序执行,最后该函数返回。特别是当你在进行一些打开资源的操作时,遇到错误需要提前返回,在返回前你需要关闭相应的资源,不然很容易造成资源泄露等问题。如下代码所示:
func ReadWrite() bool {
file.Open("file")
defer file.Close()
if failureX {
return false
}
if failureY {
return false
}
return true
}
如果有很多调用defer,那么defer是采用后进先出模式,所以如下代码会输出4 3 2 1 0
for i := 0; i < 5; i++ {
defer fmt.Printf("%d ", i)
}
Panic和Recover
Go没有像Java那样的异常机制,它不能抛出异常,而是使用了panic和recover机制。一定要记住,你应当把它作为最后的手段来使用,也就是说,你的代码中应当没有,或者很少有panic的东西。这是个强大的工具,请明智地使用它。那么,我们应该如何使用它呢?
Panic
是一个内建函数,可以中断原有的控制流程,进入一个令人恐慌的流程中。当函数F调用panic,函数F的执行被中断,但是F中的延迟函数会正常执行,然后F返回到调用它的地方。在调用的地方,F的行为就像调用了panic。这一过程继续向上,直到发生panic的goroutine中所有调用的函数返回,此时程序退出。恐慌可以直接调用panic产生。也可以由运行时错误产生,例如访问越界的数组。
Recover
是一个内建的函数,可以让进入令人恐慌的流程中的goroutine恢复过来。recover仅在延迟函数中有效。在正常的执行过程中,调用recover会返回nil,并且没有其它任何效果。如果当前的goroutine陷入恐慌,调用recover可以捕获到panic的输入值,并且恢复正常的执行。
下面这个函数演示了如何在过程中使用panic
var user = os.Getenv("USER")
func init() {
if user == "" {
panic("no value for $USER")
}
}
下面这个函数检查作为其参数的函数在执行时是否会产生panic:
func throwsPanic(f func()) (b bool) {
defer func() {
if x := recover(); x != nil {
b = true
}
}()
f() //执行函数f,如果f中出现了panic,那么就可以恢复回来
return
}
main函数和init函数
Go里面有两个保留的函数:init函数(能够应用于所有的package)和main函数(只能应用于package main)。这两个函数在定义时不能有任何的参数和返回值。虽然一个package里面可以写任意多个init函数,但这无论是对于可读性还是以后的可维护性来说,我们都强烈建议用户在一个package中每个文件只写一个init函数。
程序的初始化和执行都起始于main包。如果main包还导入了其它的包,那么就会在编译时将它们依次导入。有时一个包会被多个包同时导入,那么它只会被导入一次(例如很多包可能都会用到fmt包,但它只会被导入一次,因为没有必要导入多次)。当一个包被导入时,如果该包还导入了其它的包,那么会先将其它包导入进来,然后再对这些包中的包级常量和变量进行初始化,接着执行init函数(如果有的话),依次类推。等所有被导入的包都加载完毕了,就会开始对main包中的包级常量和变量进行初始化,然后执行main包中的init函数(如果存在的话),最后执行main函数。下图详细地解释了整个执行过程:

import
我们在写Go代码的时候经常用到import这个命令用来导入包文件,而我们经常看到的方式参考如下:
import(
"fmt"
)
然后我们代码里面可以通过如下的方式调用
fmt.Println("hello world")
上面这个fmt是Go语言的标准库,其实是去GOROOT环境变量指定目录下去加载该模块,当然Go的import还支持如下两种方式来加载自己写的模块:
相对路径
import “./model” //当前文件同一目录的model目录,但是不建议这种方式来import
绝对路径
import “shorturl/model” //加载gopath/src/shorturl/model模块
上面展示了一些import常用的几种方式,但是还有一些特殊的import,让很多新手很费解,下面我们来一一讲解一下到底是怎么一回事
点操作
我们有时候会看到如下的方式导入包
import(
. "fmt"
)
这个点操作的含义就是这个包导入之后在你调用这个包的函数时,你可以省略前缀的包名,也就是前面你调用的fmt.Println("hello world")可以省略的写成Println("hello world")
别名操作
别名操作顾名思义我们可以把包命名成另一个我们用起来容易记忆的名字
import(
f "fmt"
)
别名操作的话调用包函数时前缀变成了我们的前缀,即f.Println("hello world")
_操作
这个操作经常是让很多人费解的一个操作符,请看下面这个import
import (
"database/sql"
_ "github.com/ziutek/mymysql/godrv"
)
_操作其实是引入该包,而不直接使用包里面的函数,而是调用了该包里面的init函数。
struct和interface
struct
type person struct {
name string
age int
}
var P person // P现在就是person类型的变量了
P.name = "Astaxie" // 赋值"Astaxie"给P的name属性.
P.age = 25 // 赋值"25"给变量P的age属性
fmt.Printf("The person's name is %s", P.name) // 访问P的name属性.
// 按照顺序提供初始化值
P := person{"Tom", 25}
// 通过field:value的方式初始化,这样可以任意顺序
P := person{age:24, name:"Tom"}
// 当然也可以通过new函数分配一个指针,此处P的类型为*person
P := new(person)
匿名字段
package main
import "fmt"
type Human struct {
name string
age int
phone string // Human类型拥有的字段
}
type Employee struct {
Human // 匿名字段Human
speciality string
phone string // 雇员的phone字段
}
func main() {
Bob := Employee{Human{"Bob", 34, "777-444-XXXX"}, "Designer", "333-222"}
fmt.Println("Bob's work phone is:", Bob.phone)
// 如果我们要访问Human的phone字段
fmt.Println("Bob's personal phone is:", Bob.Human.phone)
}
面向对象
如果一个函数有接收者,这个函数就被称 为方法
package main
import (
"fmt"
"math"
)
type Rectangle struct {
width, height float64
}
type Circle struct {
radius float64
}
func (r Rectangle) area() float64 {
return r.width*r.height
}
func (c Circle) area() float64 {
return c.radius * c.radius * math.Pi
}
func main() {
r1 := Rectangle{12, 2}
r2 := Rectangle{9, 4}
c1 := Circle{10}
c2 := Circle{25}
fmt.Println("Area of r1 is: ", r1.area())
fmt.Println("Area of r2 is: ", r2.area())
fmt.Println("Area of c1 is: ", c1.area())
fmt.Println("Area of c2 is: ", c2.area())
}
interface
interface是一组method签名的组合。接口是用来定义行为的类型。这些被定义的行为不由接口直接实现,而是通过方法由用户 定义的类型实现。如果用户定义的类型实现了某个接口类型声明的一组方法,那么这个用户定 义的类型的值就可以赋给这个接口类型的值。这个赋值会把用户定义的类型的值存入接口类型 的值。对接口值方法的调用会执行接口值里存储的用户定义的类型的值对应的方法。
我们通过interface来定义对象的一组行为
package main
import (
"fmt"
)
// notifier是一个定义了
// 通知类行为的接口
type notifier interface {
notify()
}
// user在程序里定义一个用户类型
type user struct {
name string
email string
}
// notify是使用指针接收者实现的方法
func (u *user) notify() {
fmt.Printf("Sending user email to %s<%s>
",
u.name,
u.email)
}
// main是应用程序的入口
func main() {
// 创建一个user类型的值,并发送通知
u := user{"Bill", "bill@email.com"}
// u.notify()
var n notifier
n = &u
n.notify()
// ./listing36.go:32: 不能将u(类型是user)作为
// sendNotification的参数类型notifier:
// user类型并没有实现notifier
// (notify方法使用指针接收者声明)
}
如果使用指 针接收者来实现一个接口,那么只有指向那个类型的指针才能够实现对应的接口。如果使用值 接收者来实现一个接口,那么那个类型的值和指针都能够实现对应的接口。
方法集规则
| Values | Methods Receivers |
|---|---|
| T | (t T) |
| *T | (t T) and (t *T) |
| Methods Receivers | Values |
|---|---|
| (t T) | T and *T |
| (t *T) | *T |
因为不是总能获取一个值的地址,所以值的方法集只包括了使用值接收者实现的方法。
未公开的标识符
当一个标识符的名字以小写字母开头时,这个标识符就是未公开的,即包外的代码不可见。 如果一个标识符以大写字母开头,这个标识符就是公开的,即被包外的代码可见。
新建一个包counters
package counters
type alertCounter int
func New(value int) alertCounter {
return alertCounter(value)
}
type User struct {
Name string
Email string
}
在main函数中:
package main
import (
"fmt"
"./counters"
)
func main() {
fmt.Println(counters.alertCounter(10)) //报错cannot refer to unexported name counters.alertCounter
count := counters.New(10)
fmt.Println(count)
u := counters.User{
Name: "bill",
Email: "bill@gmail.com",
}
fmt.Println(u)
}
空interface
空interface(interface{})不包含任何的method,正因为如此,所有的类型都实现了空interface。空interface对于描述起不到任何的作用(因为它不包含任何的method),但是空interface在我们需要存储任意类型的数值的时候相当有用,因为它可以存储任意类型的数值。它有点类似于C语言的void*类型。
// 定义a为空接口
var a interface{}
var i int = 5
s := "Hello world"
// a可以存储任意类型的数值
a = i
a = s
通道和并发
goroutine
goroutine是Go并行设计的核心。goroutine说到底其实就是协程,但是它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享。执行goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩。也正因为如此,可同时运行成千上万个并发任务。goroutine比thread更易用、更高效、更轻便。
package main
import (
"fmt"
"runtime"
"sync"
)
func main() {
runtime.GOMAXPROCS(2)
var wg sync.WaitGroup
wg.Add(2)
fmt.Println("Start Goroutines")
go func() {
defer wg.Done()
for count := 0; count < 3; count++ {
for char := 'a'; char < 'a'+26; char++ {
fmt.Printf("%c ", char)
}
}
}()
go func() {
defer wg.Done()
for count := 0; count < 3; count++ {
for char := 'A'; char < 'A'+26; char++ {
fmt.Printf("%c ", char)
}
}
}()
fmt.Println("Waiting To Finish")
wg.Wait()
fmt.Println("
Terminating Program")
}
channels
goroutine运行在相同的地址空间,因此访问共享内存必须做好同步。那么goroutine之间如何进行数据的通信呢,Go提供了一个很好的通信机制channel。channel可以与Unix shell 中的双向管道做类比:可以通过它发送或者接收值。这些值只能是特定的类型:channel类型。定义一个channel时,也需要定义发送到channel的值的类型。注意,必须使用make 创建channel:
// 无缓冲的整型通道
unbuffered := make(chan int)
// 有缓冲的字符串通道
buffered := make(chan string, 10)
// 通过通道发送一个字符串
buffered <- "Gopher"
// 从通道接收一个字符串
value := <-buffered
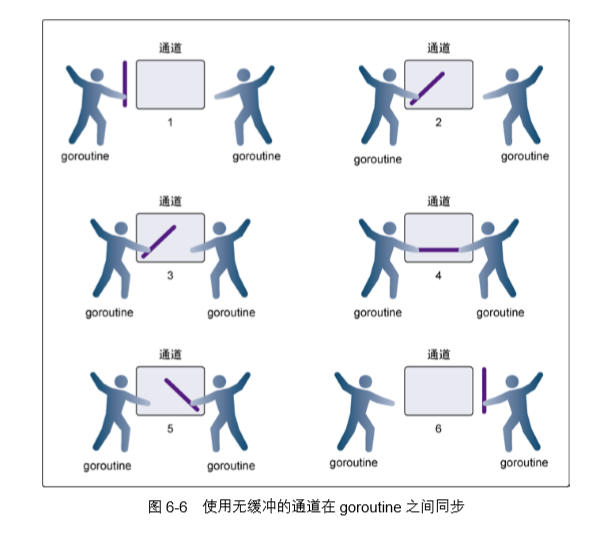
无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。这种类型的通 道要求发送 goroutine 和接收 goroutine 同时准备好,才能完成发送和接收操作。如果两个goroutine 没有同时准备好,通道会导致先执行发送或接收操作的 goroutine 阻塞等待。这种对通道进行发送 和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
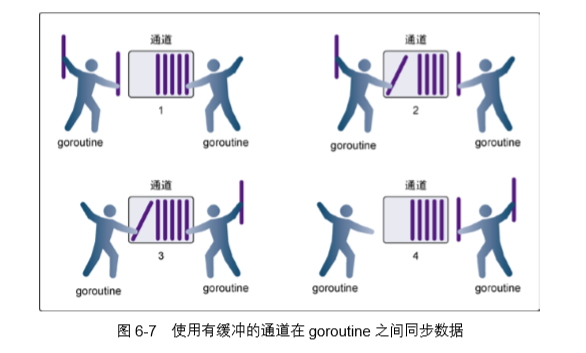
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个值的通道。这种类 型的通道并不强制要求 goroutine 之间必须同时完成发送和接收。通道会阻塞发送和接收动作的 条件也会不同。只有在通道中没有要接收的值时,接收动作才会阻塞。只有在通道没有可用缓冲 区容纳被发送的值时,发送动作才会阻塞。这导致有缓冲的通道和无缓冲的通道之间的一个很大 的不同:无缓冲的通道保证进行发送和接收的 goroutine 会在同一时间进行数据交换;有缓冲的 通道没有这种保证。
Range和Close
Go可以通过range,像操作slice或者map一样操作缓存类型的channel,请看下面的例子
package main
import (
"fmt"
)
func fibonacci(n int, c chan int) {
x, y := 1, 1
for i := 0; i < n; i++ {
c <- x
x, y = y, x + y
}
close(c)
}
func main() {
c := make(chan int, 10)
go fibonacci(cap(c), c)
for i := range c {
fmt.Println(i)
}
}
for i := range c能够不断的读取channel里面的数据,直到该channel被显式的关闭。上面代码我们看到可以显式的关闭channel,生产者通过内置函数close关闭channel。关闭channel之后就无法再发送任何数据了,在消费方可以通过语法v, ok := <-ch测试channel是否被关闭。如果ok返回false,那么说明channel已经没有任何数据并且已经被关闭。
select
我们上面介绍的都是只有一个channel的情况,那么如果存在多个channel的时候,我们该如何操作呢,Go里面提供了一个关键字select,通过select可以监听channel上的数据流动。
select默认是阻塞的,只有当监听的channel中有发送或接收可以进行时才会运行,当多个channel都准备好的时候,select是随机的选择一个执行的。
package main
import "fmt"
func fibonacci(c, quit chan int) {
x, y := 1, 1
for {
select {
case c <- x:
x, y = y, x + y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 10; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
}
在select里面还有default语法,select其实就是类似switch的功能,default就是当监听的channel都没有准备好的时候,默认执行的(select不再阻塞等待channel)。
select {
case i := <-c:
// use i
default:
// 当c阻塞的时候执行这里
}
标准库(JSON,正则)
解码JSON
Go的JSON包中有如下函数
func Unmarshal(data []byte, v interface{}) error
通过这个函数我们就可以实现解析的目的:
package main
import (
"encoding/json"
"fmt"
)
type Server struct {
ServerName string
ServerIP string
}
type Serverslice struct {
Servers []Server
}
func main() {
var s Serverslice
str := `{"servers":[{"serverName":"Shanghai_VPN","serverIP":"127.0.0.1"},{"serverName":"Beijing_VPN","serverIP":"127.0.0.2"}]}`
json.Unmarshal([]byte(str), &s)
fmt.Println(s)
}
有时,无法为 JSON 的格式声明一个结构类型,而是需要更加灵活的方式来处理 JSON 文档。 在这种情况下,可以将 JSON 文档解码到一个map变量中。
// 这个示例程序展示如何解码JSON字符串
package main
import (
"encoding/json"
"fmt"
"log"
)
// JSON包含要反序列化的样例字符串
var JSON = `{
"name": "Gopher",
"title": "programmer",
"contact": {
"home": "415.333.3333",
"cell": "415.555.5555"
}
}`
func main() {
// 将JSON字符串反序列化到map变量
var c map[string]interface{}
err := json.Unmarshal([]byte(JSON), &c)
if err != nil {
log.Println("ERROR:", err)
return
}
fmt.Println("Name:", c["name"])
fmt.Println("Title:", c["title"])
fmt.Println("Contact")
fmt.Println("H:", c["contact"].(map[string]interface{})["home"])
fmt.Println("C:", c["contact"].(map[string]interface{})["cell"])
}
编码JSON
我们开发很多应用的时候,最后都是要输出JSON数据串,那么如何来处理呢?JSON包里面通过Marshal函数来处理,函数定义如下:
func Marshal(v interface{}) ([]byte, error)
假设我们还是需要生成上面的服务器列表信息,那么如何来处理呢?请看下面的例子:
package main
import (
"encoding/json"
"fmt"
)
type Server struct {
ServerName string
ServerIP string
}
type Serverslice struct {
Servers []Server
}
func main() {
var s Serverslice
s.Servers = append(s.Servers, Server{ServerName: "Shanghai_VPN", ServerIP: "127.0.0.1"})
s.Servers = append(s.Servers, Server{ServerName: "Beijing_VPN", ServerIP: "127.0.0.2"})
b, err := json.Marshal(s)
if err != nil {
fmt.Println("json err:", err)
}
fmt.Println(string(b))
}
我们看到上面的输出字段名的首字母都是大写的,如果你想用小写的首字母怎么办呢?把结构体的字段名改成首字母小写的?JSON输出的时候必须注意,只有导出的字段才会被输出,如果修改字段名,那么就会发现什么都不会输出,所以必须通过struct tag定义来实现:
type Server struct {
ServerName string `json:"serverName"`
ServerIP string `json:"serverIP"`
}
type Serverslice struct {
Servers []Server `json:"servers"`
}
struct tag的特殊标记:
- 字段的tag是"-",那么这个字段不会输出到JSON
- tag中如果带有"omitempty"选项,那么如果该字段值为空,就不会输出到JSON串中
type Server struct {
// ID 不会导出到JSON中
ID int `json:"-"`
ServerName string `json:"serverName"`
// 如果 ServerIP 为空,则不输出到JSON串中
ServerIP string `json:"serverIP,omitempty"`
}
s := Server {
ID: 3,
ServerName: `Go "1.0" `,
ServerIP: `192.168.0.1`,
}
b, _ := json.Marshal(s)
os.Stdout.Write(b)
正则
package main
import (
"fmt"
"regexp"
)
func main() {
a := "I am learning Go language"
re, _ := regexp.Compile("[a-z]{2,4}")
//查找符合正则的第一个
one := re.Find([]byte(a))
fmt.Println("Find:", string(one))
//查找符合正则的所有slice,n小于0表示返回全部符合的字符串,不然就是返回指定的长度
all := re.FindAll([]byte(a), -1)
fmt.Println("FindAll", all)
//查找符合条件的index位置,开始位置和结束位置
index := re.FindIndex([]byte(a))
fmt.Println("FindIndex", index)
//查找符合条件的所有的index位置,n同上
allindex := re.FindAllIndex([]byte(a), -1)
fmt.Println("FindAllIndex", allindex)
re2, _ := regexp.Compile("am(.*)lang(.*)")
//查找Submatch,返回数组,第一个元素是匹配的全部元素,第二个元素是第一个()里面的,第三个是第二个()里面的
//下面的输出第一个元素是"am learning Go language"
//第二个元素是" learning Go ",注意包含空格的输出
//第三个元素是"uage"
submatch := re2.FindSubmatch([]byte(a))
fmt.Println("FindSubmatch", submatch)
for _, v := range submatch {
fmt.Println(string(v))
}
//定义和上面的FindIndex一样
submatchindex := re2.FindSubmatchIndex([]byte(a))
fmt.Println(submatchindex)
//FindAllSubmatch,查找所有符合条件的子匹配
submatchall := re2.FindAllSubmatch([]byte(a), -1)
fmt.Println(submatchall)
//FindAllSubmatchIndex,查找所有字匹配的index
submatchallindex := re2.FindAllSubmatchIndex([]byte(a), -1)
fmt.Println(submatchallindex)
}
go连接mysql
package main
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
)
func main() {
// 格式:用户名:密码@tcp(主机:端口号)/数据库?charset=utf8
testCon := ""
db, err := sql.Open("mysql", testCon)
if err != nil {
fmt.Println(err)
}
defer db.Close()
sql := ""
rows, err := db.Query(sql) //执行sql
if err != nil {
fmt.Println(err)
}
}
参考资料
本文大部分内容来自这两本书
《Go Web 编程》 谢孟军 著
国内go web开发框架beego作者
github:build-web-application-with-golang
《Go In Action》 Go语言实战
[美] 威廉·肯尼迪(William,Kennedy)
布赖恩·克特森(Brian,Ketelsen)
埃里克·圣马丁(Erik,St.Martin) 著
李兆海 译
爬虫
go 简单爬虫 - Go语言中文网 - Golang中文社区
Creeper首页、文档和下载 - Go 版本开源爬虫框架 - 开源中国社区
实现一个go语言的简单爬虫来爬取CSDN博文(一) - Go语言中文网 - Golang中文社区
golang语言中发起http请求 - Go语言中文网 - Golang中文社区
语言
go语言指针符号的*和& - Go语言中文网 - Golang中文社区
Centos7安装Golang1.6,并配置vim环境 - Go语言中文网 - Golang中文社区
GO语言练习:channel 工程实例 - Go语言中文网 - Golang中文社区
Go 语言从新手到大神:每个人都会踩的五十个坑 (1-12) - 大舒的博客 - SegmentFault
Go语言标准库文档中文版 | Go语言中文网 | Golang中文社区 | Golang中国
Go语言实战笔记(八)| Go 函数方法 | 飞雪无情的博客
golang 中regexp包用法 - Go语言中文网 - Golang中文社区
Web开发
beego 简介 - beego: 简约 & 强大并存的 Go 应用框架
Welcome to Revel, the Web Framework for Go!
一文读懂Go的net/http标准库 - Go语言中文网 - Golang中文社区
go语言JSON处理 - liukuan73的专栏 - CSDN博客
在Go语言中使用JSON - 杨理垚的技术专栏 - CSDN博客
其他
Surfer 高并发双核无头浏览器 (Golang语言) - 默小文 - 博客园
build-web-application-with-golang/preface.md at master astaxie/build-web-application-with-golang