Introduction to Computer Networking是Stanford的网络课,据说lab质量很高,就把它作为转System后的第一个小系统吧!
准备工作
Stanford大气!能让我们这些野鸡学校的同学接触到最顶级的教育资源,甚至开放了lab,也希望大伙不要把题解po到github上!
因此我做的是Fall 2021的版本,所有的starter code都在这里。
至于如何在自己的github上备份代码,参考这里。
虚拟机平台用的是VirtualBox,144官方提供了基于Ubuntu的系统镜像,CPU和RAM随便设。
大致按照官方文档配置环境,windows环境可以用powershell,无需Putty。
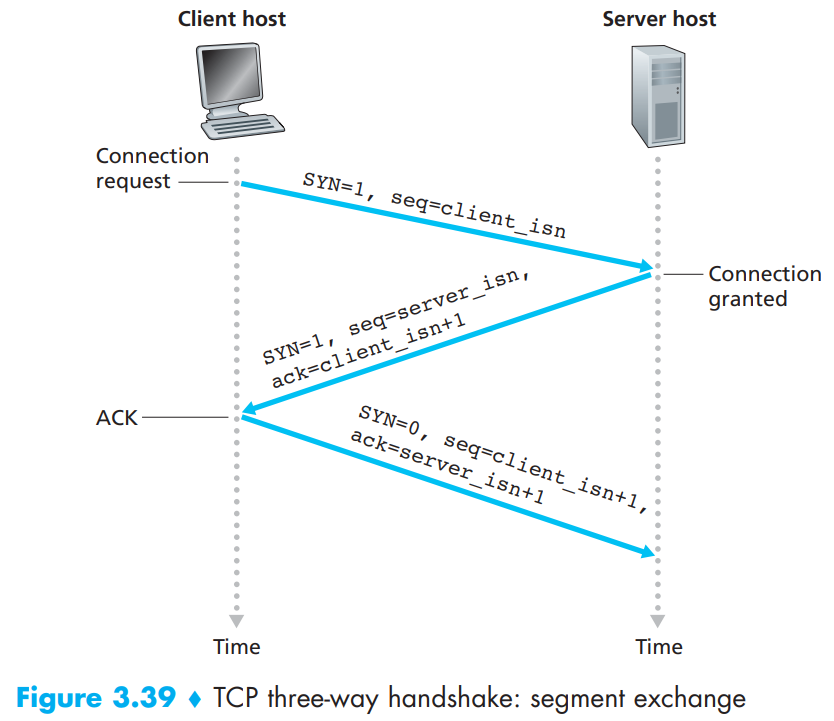
开启虚拟机,通过ssh client建立TCP连接到远程主机的某端口:ssh user@remote -p port,user是在远程主机的用户名,remote是远程机器的地址(IP/域名),port是ssh server监听的端口,默认22(即登录请求会送进远程主机的22端口),上面通过-p参数改变了该端口。
不过遇到了点问题:
奇怪!远程虚拟机明明安装了ssh服务!
从主机去ping虚拟机超时,但是虚拟机可以ping通主机,参考这个设置成功ping通,后来发现国内的这些blog都是在胡说八道,真正的原因和解决方案在这里,本质上是虚拟机的端口转发没设置好,设置好后VB会把连接localhost:2222的TCP请求转发到虚拟机的22号端口。
关于IDE,开始用的VIM,后来想用vscode,Host上安装vscode以及remote-ssh插件,关于配置网上一大堆教程,自行学习吧,powershell以后就负责编译运行了。
Lab 0
Networking by hand
这些小游戏都是为了翻译翻译:什么是可靠的双向字节流,网络通过这种抽象完成许多重要的交互,如上网冲浪、发邮件等。
第一个事是要手动模拟浏览器的请求过程(注意手速,不然还没输完就408 Timeout了):
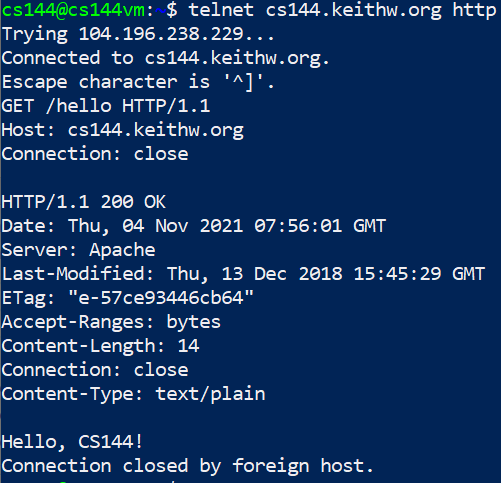
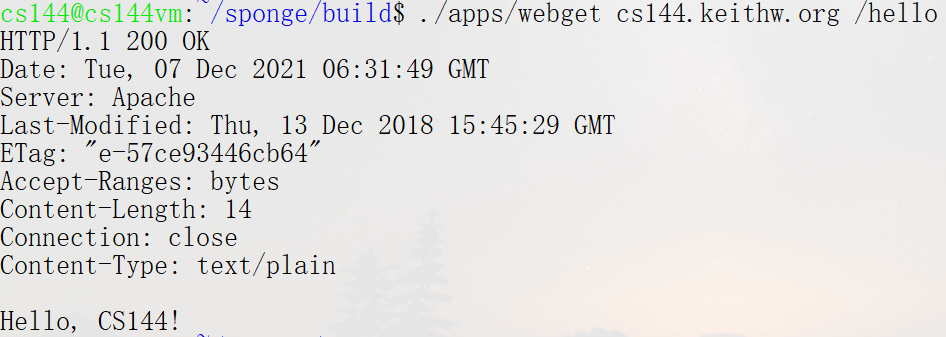
telnet cs144.keithw.org http:telnet作为一种client程序,负责和服务器的某个服务建立连接。用telnet客户端程序在本机和服务器之间开一个可靠的字节流,并请求服务器的http服务(80端口),连接成功证明端口可用- 建立连接后就要通过HTTP协议请求内容:需要告诉服务器所请求URL的path和host:
GET /hello HTTP/1.1Host: cs144.keithw.org,不过为啥需要host呢?难道服务器不知道自己的ip吗,好像是因为服务器可以同时运行多个网站/服务 Connection: close:表示希望服务器一旦完成响应,就关闭连接- 输入回车(空行):表示HTTP请求头结束,接下来是请求数据(当然GET没有,POST有)
其实这就是一个HTTP请求报文,效果:
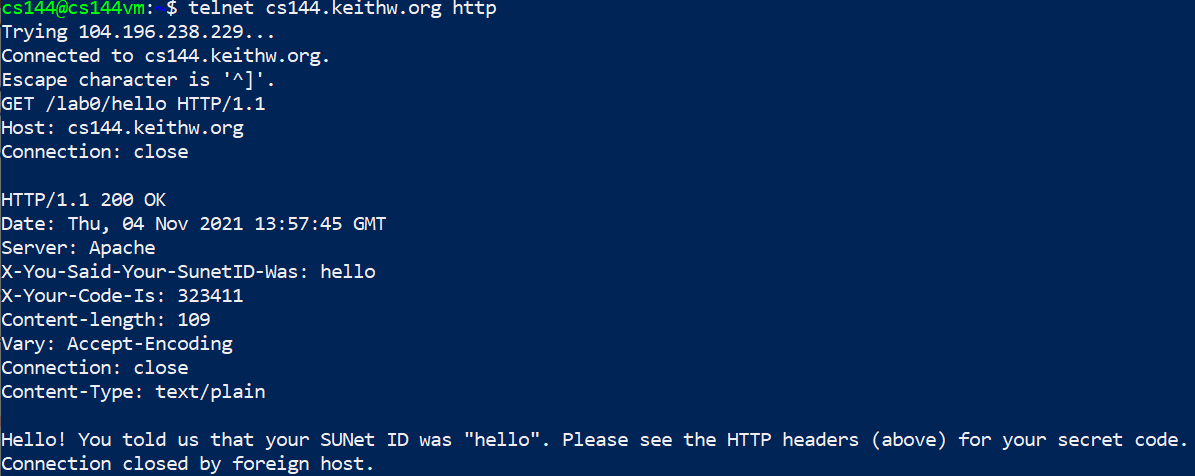
作业就是瞎玩:
第二个事是学着发邮件,请求服务器的SMTP服务(主要用来发邮件),我试试和自己的邮箱互动下:
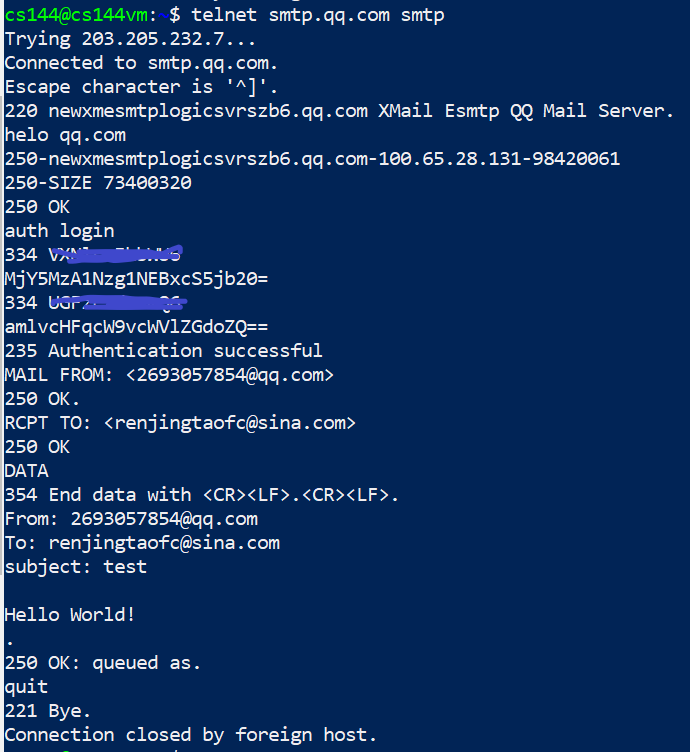
这里要注意:首先要开启IMAP/SMTP服务,还需要获取第三方客户端登录的授权码,登录时邮箱名称和授权码都需要Base64格式。
文档里说From地址是可以伪造的,有点神奇,垃圾邮件可能挺喜欢干这事!但是我实际操作时是伪造不了的:

因为已经登录了本人账户,所以发件人必须一致,Stanford那个没有登录,也许是商业邮件系统一般都比较完善?
第三个事是作为服务器去监听,主要使用所谓的瑞士军刀netcat:
netcat -v -l -p 9090:-v表示显示执行命令过程,-l表示开启监听,-p表示在指定端口监听
telnet localhost 9090:
然后服务器(netcat)和客户端(telnet)就可以通信啦!
Network program using an OS stream socket
这部分让同志们利用操作系统内核提供的stream socket从Internet上抓网页,和上文中手动抓差不多,不过这次是把手动过程写成代码。
由于Internet只能提供尽最大努力交付的数据报服务,因此这些数据报可能会:丢失、乱序、内容更改、重复,所以通常OS会把Internet的这种抽象转为可靠的双向字节流,以便应用层软件使用。OS一般使用socket来完成这种转变并向程序员提供接口,socket和文件描述符类似,一旦建立连接就能进行可靠的通信。后续会自己实现一个TCP去揣摩这种转变。
这个简单的web client程序有几个要注意的地方:
- 由于
connection: close,因此服务器只会处理一次http请求 - 服务器响应后就会关闭从server到client的socket连接,但是client的
socket.read()可以持续读:If the connection is broken on a stream socket, but data is available, then the read() function reads the data and gives no error. If the connection is broken on a stream socket, but no data is available, then the read() function returns 0 bytes as EOF. - EOF一般是一个定义为-1的宏,因此没有对应的ASCII字符,因此也无法显示出来(可以强制转int),C语言将其定义在某个头文件的宏里(可以直接用EOF判断),C++一般使用函数判断。EOF的作用就是client可以判断是否读完了server发来的响应,终端输入windows环境是ctrl+Z,linux是ctrl+D
- 为什么一个
read()不够呢?因为read()是有limit的,超过上限就得多次读,std:string FileDescriptor::read(const size_t limit=std::numeric_limits<size_t>::max()) - 及时关掉socket的写功能是一个好习惯
An in-memory reliable byte stream
在单机上实现一个可靠的字节流(内存里当然是可靠的),writer可以结束字节流输入,reader读到EOF后就无法继续读。
基本可以理解为一个容量为capacity的buffer,capacity用来进行流量控制,文档说了只会进行单线程操作,因此不用担心并发的读/写。
需要注意:流本身可以无限长,capacity存储的是已经写入但还未读取的字节,哪怕capacity = 1,只要writer每次写入一个字节,reader读走,这个流就可以无限长。
开始想用queue,但是queue无法支持peek_output操作,那就用deque了。
size_t write(const std::string &data):如果长度大于capacity该如何处理?这种情况多余的写入只能被丢弃,就和网络上超出线路容量的写入被丢弃一样。
size_t bytes_read() const返回的是所有pop的字节数目,包括read(const size_t len)和pop_output(const size_t len)。
bool input_ended() const返回流输入是否结束;bool eof() const是reader判断是否读取到了流输出的结束位置,因此必须满足writer已经有过写入且buffer为空。
记得先make format,再make编译,最后make check_lab0自动化测试。
Lab 1
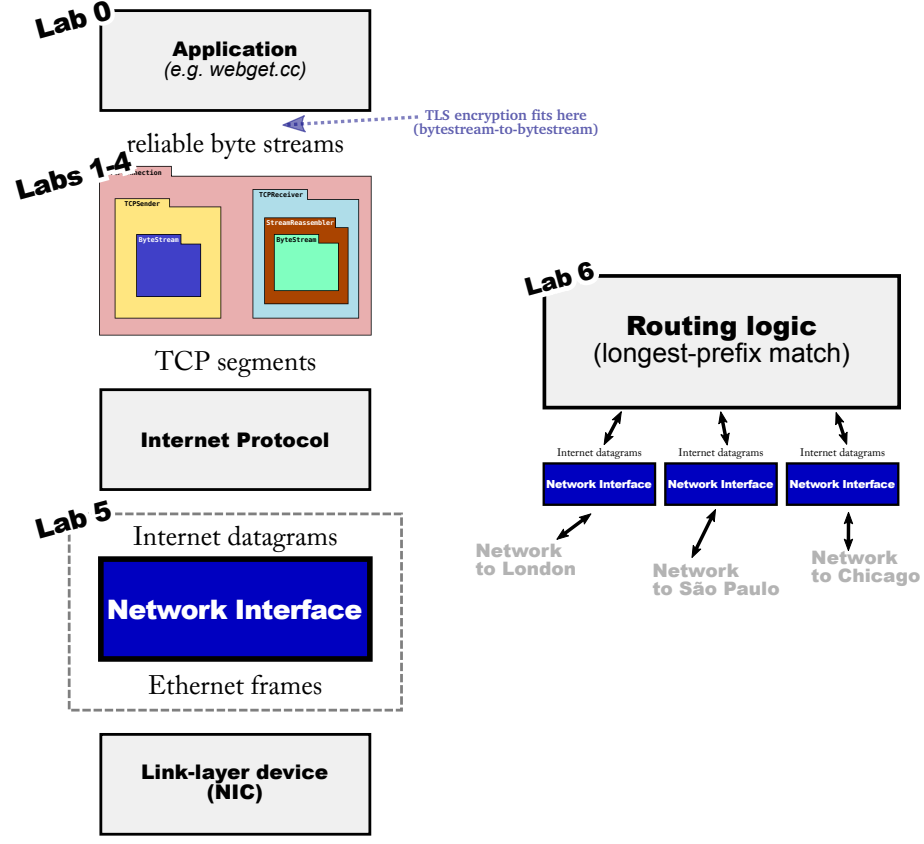
接下来的4个lab要自行实现一个TCP,模块如下:
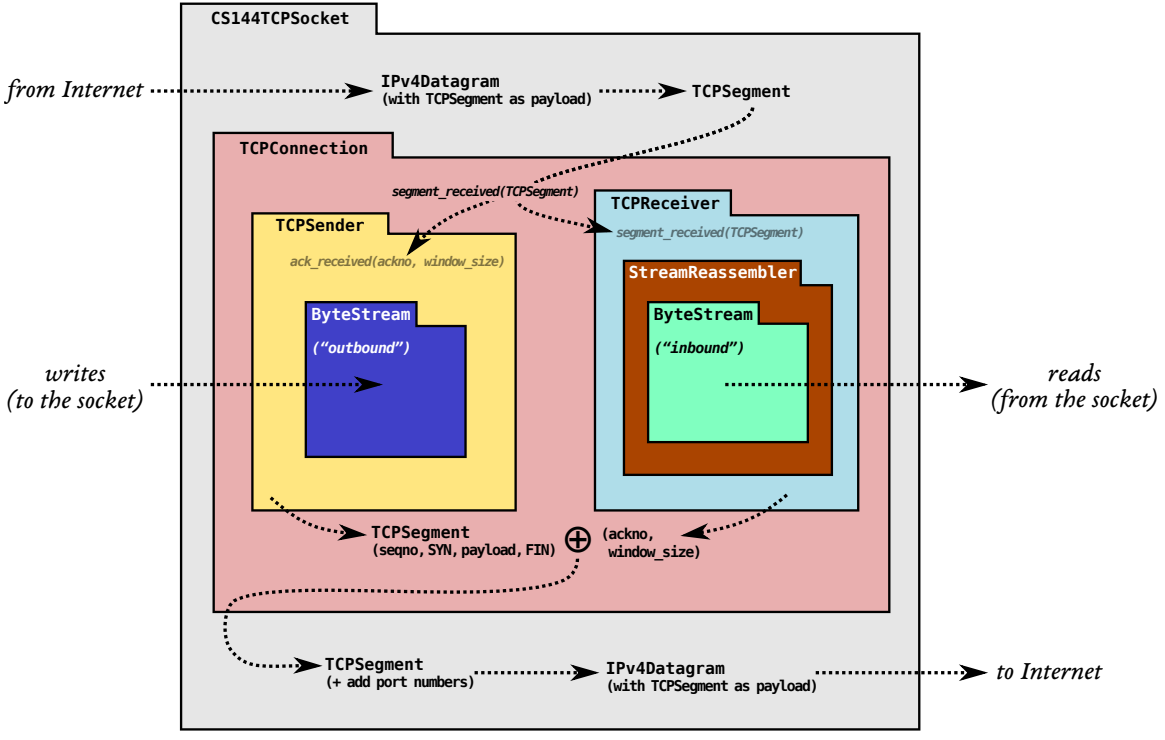
由于sender会将发送的字节流分割为若干segments,每段不超过1460B,封装为数据报交给网络传送,但这些segments可能会乱序、丢失、重复、交叉重叠、长度不一,但是不会出现inconsistent的段,因此Lab 1要实现一个流重组器,将收到的字节流中的segments拼接还原为其原本正确的顺序。
StreamReassembler会用一个可靠字节流ByteStream作为输出:as soon as the reassembler knows the next byte of the stream, it will write it into the ByteStream. 接着应用层就可以从ByteStream读取有序的字节流。StreamReassembler和ByteStream的容量大小是一样的,不过ByteStream真正的size(绿色部分)是动态变化的。
push_substring(const string &data, const uint64_t index, const bool eof)一旦超出StreamReassembler的容量,就只能丢弃该碎片(或者丢弃部分);
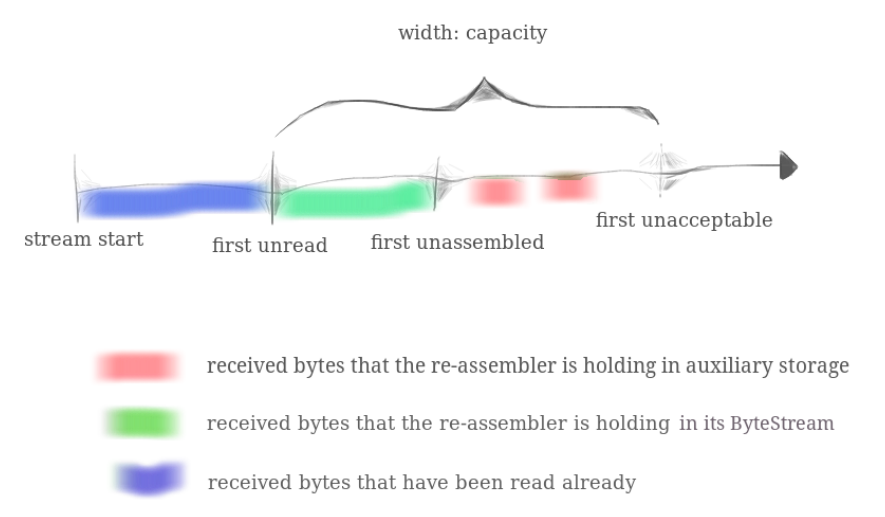
根据上图:可以想象为我们拥有一条index从0开始的无限长的字节流,每个段都有自己在流中的位置,随着应用层读取流中的数据,StreamReassembler就像一个滑动的窗口,落在该窗口内的段都需要被按序组装。
显然,需要用某种数据结构把不能直接写入ByteStream中的segments存起来:data+index即可唯一确定,因此单个segment可以用类、结构体或std::pair存储,为了方便起见,在segment结构体中增加成员变量len来指示其有效长度。
由于可能需要根据index快速查找合并位置,因此最好按序存储,并且自动去重,所有不能写入的segments可以用std::set来存,底层基于红黑树实现。
处理逻辑:
- 新来段是否超出/部分超出了
StreamReassembler的窗宽,如超过则进行剪切; - 新来段是否和
ByteStream之前(蓝色+绿色部分)有重叠,如有则切除重叠部分; - 合并新段和暂存段:确定新段插入位置,不断将其前后的暂存段往新段上合并,直到找不到可以继续合并的暂存段;
- 判断能否写入
ByteStream; - 处理后新段的eof为true:
若暂存区为空,结束向结束写入的时机可能会导致潜在bug,后面有血泪教训;若暂存区非空,ByteStream的写入报错,可能是last segment先到达但还不能写入,因此存入暂存区。
根据上述逻辑准备用3个函数完成:
void _cut_overlap(segment &seg);完成12void _merge_segs(segment &seg);完成3void _write_to_stream();完成4- 直接在
push_substring()处理5
这个实验一般就会开始出bug,我直接跪在了corner case,来了一个eof为true的"",空串是要被忽略的,但是这个空串带了我们需要的eof信息,由于在_cut_overlap直接返回:
if (seg.index >= _first_unacceptable || seg.index + seg.len <= _first_unassembled) return;
所以没有正确设置_eof:
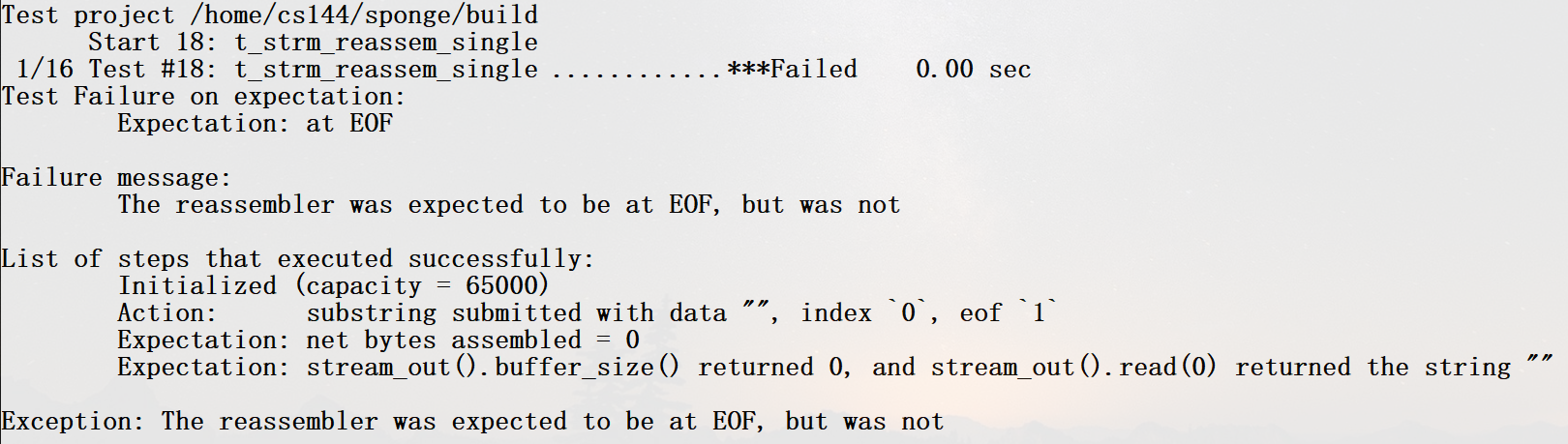
测试样例t_strm_reassem_single报错,所有的测试源码都在./tests文件夹下,对应的可执行程序在./build/tests。
sudo apt-get install gdb安装GDB,找到对应的测试源码文件fsm_stream_reassembler_single.cc打断点开始调试,跳出launch.json稍作修改就可以愉快地debug(面向测试编程)了:
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "sponge debug",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/build/tests/${fileBasenameNoExtension}",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
],
// "preLaunchTask": "C/C++: g++-8 build active file",
"miDebuggerPath": "/usr/bin/gdb"
}
]
}
后来第7个样例一直过不了,而且Byte Stream实际读取的字节数和真实值差距很大:

怀疑是提前end_input()了,主要是下面这种case:
first unassembled=7且first unacceptable很大,先来一个index=9, eof=true的"",再来一个index=7, eof=false的"ab",如果这样判断:
if (_eof && _unassembled_bytes == 0) {
_output.end_input();
}
很容易在第一个段就end_input()导致提前结束写入。
因此核心问题在于什么时候调用end_input(),我用了_eof_index来指示结束的位置而非用布尔变量_eof,一旦_first_unassembled >= _eof_index就结束输入。
Lab 2
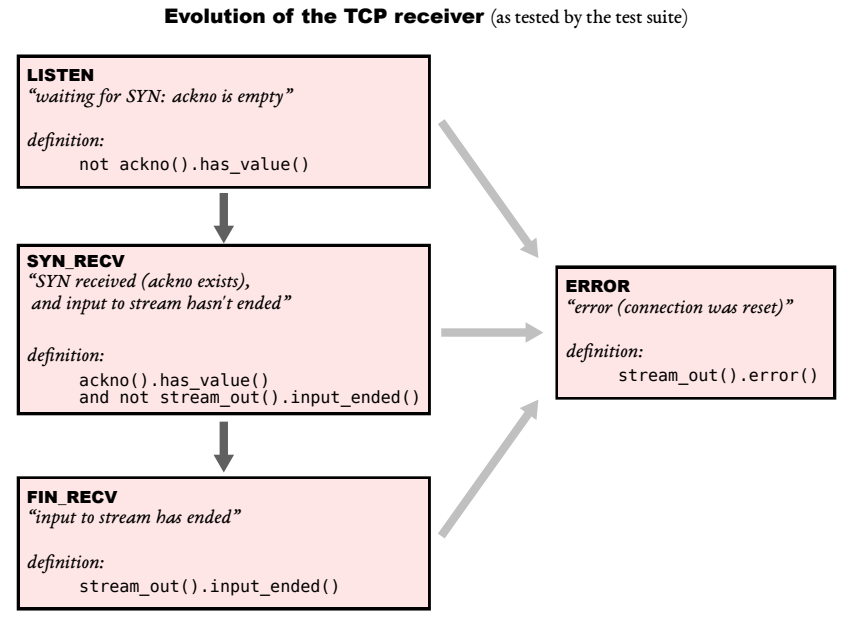
Lab 2要实现TCPReceiver,将从Internet接收的segments送入StreamReassembler转为可靠的ByteStream,以供应用层从socket读取。
除此之外,TCPReceiver还要负责和sender反馈:1. first unassembled字节的index,也叫做确认号acknowledgment,这样sender才知道下次该发送啥;2. first unassembled和first unacceptable之间的窗宽window size,用来告诉sender允许发送的字节范围。两者结合形成滑动窗口用来进行flow control。
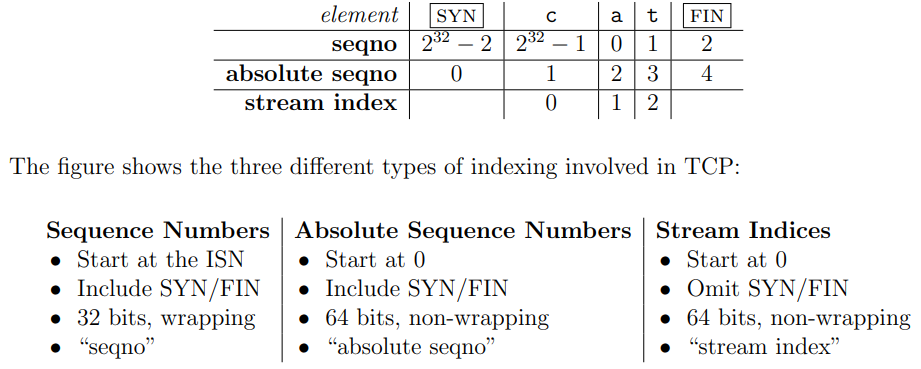
第一件必须要处理的事就是序列号sequence number的转换:在StreamReassembler中我们用的是64位的stream index,因此不太可能溢出,但是TCP header空间宝贵,所以第一个字节的index采用32位的seqno,这样就带来几个问题:
- stream index可以近似于无限大,但是seqno只能从\(0\sim2^{32}-1\)不断循环;
- 为了安全起见,seqno并不是从0开始,而是取一个随机数Initial Sequence Number(ISN)来表示stream的开始SYN(beginning of stream);
- TCP header中的SYN和FIN(end of stream)标志位都要被分配seqno,但是SYN和FIN并不是真正的数据,只是表示流的开始和结束。
| isn | isn+1 | isn+2 | ... | 2^32-2 | 2^32-1 | 0 | 1 | ... | isn-2 | isn-1 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | ... | 2^32-2 | 2^32-1 | |||||
| 2^32 | 2^32+1 | 2^32+2 | ... | 2^33-2 | 2^33-1 | |||||
| NaN | 0 | 1 | ... | first unassemble | ... | first unacceptable | 2^32-3 | 2^32-2 | ||
| 2^32-1 | 2^32 | 2^32+1 | ... | 2^33-3 | 2^33-2 |
第一行是32位的seqno,可以想象成在圆环上走路(正反走均可),二三行是64位的absolute seqno,四五行是64位的stream index。
absolute seqno转seqno:\(isn+n\%2^{32}\),\(n\)直接强制类型转换即可截取低32位。
seqno转absolute seqno:有点麻烦,可能对应多个结果,因此选择距离checkpoint最近的那个结果,checkpoint取前一次所收段的absolute seqno。原因在于两个前后到达的段absolute seqno的差值几乎不可能超过\(2^{32}\)。有个corner case是当checkpoint比较小时计算得到的absolute seqno可能小于0,需要加上\(2^{32}\)即1UL<<32。
做好索引的转换后,因为麻烦的部分已经在Lab 1完成了,剩下的就是根据TCPSegment写一些业务逻辑。

注意下SYN和FIN对ackno的处理就行:
Lab 3
这次的活是TCP Sender,负责将应用层的ByteStream分割为段发送,根据接收方的反馈情况进行超时重传。
每次收到接收方的ACK就可以知道其window size, 发送方在每次收到ACK时更新窗宽,并且在下一次收到ACK前,根据发送情况记录窗口的剩余容量,决定是否继续发送。
只要_stream还有需要发送的内容并且receiver还有空闲空间,fill_window就要一直组装成段并发送直到填满该窗口,receiver真正的free space应该是其声明的窗宽减去已发送但未被确认的所有段的长度总和,这个free space才是可以不断继续组装新段并发送时可以利用的,在fill_window组装新段之前要check该空间是否大于0。
另外,发送的第一个段是SYN段,没有数据,只有SYN和initial sequence number,SYN段发完后就返回等待receiver的connection granted,即第一次握手,此时窗宽看作1:
What should my TCPSender assume as the receiver's window size before I've gotten an ACK from the receiver?
One byte.
并且在TCP Header中SYN和FIN不能同时为1,否则应该报错RST,FIN段是可以携带数据的。
如果收到ack表明窗口大小为0,在fill_window当作1处理,但是超时的段不应double RTO,因为这是receiver的原因而非线路流量限制导致的,但是SYN段超时需要double RTO并增加重传counter,以便判断是否终止本次连接请求。
FIN段的处理需要仔细一些:
如果_stream.read以后_stream.eof()意味着ByteStream已经没有需要发送的东西了,这时就要考虑设置FIN的问题了,但是FIN是要占序列号的,也就意味着要在接收方的window里占空间,如果free space为50最后一段的payload size为30,那可以设置FIN;如果free space为50最后一段的payload size为51,那么最后一个字节就需要进行下一次发送,并且在下一次考虑FIN的设置问题;如果free space为50最后一段的payload size也为50,那么这段数据可以发送,但是这次没法设置FIN了,也就只能等到接收方腾出空间后才能继续。因此只有free space严格大于最后一段的payload size才可以设置FIN。
fill_window有一种情况,free space还有但是_stream.buffer_empty()已经空了,但是只是数据发完了,FIN标志还没发,就需要再发一个段,因此这样写是不行的:
while (!_stream.buffer_empty() && _receiver_free_space) {
}
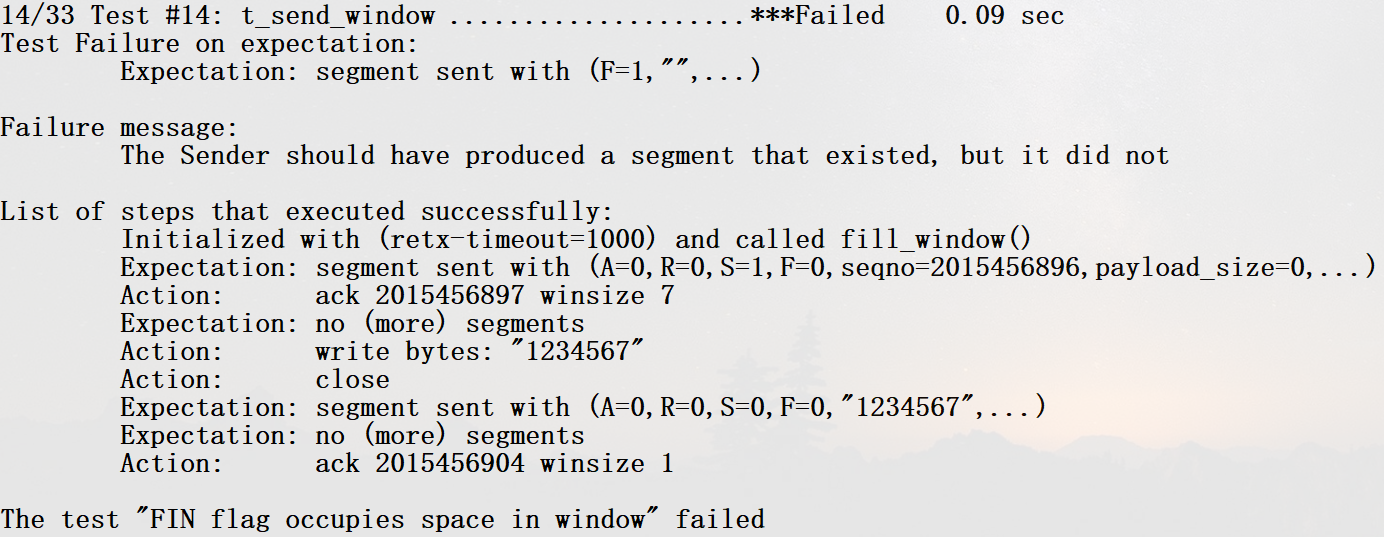
可以直接多循环一次然后用segment的length_in_sequence判断流是否真的空了以及是否要继续发送:
while (_receiver_free_space) {
size_t payload_size =
min({_stream.buffer_size(), static_cast<size_t>(_receiver_free_space),
TCPConfig::MAX_PAYLOAD_SIZE});
TCPSegment seg;
if (_stream.eof() &&
static_cast<size_t>(_receiver_free_space) > payload_size) {
seg.header().fin = true;
_fin = true;
}
seg.payload() = Buffer(_stream.read(payload_size));
if (seg.length_in_sequence_space() == 0)
break;
_send_segment(seg);
}
但是这样可能导致一直发送只包含FIN的段,因此要在while循环限定_fin来确保只发一次FIN段。
关于重传,闲来无事,把重传计时器单独写一个类,因为这个类相对比较简单,所以就和sender放在同一个头文件吧,不过据说有些公司的coding guideline有规定:
Each class shall have it's own header and implementation file.
采用累计确认:如果发送方收到ackno代表之前的所有段都正常接收,因此用std::queue存没有收到ack的段(包括只被ack了一部分的段),超时后从队头开始传。
_segments_outstanding发送时在std::queue里是按照seqno有序的,只有每次收到ack才从std::queue里扔掉一些已经被完全确认收到的段,否则认为std::queue里的所有段接收方均未收到。
收到ack并清理完_segments_outstanding后,如果此时还有未被确认的段,重启计时器并将RTO和重传counter恢复初始值。
注意收到的ack可能是非法的,比如ack了一个还没有发送的段或者ack了已经收到的段的序列号
还有一个corner case在send_extra.cc的95行,如果收到了与上次相同的ack,计时器是不应该重启的,重传时只有收到的ackno严格大于上一次的ackno才重启。
计时器的启动可以参考课本:
Lab 4
第一次在项目中体会到测试的重要性,也有点理解TDD的好处了,好的测试不仅能够发现问题,还能根据测试样例debug,再次跪谢Stanford~
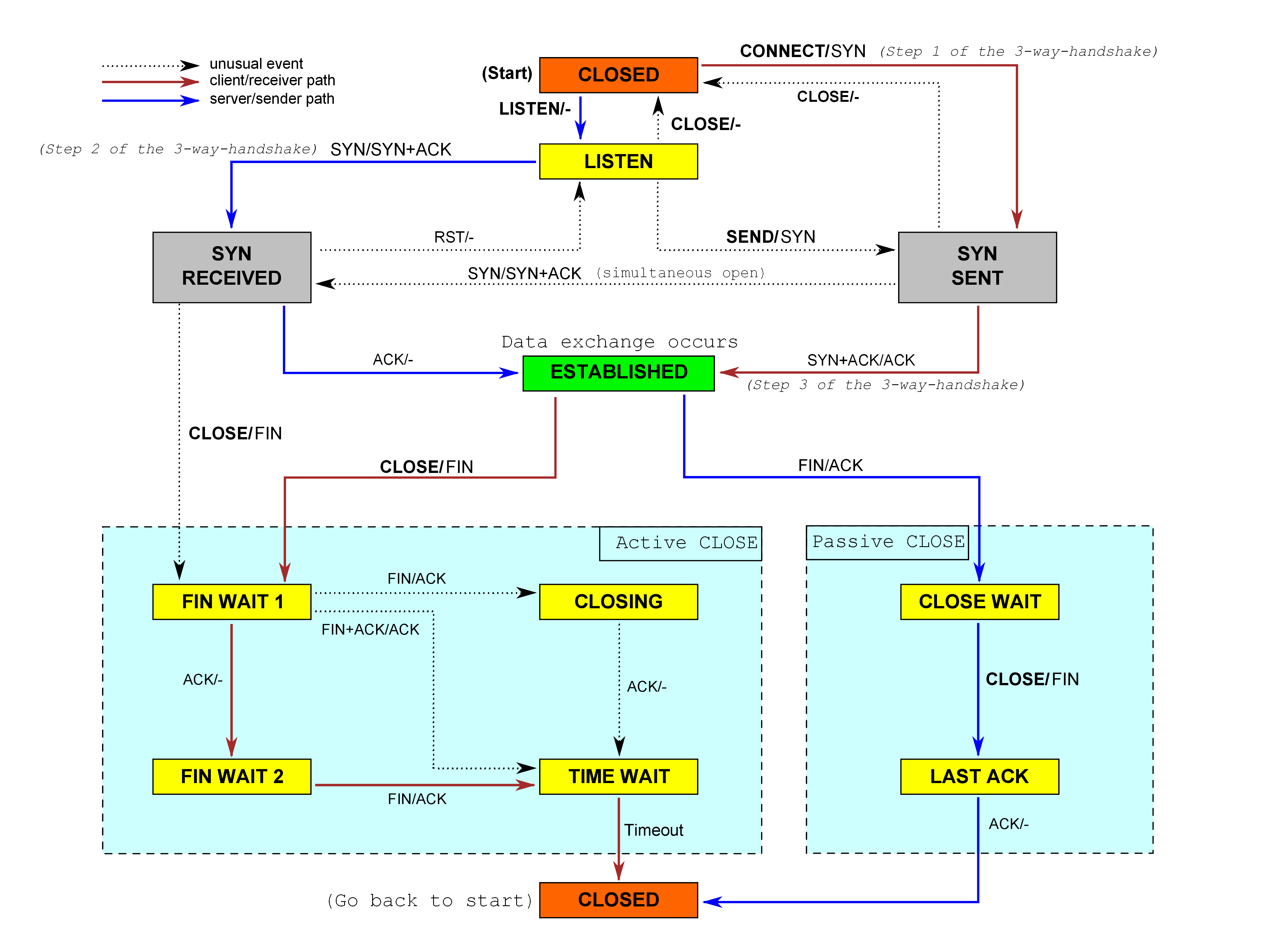
TCPConnection既充当接收者,也充当发送者,可以理解为实现以后就可以在你自己的主机上使用,接收别人的消息,发送自己的消息。
tick这里如果超过最大重传次数,不仅需要关闭连接,还要给peer发送带有RST的段:如果_sender的segments_out()不空,直接将队头的段设为RST,否则调用send_empty_segment()设置RST
比较抽象的是TCP的关闭这部分:
初步写完代码后,就对着测试样例疯狂调bug吧!!
遇到的第一个corner case是空ACK段(比如第3次握手),由于Lab3的sender只关注ackno和win,通过要发送的seg的length_in_sequence判断是否继续发送,第二次握手收到一个peyload=0的段,以后正常交流是不会这样的,因此第三次握手应该回一个段(可带可不带数据),但是Lab3的fill window遇到这种情况会直接返回,不会发送,我们在这里发送一个空ACK段作为第三次握手。
发送空的ACK段有以下情况:
- 第3次握手可能发空的,也可能携带数据
- 第2次挥手
- 第4次挥手
- keep alive
即只要收到了length_in_sequence>0的段都需要发ack,如果sender要发数据那可以顺便携带ack,否则就要发空ACK
有时候打断点会瞎跳,据说是编译优化的问题,

还有syn的处理需要考虑作为接收方和发送方两种情况分别处理
txrx.sh的测试不好过
调单个测试用例ctest -R test_name

建议按照状态机来写,否则会被细节折磨死。
神呀!104-160一直过不了,无奈只能通过替换网上的模块找bug

但是lab0-4全部替换仍然是那个bug,不知道哪里有问题。。。严重怀疑由于服务器在美国的原因

折腾vmware,自己配环境,G++注意设好后https://blog.csdn.net/kenkao/article/details/89550641?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_title~default-4.no_search_link&spm=1001.2101.3001.4242.3&utm_relevant_index=7
还要修改https://www.cnblogs.com/minglee/p/9016306.html
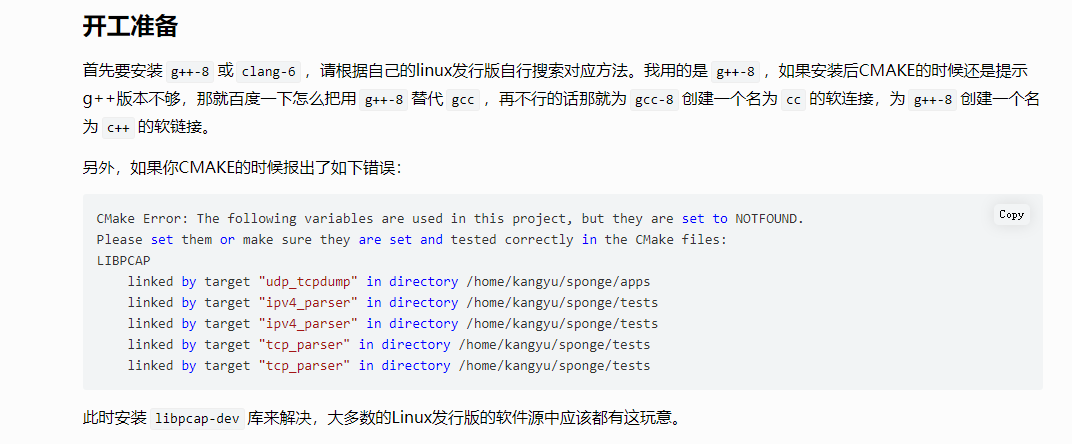
接着就可以正常make和测试了。
换到VMware没有任何改动一次性通过了所有测试:
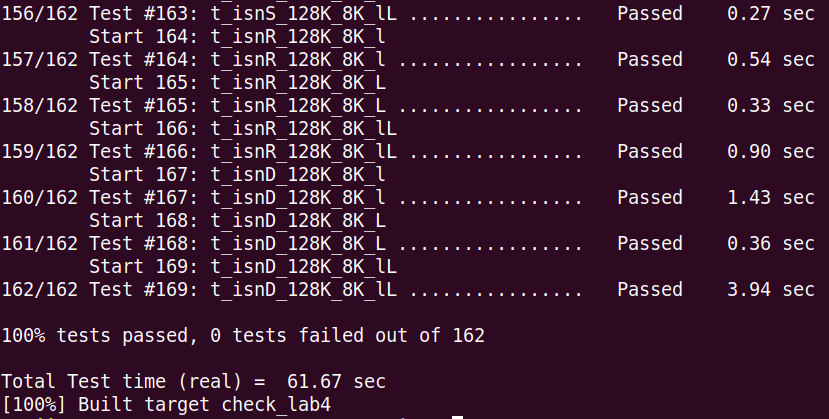
有点离谱...第一次遇到系统级别的Bug,卡了三天,全部模块替换为别人的还是挂...
Lab 5
实现IP/Ethernet网络接口,也叫网络适配器/网卡,用于IP数据报和以太网帧的转换,可以作为主机的TCP/IP协议栈的一部分,也可以作为路由器的一部分。
主机与peer之间TCP段的交互主要有以下几种方式:
- TCP-in-UDP-in-IP:进程只需提供TCP段和目的地址,剩下的事情均由Linux的
UDPSocket完成。内核负责构造UDP/IP/Ethernet header并发给下一跳,并确保每对socket的组合都是唯一的,保证不同进程间的隔离。 - TCP-in-IP:大部分情况下TCP段都是直接作为IP数据报的payload,需要向Linux的TUN接口提供IP数据报,内核负责构造Ethernet header并通过网卡发送,因此进程需要自行构造IP头。
- TCP-in-IP-in-Ethernet:网络接口
eth0/eth1/wlan0负责网络层和链路层的转换,Linux提供了更低级的TAP接口负责交换以太网帧。
大部分的工作都在ARP协议,有3个函数:
void NetworkInterface::send_datagram(const InternetDatagram &dgram, const Address &next_hop);
std::optional<InternetDatagram> NetworkInterface::recv_frame(const EthernetFrame &frame);
当TCPConnection或者路由器要发送IP数据报时,需要该函数转为以太网帧并发送。
如果下一跳的MAC地址已知,创建一个以太网帧type = EthernetHeader::TYPE_IPv4,将payload设置为序列化后的数据报;
如果下一跳的MAC地址未知,广播ARP请求来获取MAC地址,缓存当前IP数据报。为了避免ARP泛洪攻击,如果5s内某个IP地址已经发了ARP请求,不再针对该IP继续发送ARP请求。
只要ARP表没找到,说明需要学习目标MAC地址,因此发送的IP数据报均需要缓存。不论收到ARP请求还是回复,都需要学习ARP表,如果是请求,还要发送ARP响应。
由于以太网帧只传递一跳,如果收到的帧的目标MAC既不是当前网络接口的MAC也不是广播MAC就忽略。
VMware可以过,VB还是挂
Lab 6
这个实验要基于Lab 5的NetworkInterface实现一个IP路由器,负责将接收到的数据报根据路由表转发:从哪个网络接口转发以及下一跳的IP地址。
我们只负责根据生成的路由表转发,至于如何生成路由表(RIP/OSPF/BGP)无需关心。
第一个函数void add_route(const uint32_t route_prefix, const uint8_t prefix_length, const optional<Address> next_hop, const size_t interface_num);负责保存每条路由信息以备后续使用。
route_prefix和prefix_length共同确定一个网段,比如18.47.0.0/16的route_prefix=18*2^24+47*2^16,prefix_length=16,如果一个数据报的目的IP是18.47.x.y那么该条路由即匹配。
如果路由器直接目的网段,路由信息的next_hop为空,直接通过NetworkInterface发送到目的IP;如果路由器通过其它路由器连接到目的网段,路由信息的next_hop为下一个路由器的IP。
第二个函数void route_one_datagram(InternetDatagram &dgram);通过最长前缀匹配找到最佳路由,如果没有匹配的路由则丢弃数据报,如果该数据包的\(TTL\leq 1\)也丢弃,理论上丢弃数据报需要向源地址发送ICMP报文,否则通过最佳路由对应的NetworkInterface转发。
这里的abstraction在于路由器只需要关心IP数据报而无需关心链路层实现细节,只是通过NetworkInterface与链路层交互。
在通过移位比较两个IP地址前N位是否相同时,需要注意32位整数右移32位在C/C++中是未定义行为,因此prefix_length == 0需要特判。
Lab 7
到此为止,实现了Internet的传输层TCP协议、网络层和链路层之间的接口转换以及路由转发。
这个实验让我们用实现的这些组件和另一个人交互:
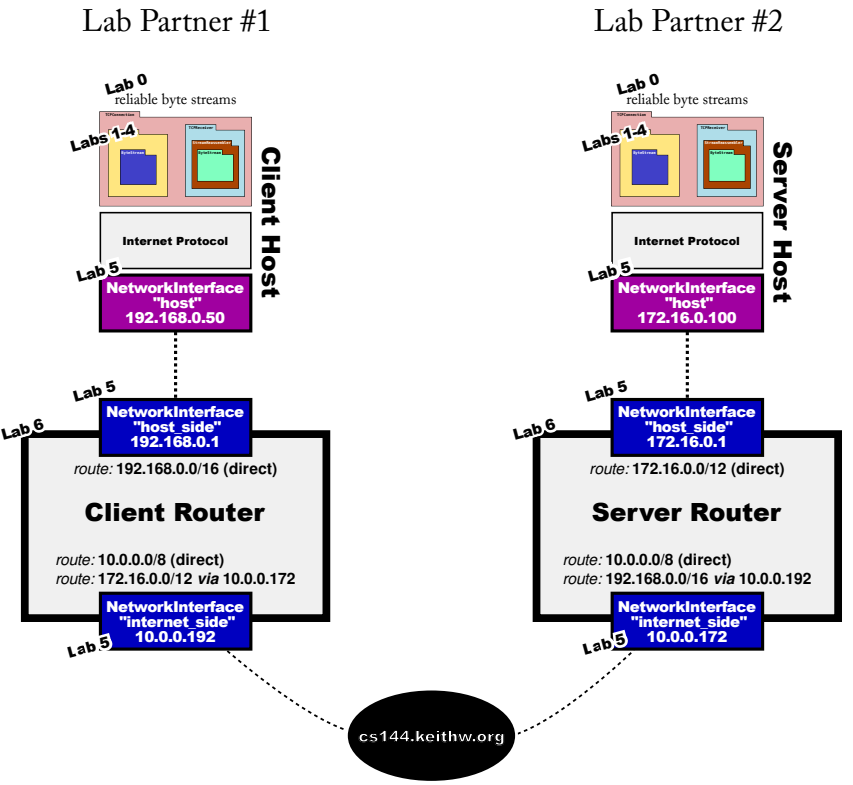
由于学校局域网内的IP都是私网地址(10.0.0.0/8,172.16.0.0/12,192.168.0.0/16),为了交互,需要通过NAT技术映射到公网IP,所以使用了cs144.keithw.org/104.196.238.229作为中继服务器。
按照文档交互:
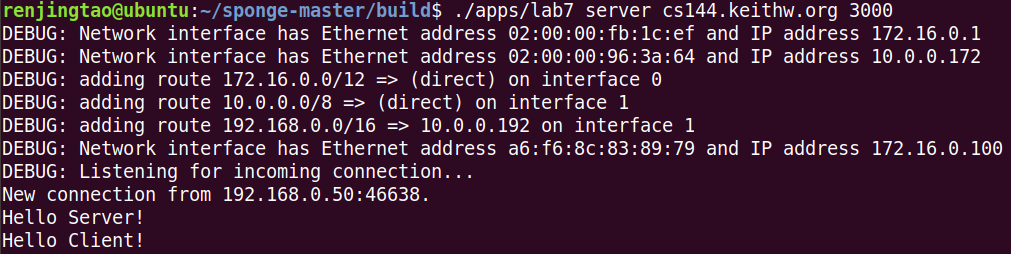
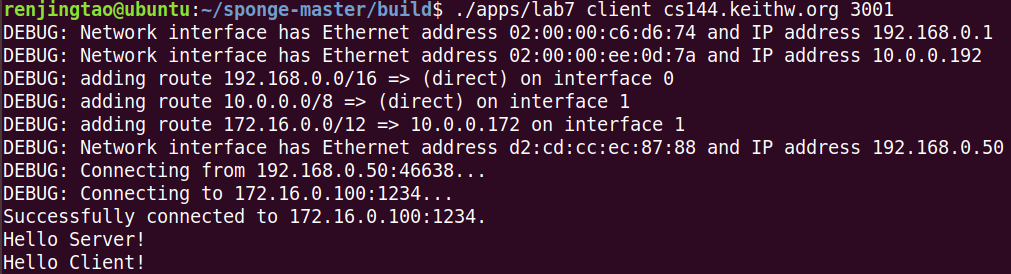
任意一方按ctrl+D单方向关闭连接后,就不能继续发送数据,但仍可以继续接收直到peer也关闭连接。双方都关闭后,任意一方完成了lingering之后连接才真正关闭。
除了聊天,还可以收发文件。
通关截图:
Refs
【计算机网络】Stanford CS144 Lab Assignments 学习笔记
斯坦福计网实验 / CS144 Lab Assignments
CS144计算机网络