1、使用scrapy_redis分布式爬取全国658城市房源信息
打开房天下网,进入全国658房页面:http://www.fang.com/SoufunFamily.htm

分析发现,所有省份/城市是存于一个table标签内,一个tr标签是上面中的一行数据。
我们要爬取的是新房及二手房信息,需要处理的:
1、北京的新房/二手房,跟其他城市的新房/二手房不一样 ,因为北京被默认为首城市,在新房/二手房的url中是没有带城市拼音字段的,而其他城市的都有,如下:
北京:二手房 → http://esf.fang.com/
新房 → http://newhouse.fang.com/house/s/
其他城市:如广州二手房:http://gz.esf.fang.com (带有gz字样)
新房:http://gz.newhouse.fang.com/house/s/
2、在上述tr标签中,每个一行,在省份的位置数据是为空的,这个也需要处理
3、我们从table中获取到的每个城市的url链接都类似这样:http://wuhu.fang.com/ ,我们需要跟据新房/二手房的url特征拼凑成新房/二手房的正确url
4、最后一行省份署名为‘其它’,这是海外的房源信息,我们不爬取,在代码中也需要将其排除。具体实现如下:
import scrapy import re class FangtianxiaSpider(scrapy.Spider): name = 'fangtianxia' allowed_domains = ['fang.com'] start_urls = ['http://www.fang.com/SoufunFamily.htm'] def parse(self, response): trs = response.css("#c02 > .table01 tr") province = None for tr in trs: tds = tr.xpath(".//td[not(@class)]") province_td = tds[0] # 省份的标签 province_text = province_td.xpath(".//text()").get("") # 获取省份的内容 province_text = re.sub(r"s","",province_text) # 将空格替换成空 if province_text: # 如果为true,表示保存的是个省份 province = province_text if province == '其它': # 不爬取海外的房源 continue city_td = tds[1] city_links = city_td.xpath(".//a") # 省份下面的所有a标签,存有多个市 for city_link in city_links: city = city_link.xpath(".//text()").get('') # 城市名称 city_url = city_link.xpath(".//@href").get('') # 城市对应的链接 http://bj.fang.com/ # 构建新房/二手房链接 scheme,domains = city_url.split("//") domain = domains.split('.',1)[0] if "bj." in domains: # 如果是北京的新房/二手房链接,直接用下面的url newhouse_url = "http://newhouse.fang.com/house/s/" esf_url = "http://esf.fang.com/" else: # 构建新房的url链接 http://gz.newhouse.fang.com/house/s/ newhouse_url = scheme + '//' + domain + '.newhouse.fang.com/house/s/' # 构建二手房的url链接 http://gz.esf.fang.com/ esf_url = scheme + '//' + domain + '.esf.fang.com/' print("省份:",province) print("城市:",city) print("新房url:",newhouse_url) print("二手房url:",esf_url)
运行结果:
 →→→
→→→ 
上面已经构建好新房/二手房url链接,但在实际操作中,北京二手房链接会重定向到你所在城市的二手房链接,如下。目前还未找到方法解决这个问题,只能暂时剔除掉北京二手房源数据的爬取

** 在开始新房/二手房房源数据分析及爬取前,需要先设置随机user-agent。实现代码如下:
1)安装:pip install fake-useragent
2)settings.py中配置:
DOWNLOADER_MIDDLEWARES = { # 'fantianxia.middlewares.FantianxiaDownloaderMiddleware': 543, 'fantianxia.middlewares.RandomUserAgentMiddlware': 100, 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, # 将scrapy useragent设置为Nome,使用我们自定义的随机user-agent } RANDOM_UA_TYPE = "random" # 用于download middleware中选择随机user-agent的方式
3)middlewares.py中新建类:RandomUserAgentMiddlware ,代码实现:
from fake_useragent import UserAgent # 引入fake-useragent的UserAgent class RandomUserAgentMiddlware(object): #随机更换user-agent def __init__(self, crawler): super(RandomUserAgentMiddlware, self).__init__() self.ua = UserAgent() # 实例化UserAgent self.ua_type = crawler.settings.get("RANDOM_UA_TYPE", "random") # 从setting中获取useragent的类型(Firefox、Chrome、IE或random) @classmethod def from_crawler(cls, crawler): return cls(crawler) def process_request(self, request, spider): def get_ua(): return getattr(self.ua, self.ua_type) # 根据setting中获取的useragent类型,映射真正方法 request.headers.setdefault('User-Agent', get_ua()) # 添加到headers中
** 新房房源数据爬取实现代码:
def parse_newhouse(self,response): province,city = response.meta.get('info') try: # 可能某些城市并没有新房或二手房的房源信息,这种pass不处理 lis = response.xpath("//div[contains(@class,'nl_con')]/ul/li[not(@id)]" and "//div[contains(@class,'nl_con')]/ul/li[not(@class)]") for li in lis: name = li.xpath(".//div[@class='nlcd_name']/a/text()").get() if not name: # 如果匹配不到名称,说明是广告 continue name = name.strip() rooms = "/".join(li.xpath(".//div[contains(@class,'house_type')]/a/text()").getall()) area = "".join(li.xpath(".//div[contains(@class,'house_type')]/text()").getall()) area = re.sub(r"s|-|/","",area) address = li.xpath(".//div[@class='address']/a/@title").get().replace(",","-") district_text = "".join(li.xpath(".//div[@class='address']/a//text()").getall()) try: district = re.search(r".*[(.+)].*",district_text).group(1) except: district = None sale = li.xpath(".//div[contains(@class,'fangyuan')]/span/text()").get() price = "".join(li.xpath(".//div[@class='nhouse_price']//text()").getall()) price = re.sub(r"s|广告",'',price) origin_url = li.xpath(".//div[@class='nlcd_name']/a/@href").get("") url = response.urljoin(origin_url) img = li.xpath(".//div[@class='nlc_img']/a/img[2]/@src").get("") img = response.urljoin(img) # print(img) item = NewHouseItem(province=province,city=city,name=name,price=price,rooms=rooms,area=area,address=address, district=district,sale=sale,origin_url=url,img=img ) yield item next_url = response.xpath("//a[@class='next']/@href").get() # 下一页 if next_url: yield scrapy.Request(url=response.urljoin(next_url),callback=self.parse_newhouse,meta={"info":(province,city)}) except: pass
** 二手房房源数据爬取实现代码:
def parse_esf(self,response): province, city = response.meta.get('info') try: dls = response.xpath("//div[contains(@class,'shop_list')]/dl[@dataflag]") for dl in dls: info_list = [] item = ESFHouseItem(province=province,city=city) item['name'] = dl.xpath(".//p[@class='add_shop']/a/@title").get() infos =dl.xpath(".//p[@class='tel_shop']/text()").getall() infos = list(map(lambda x:re.sub(r"s","",x),infos)) item['rooms'] = None item['floor'] = None item['toward'] = None item['area'] = None item['year'] = None for info in infos: if "室" in info: item['rooms'] = info elif "层" in info: item['floor'] = info elif "向" in info: item['toward'] = info elif "年" in info: item['year'] = info elif "㎡" in info: item['area'] = info item['address'] = dl.xpath(".//p[@class='add_shop']//span/text()").get().replace(",","-") item['price'] = "".join(dl.xpath(".//dd[@class='price_right']/span[1]//text()").getall()) item['unit'] = "".join(dl.xpath(".//dd[@class='price_right']/span[2]//text()").getall()) detail_url = dl.xpath(".//h4[@class='clearfix']/a/@href").get() item['origin_url'] = response.urljoin(detail_url) yield item next_url = response.xpath("//div[@class='page_al']//p[1]/a/@href").get() yield scrapy.Request(url=response.urljoin(next_url),callback=self.parse_esf,meta={"info":(province,city)}) except: pass
item.py代码:
class NewHouseItem(scrapy.Item): province = scrapy.Field() # 省份 city = scrapy.Field() # 城市 name = scrapy.Field() # 小区名称 price = scrapy.Field() # 价格 rooms = scrapy.Field() # 几居,列表类型 area = scrapy.Field() # 面积 address = scrapy.Field() # 地址 district = scrapy.Field() # 行政区 sale = scrapy.Field() # 是否在售 origin_url = scrapy.Field() #房天下每个城市每个小区的详情页url img = scrapy.Field() # 封面图 class ESFHouseItem(scrapy.Item): province = scrapy.Field() # 省份 city = scrapy.Field() # 城市 name = scrapy.Field() # 小区名称 rooms = scrapy.Field() #几室几厅 floor = scrapy.Field() # 层 toward = scrapy.Field() # 朝向 year = scrapy.Field() # 年代 address = scrapy.Field() # 地址 area = scrapy.Field() # 建筑面积 price = scrapy.Field() # 总价 unit = scrapy.Field() # 单价 origin_url = scrapy.Field() # 原始url
pipelines.py实现数据保存到csv文件中:
import codecs class FangPipeline(object): def __init__(self): self.newHouse_fp = codecs.open("新房源信息.csv",'w',encoding='utf-8') self.esfHouse_fp = codecs.open("二手房源信息.csv",'w',encoding='utf-8') self.newHouse_fp.write("省份,城市,小区,价格,几居,面积,地址,行政区,是否在售,origin_url,封面图url ") self.esfHouse_fp.write("省份,城市,小区,几室几厅,层,朝向,年代,地址,建筑面积,总价,单价,origin_url ") def process_item(self, item, spider): if 'floor' not in item: self.newHouse_fp.write("{},{},{},{},{},{},{},{},{},{},{} ".format(item['province'],item['city'],item['name'],item['price'],item['rooms'], item['area'],item['address'],item['district'],item['sale'],item['origin_url'],item['img']) ) else: self.esfHouse_fp.write("{},{},{},{},{},{},{},{},{},{},{},{} ".format(item['province'], item['city'], item['name'], item['rooms'], item['floor'], item['toward'], item['year'], item['address'], item['area'], item['price'], item['unit'],item['origin_url']) ) return item
settings.py中配置pipeline:
ITEM_PIPELINES = { 'fantianxia.pipelines.FangPipeline': 100, }
fangtianxia.py完整代码:


import scrapy import re from items import NewHouseItem,ESFHouseItem class FangtianxiaSpider(scrapy.Spider): name = 'fangtianxia' allowed_domains = ['fang.com'] start_urls = ['http://www.fang.com/SoufunFamily.htm'] def parse(self, response): trs = response.css("#c02 > .table01 tr") province = None for tr in trs: tds = tr.xpath(".//td[not(@class)]") province_td = tds[0] # 省份的标签 province_text = province_td.xpath(".//text()").get("") # 获取省份的内容 province_text = re.sub(r"s","",province_text) # 将空格替换成空 if province_text: # 如果为true,表示保存的是个省份 province = province_text if province == '其它': # 不爬取海外的房源 continue city_td = tds[1] city_links = city_td.xpath(".//a") # 省份下面的所有a标签,存有多个市 for city_link in city_links: city = city_link.xpath(".//text()").get('') # 城市名称 city_url = city_link.xpath(".//@href").get('') # 城市对应的链接 http://bj.fang.com/ # 构建新房/二手房链接 scheme,domains = city_url.split("//") domain = domains.split('.',1)[0] if "bj." in domains: # 如果是北京的新房/二手房链接,直接用下面的url newhouse_url = "http://newhouse.fang.com/house/s/" esf_url = "http://esf.fang.com/" # print("省份:", province) # print("城市:", city) # print("新房url:", newhouse_url) # print("二手房url:", esf_url) else: # 构建新房的url链接 http://gz.newhouse.fang.com/house/s/ newhouse_url = scheme + '//' + domain + '.newhouse.fang.com/house/s/' # 构建二手房的url链接 http://gz.esf.fang.com/ esf_url = scheme + '//' + domain + '.esf.fang.com/' # print("省份:",province) # print("城市:",city) # print("新房url:",newhouse_url) # print("二手房url:",esf_url) yield scrapy.Request(url=newhouse_url,callback=self.parse_newhouse,meta={"info":(province,city)}) if esf_url == 'http://esf.fang.com/': # 北京url,重定向问题,未解决 continue yield scrapy.Request(url=esf_url,callback=self.parse_esf,meta={"info":(province,city)}) # break # break def parse_newhouse(self,response): province,city = response.meta.get('info') try: # 可能某些城市并没有新房或二手房的房源信息,这种pass不处理 lis = response.xpath("//div[contains(@class,'nl_con')]/ul/li[not(@id)]" and "//div[contains(@class,'nl_con')]/ul/li[not(@class)]") for li in lis: name = li.xpath(".//div[@class='nlcd_name']/a/text()").get() if not name: # 如果匹配不到名称,说明是广告 continue name = name.strip() rooms = "/".join(li.xpath(".//div[contains(@class,'house_type')]/a/text()").getall()) area = "".join(li.xpath(".//div[contains(@class,'house_type')]/text()").getall()) area = re.sub(r"s|-|/","",area) address = li.xpath(".//div[@class='address']/a/@title").get().replace(",","-") district_text = "".join(li.xpath(".//div[@class='address']/a//text()").getall()) try: district = re.search(r".*[(.+)].*",district_text).group(1) except: district = None sale = li.xpath(".//div[contains(@class,'fangyuan')]/span/text()").get() price = "".join(li.xpath(".//div[@class='nhouse_price']//text()").getall()) price = re.sub(r"s|广告",'',price) origin_url = li.xpath(".//div[@class='nlcd_name']/a/@href").get("") url = response.urljoin(origin_url) img = li.xpath(".//div[@class='nlc_img']/a/img[2]/@src").get("") img = response.urljoin(img) # print(img) item = NewHouseItem(province=province,city=city,name=name,price=price,rooms=rooms,area=area,address=address, district=district,sale=sale,origin_url=url,img=img ) yield item next_url = response.xpath("//a[@class='next']/@href").get() # 下一页 if next_url: yield scrapy.Request(url=response.urljoin(next_url),callback=self.parse_newhouse,meta={"info":(province,city)}) except: pass def parse_esf(self,response): province, city = response.meta.get('info') try: dls = response.xpath("//div[contains(@class,'shop_list')]/dl[@dataflag]") for dl in dls: info_list = [] item = ESFHouseItem(province=province,city=city) item['name'] = dl.xpath(".//p[@class='add_shop']/a/@title").get() infos =dl.xpath(".//p[@class='tel_shop']/text()").getall() infos = list(map(lambda x:re.sub(r"s","",x),infos)) item['rooms'] = None item['floor'] = None item['toward'] = None item['area'] = None item['year'] = None for info in infos: if "室" in info: item['rooms'] = info elif "层" in info: item['floor'] = info elif "向" in info: item['toward'] = info elif "年" in info: item['year'] = info elif "㎡" in info: item['area'] = info item['address'] = dl.xpath(".//p[@class='add_shop']//span/text()").get().replace(",","-") item['price'] = "".join(dl.xpath(".//dd[@class='price_right']/span[1]//text()").getall()) item['unit'] = "".join(dl.xpath(".//dd[@class='price_right']/span[2]//text()").getall()) detail_url = dl.xpath(".//h4[@class='clearfix']/a/@href").get() item['origin_url'] = response.urljoin(detail_url) yield item next_url = response.xpath("//div[@class='page_al']//p[1]/a/@href").get() yield scrapy.Request(url=response.urljoin(next_url),callback=self.parse_esf,meta={"info":(province,city)}) except: pass
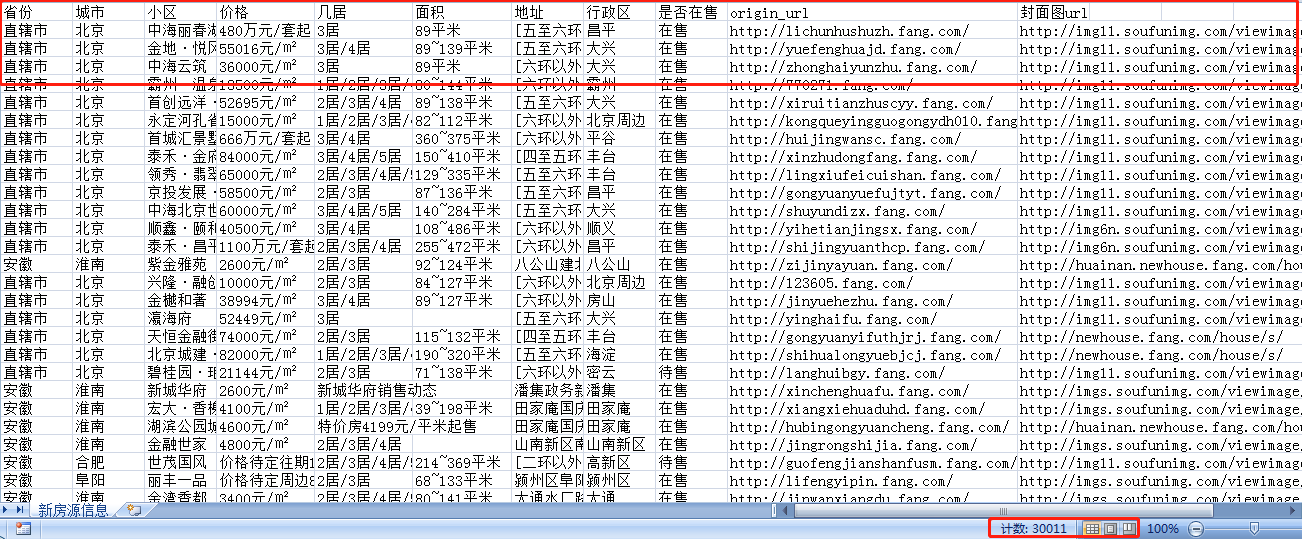
至此,简单版的房天下新房/二手房房源数据爬取及持久化便完成了。运行项目,打开csv文件,可以发现(中间手动停止运行):
新房房源数据成功爬取3万多条数据,二手房房源数据成功爬取接近4万条数据

** 将我们上述项目改造成scrapy-redis分布式爬虫项目
1、安装:pip install scrapy-redis
2、fangtianxia.py代码改动:
from scrapy_redis.spiders import RedisSpider class FangtianxiaSpider(RedisSpider): # 继承RedisSpider name = 'fangtianxia' allowed_domains = ['fang.com'] # start_urls = ['http://www.fang.com/SoufunFamily.htm'] # 注释掉 redis_key = "fang:start_url" # 从redis中推入
3、settings.py配置:
# 使用scrapy-redis里的去重组件,不使用scrapy默认的去重方式 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis里的调度器组件,不使用默认的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 允许暂停,redis请求记录不丢失 SCHEDULER_PERSIST = True REDIS_HOST = "192.168.1.145" # 指定数据库的端口号 REDIS_PORT = 6379 REDIS_PARAMS = { 'password': 'nan****', } ITEM_PIPELINES = { # 'fantianxia.pipelines.FangPipeline': 100, 'scrapy_redis.pipelines.RedisPipeline': 110, }
4、进入我们项目的虚拟环境中,再进入爬虫所在的路径,需要注意的是:
1)爬虫的执行文件命名为与项目名称不同的名字,本项目重命名为sfw.py
2)从终端进入爬虫所在路径运行爬虫时,如果报错找不到某些模块,则需要添加模块路径到我们的执行文件中:
# sfw.py文件下 import os,sys BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.insert(0,BASE_DIR) from items import NewHouseItem,ESFHouseItem # 报错:items模块未找到
路径:
上述问题解决后,我们开始运行爬虫文件:
scrapy runspider sfw.py
看到爬虫项目运行起来,并在等待我们的start_url输入时,再在redis-cli客户端推入我们的start_url:
lpush fang:start_url http://www.fang.com/SoufunFamily.htm
至此,scrapy-redis分布式爬虫项目,我们就算完成了。
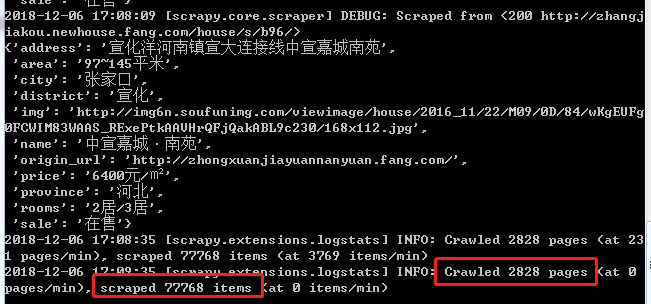
查看运行结果:
共爬取了2828页,77768个item数据
从csv数据得知,共爬取二手房数据接近60万数据,共爬取新房数据30来万条数据