声明
以下内容涉及的平台是我朋友的平台,另外也不存在攻击破解拿商业数据等行为,为了安全着想,部分信息已打码
前言
我朋友给了我一个网站,说他们内部测试用的,要我看下有没有办法爬数据,也就是他们的搜索接口能搞不,这已经是我做反爬开始的第n个爬虫等级测试了
分析
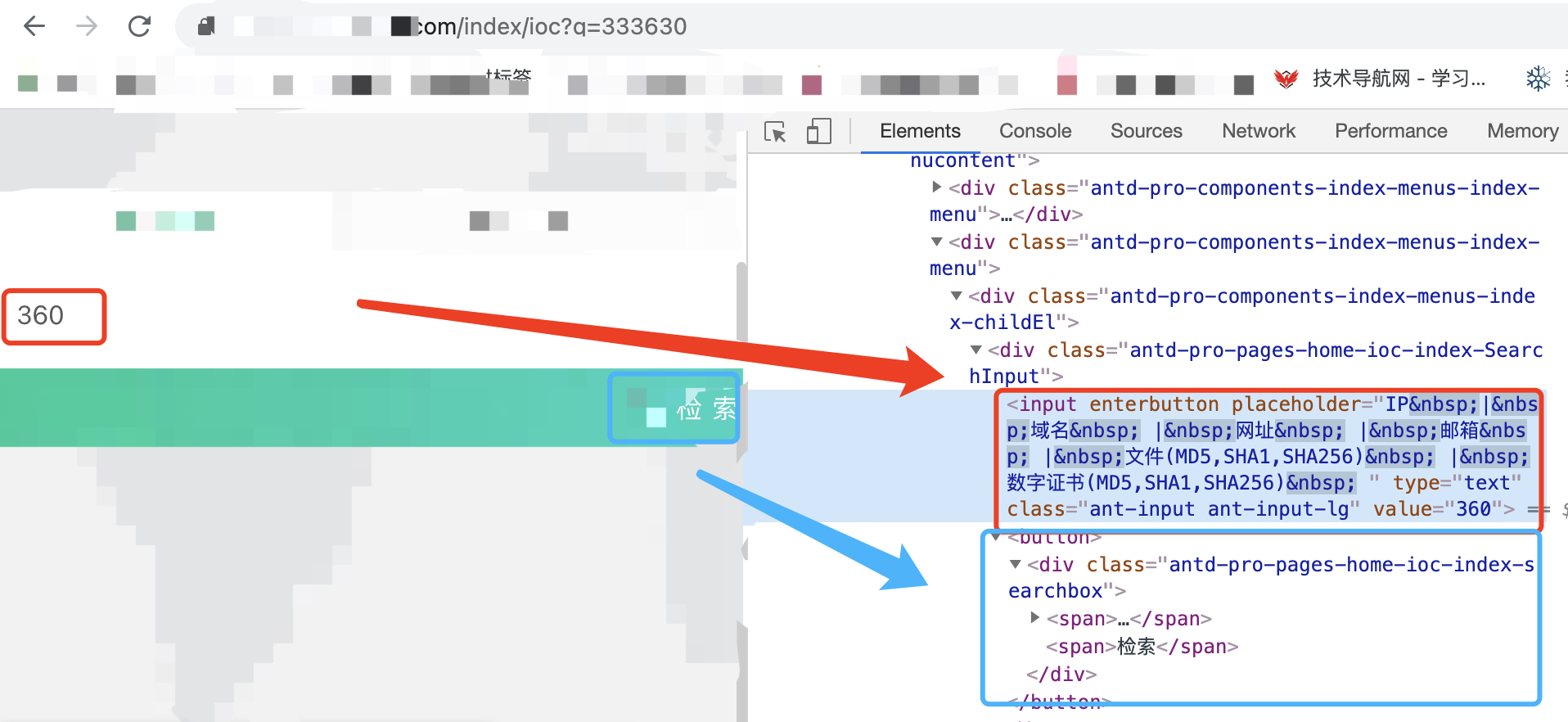
习以为常的打开网站,然后就看到下面的界面:


看到了嘛,我填入关键词搜索的时候,url直接就变成了https://xxxxxx.com/index/ioc?q=333630(注意这个网址,如果老手的话,一开始就从这里下手了,此时的话,我就从一开始的逻辑开始一步一步往下吧)
也就是说此时此刻,【360】被转成了【333630】,有点意思哈,其实这种的我之前就遇到过,不过为了阐述清楚,我还是从头开始展示我的思路,怎么发现,然后怎么解决的。当然,对于js逆向大佬看这篇文章可就太简单了,那可不,我朋友这平台连js代码混淆都没做的,我都还没用上AST呢
继续哈,看他的网站源码,
浏览器自带的抓包工具里也只是直接调用了一个异步请求拿到返回结果而已: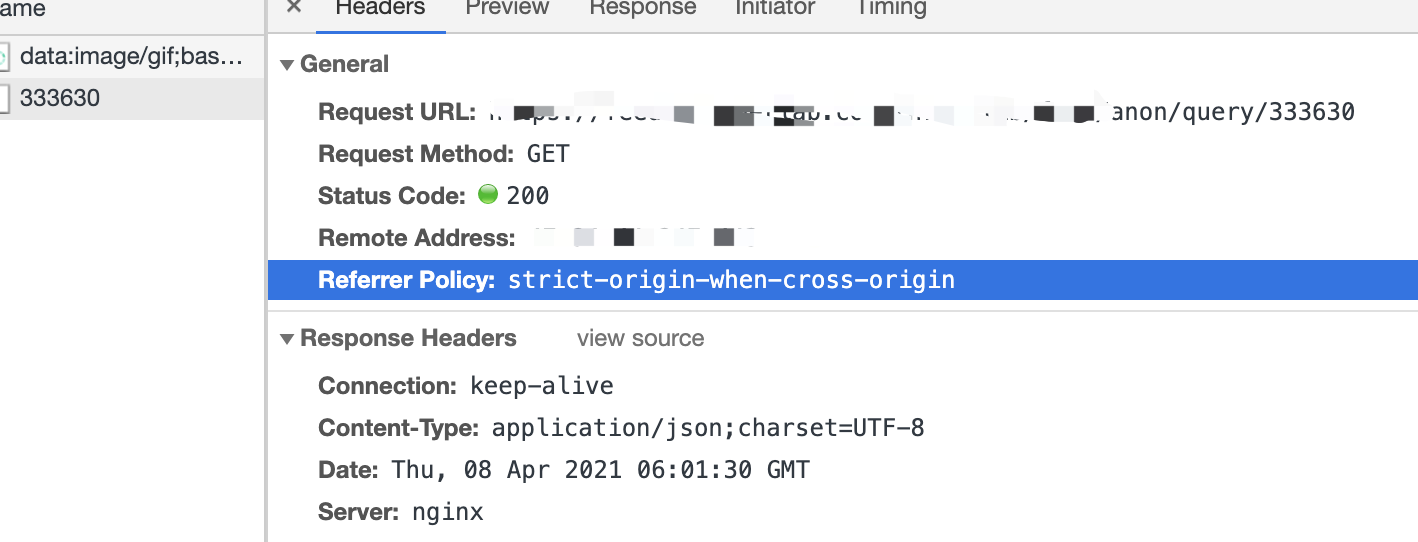
并没有发现很奇特的请求,也没有做重定向跳转去中间站获取该值再请求,
找到关键点
那么,多次测试后我得出结论,一定是js生成的。那既然是js生成的话,那就一定有一个触发时间去转输入框里输入的值,根据我上面分析的网站源码,那就只有一种了,当我点击【检索】按钮搜索的时候,触发了一个js事件去转译或者说编译我输入的值
js调试
那么就进入js调试了,先全文检索这个异步请求接口:

只有一个文件,点进去再格式化:

然后等了好半天才出来,发现js文件并未做混淆,那就好办了,打上断点,顿时发现,卧槽19万行代码,这文件有点大啊,难怪加载这么久:

换个词点击搜索再看看js的堆栈跳转:

一步一步走的时候,还没走几步就发现跳到以下函数里,而且发现,卧槽,这转码都已完成了:

重新再找,刷新网页重新打开,然后发现这个umi.js文件太大了又在加载,我索性把它保存到本地慢慢看,我整理了下文件,卧槽,这。。。。。。

这也太大了,而且这函数命名都是些啥呀,完全看不懂了,突然给我带来了压力,卧槽了。。。。。。
这时我那朋友给我发了个消息,问我咋样了,他顺便还带了个表情,略带嘲讽含义,这让我又心情又多了一分焦虑
对于js逆向不太熟悉的老哥,可能到这里就想放弃了,这么多东西啊,好多看不懂啊,老手也是从新手起来的,慢慢来,别急,就算搞不定,研究下是卡在哪里,然后去补这方面的知识也可以的啊,就当是涨涨见识了,我搜了下这个umi.js相关的文章

有关umi.js相关的文章,感兴趣的可以研究下,反正我看了半天没看太懂
https://www.yuque.com/yangwei-uovk8/tmuage/nko7f9
https://www.jianshu.com/p/dc493809a2fd
https://www.jianshu.com/p/0c944d58a08e
反正目前知道的就是这个umi是配合react使用的,我又用这两个class属性名去搜下,根据我的经验,它绑定触发时间要嘛通过lei名绑定,要嘛sumbit常规绑定,要嘛就内层冒泡事件啥的,额,咳咳,小弟不才,也曾玩过vue,既然这个是react,那么也有类似的地方
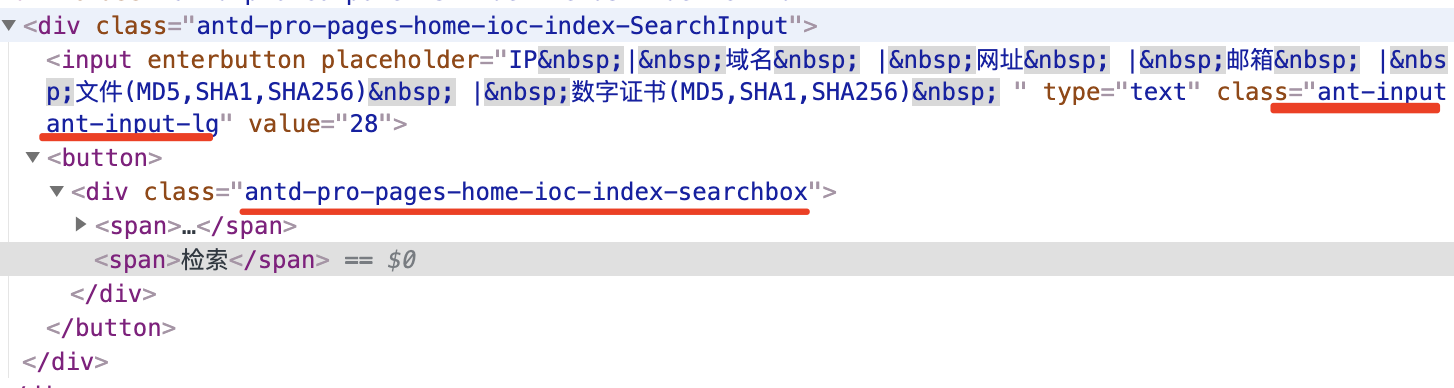
然后就找到下面这段代码,卧槽,这,着实没看太懂这是是在干嘛
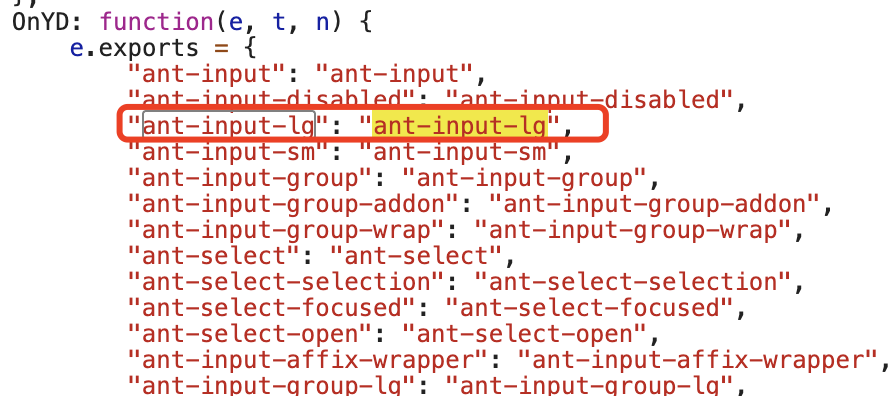

拿到这两个函数名:【/X86】和【OnYD】,看着是非常的不舒服,接着往上找:

用【QN4V】找到了这个路由:【/index/ioc】,卧槽,这不就是该页的url地址吗,找了半天呢,就是url,那么也从侧面说明找对了。我上面也说了,老手的话,一开始就会从这里入手吧,而就算一开始没入手,找anon/query/没找到时,立马就会转而找这个路由

而且它这中文也确实是前面网站源码里面看到的

继续用【OnYD】找到【5NDa】:

再用【5NDa】找,这个结果就有点多了,算了
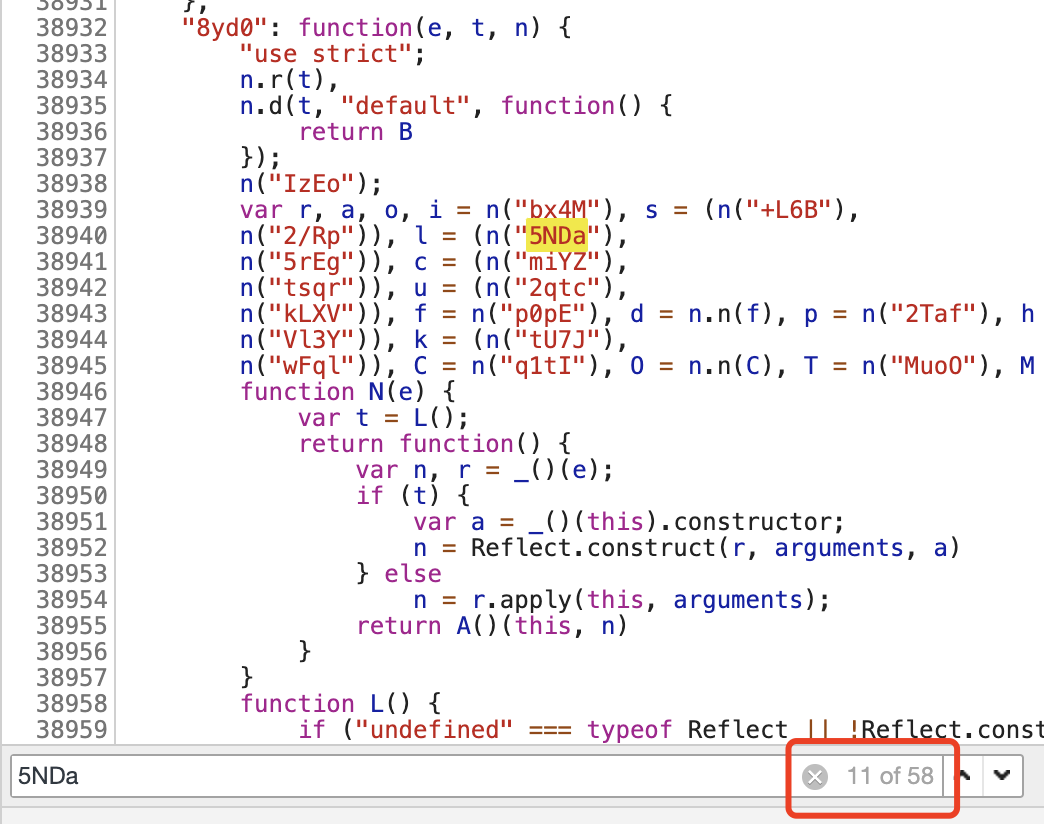
那就用 【index/ioc】搜下查看:

去除一些无用的定义:

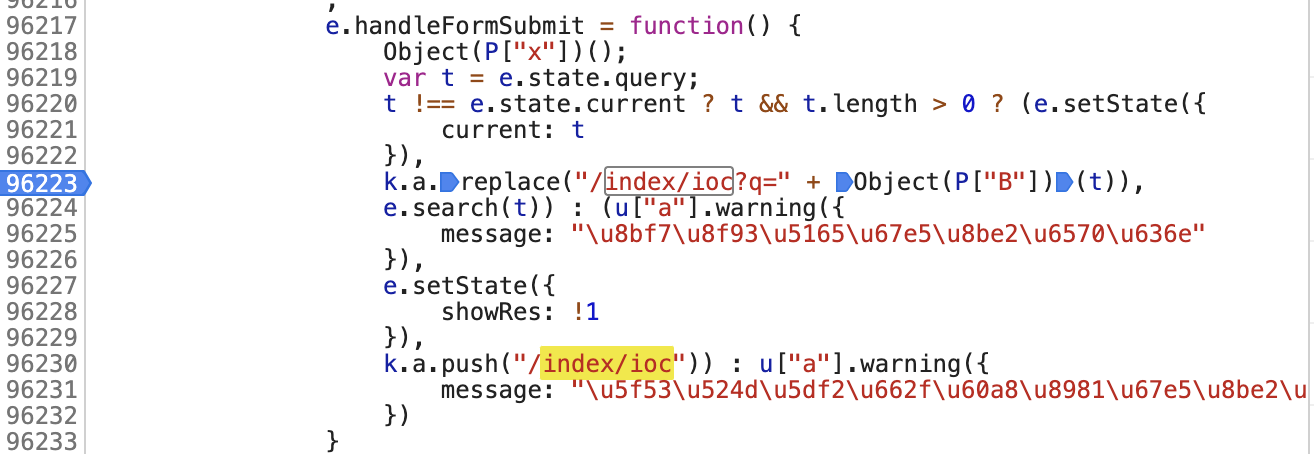


再看看链接:

从上面这几个筛选出以下几个:跟链接最像的就是以下三个了:
e.doSearch = function(t) {
var n = e.props.history;
t && n.push("/index/ioc?q=" + Object(Lt["B"])(t))
}
k.a.replace("/index/ioc?q=" + Object(P["B"])(t)),
e.search(t)) : (u["a"].warning({
message: "u8bf7u8f93u5165u67e5u8be2u6570u636e"
})
key: "goSearch",
value: function(e) {
e && (Object(P["x"])(),
k.a.replace("/index/ioc?q=" + Object(P["B"])(e)),
this.search(e),
this.setState({
query: e
}))
}
一个一个来,用doSearch打断点测试看:没断上,直接就过去了,


换这个,同样的,没断上直接过去了

再换这个,找对了,断上了,同时,看这个名字handleFormSubmit,我上面说了,对submit的监听触发,这个名字看着就像是对submit的监听,老手的话,从上面的三个函数里面,直接就先测试这个


关键代码
是的,关键代码就是这个B函数,我又换个搜索词汇:【28】

function B(e) {
if ("" === e)
return "";
for (var t = [], n = 0; n < e.length; n++)
t.push(e.charCodeAt(n).toString(16));
return t.join("")
}
测试
前端console测试:
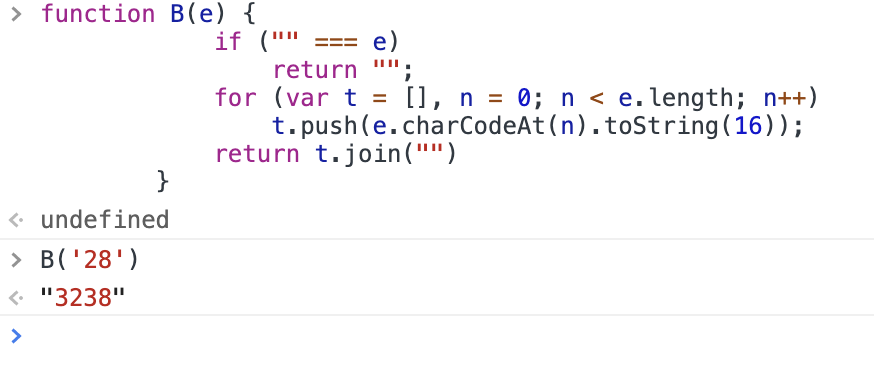
验证,没问题
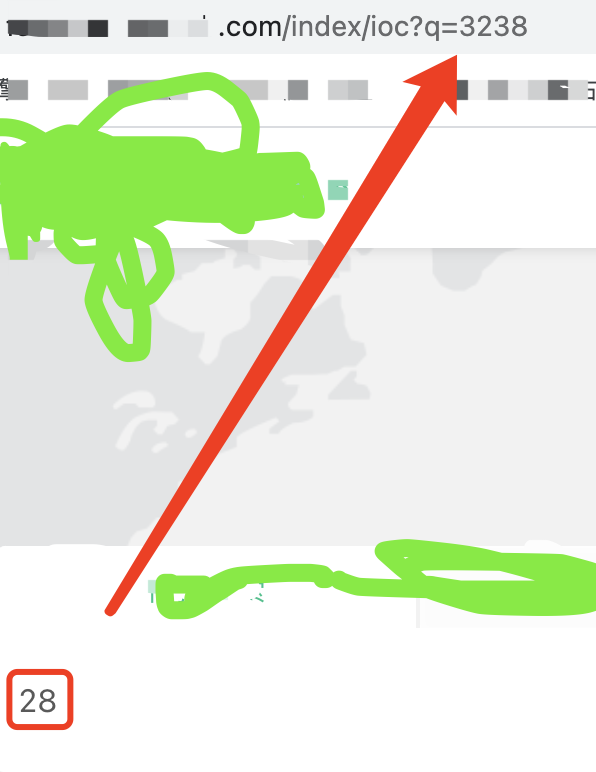
python实现
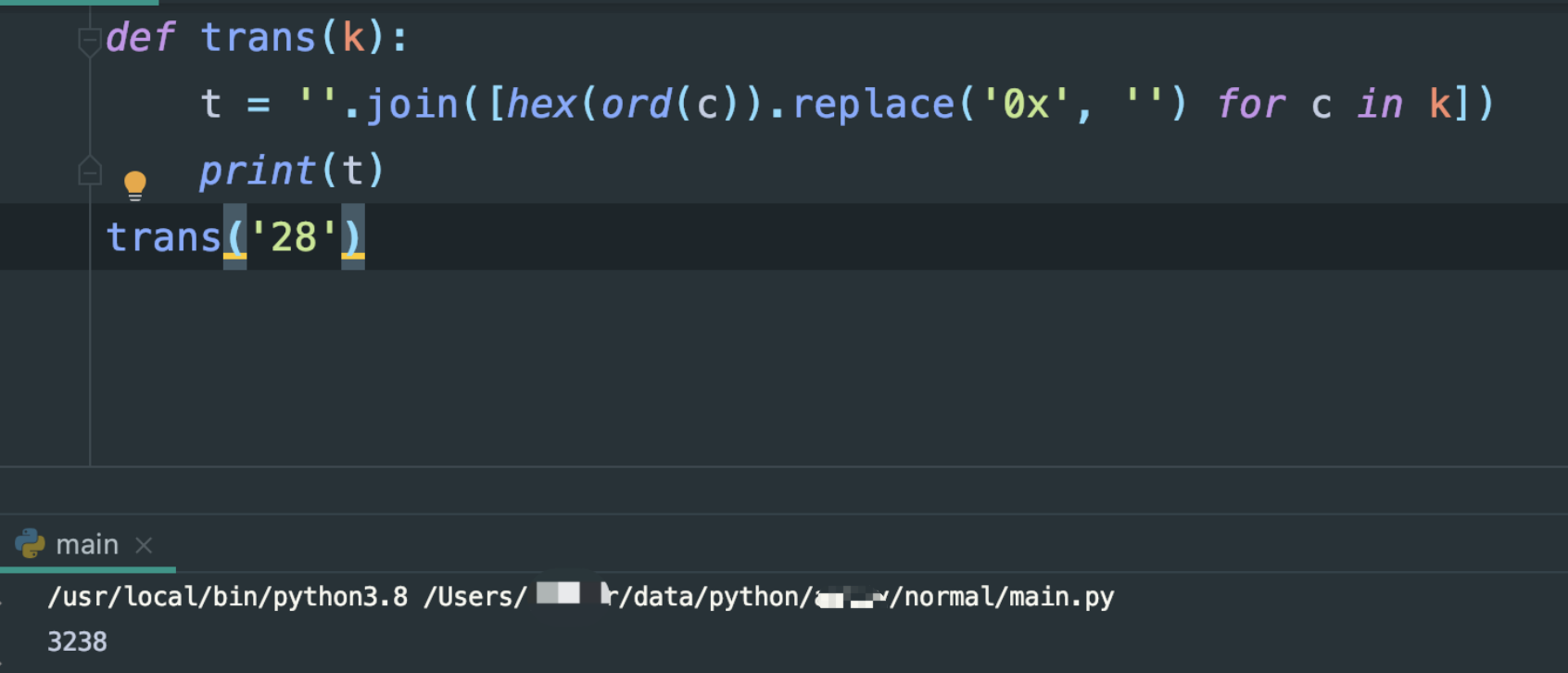
结果能对上,换中文看看:
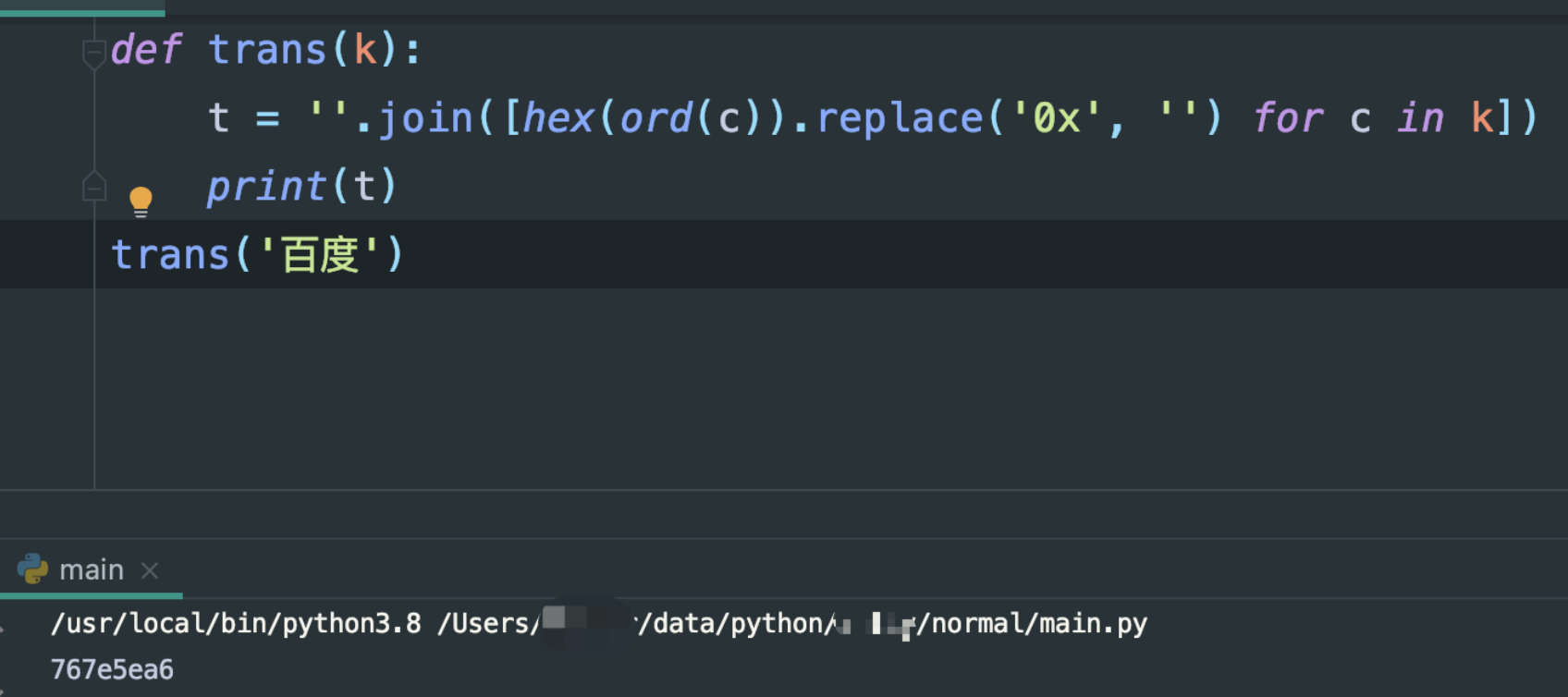
结果却是能对上的

那说明没有问题
代码:
def trans(k):
t = ''.join([hex(ord(c)).replace('0x', '') for c in k])
print(t)
trans('百度')
另外补充下,如果你实在没找到用python实现的方法的话,直接用execjs或者js2py调用js源码也可以的。
接下来就可以把想搜索的词汇先调用trans函数转义之后直接去请求接口 : https://xxxxxxxx.com/xxxxxxxxx/anon/query/{word},拿想拿的数据了
接着我跟我那朋友一说,他有点激动,有点诧异,回了句,“你用了几行代码解决的”,我说,“4行”,紧跟着就是一顿文雅的商业互捧,然后再给了他一些反爬方案,他拿着方案回去邀功了
结论
其实,从头到尾,看起来难吗?其实不算难的,最前面我就说了,都还没上AST,js的源码都没混淆,直接可读,就是代码长了点,百万行,当然,我这里也不是以俯视的角度看待新手朋友们,因为我自知我也不是大佬,也就闲暇时候分析分析,学点东西而已,而且我一开始的逻辑思路就是以新手的角度来的,目的就是希望各位朋友能看得更通透些。
另外,以后如果再遇到这种类似网站,可以更直接点的,直接搜索【charCodeAt】看有没有结果,可以一针见血的找到关键点
再者,提一句,现在搞爬虫或者反爬,可是啥都要会啊,js要会,安卓逆向要会,ios也要会,光是js确实难道了好大一批朋友们,而相信有些朋友如果这时候碰巧在找工作的话,我相信你绝对看到好多公司招爬虫得要会安卓逆向的吧,因为现在,很多平台逐渐的把重心移到移动端转而放弃pc端,那么安卓和ios和h5端,现在一定是大头,而目前,就光是一个脱壳和代码混淆就能难倒一片(有关怎么学习安卓逆向这里就暂且不表了,感兴趣的可以自行研究),另外既然安卓都有了,那ios逆向也不远了,所以,ios开发估计也得提上日程了,ios越狱啥的也得会了,有朋友要问了,搞逆向为啥还要会开发啊,不浪费宝贵时间吗?道理是这样,但是,你正向开发都不会,搞逆向是很吃力的,当然也不是说完全不行,看个人能力和天赋了。
所以啊,要搞爬虫可不是那么容易啊,啥都得会啊,以前搞爬虫得要会人工智能建模,现在安卓和ios也加上来了,而且有些公司还要求要会Windows端的反编译,卧槽,这也是一座大山。以后还要会什么就更不知道了。新手们,别急慢慢来,我也会是不是的更新下文章,分享,不设门槛,不收费,同时我也希望大家有好的思路或者方法可以分享,共同进步
最后,有眼熟的朋友如果认出了这个平台,请不要在评论区给出地址,秉着不公开的原则,我看到会删除,之前在破解AES和DES加密的时候就有朋友来评论把网址给出来了,你把网址发出来你知道这意味着什么吗?不多说了,后果自负哈