read()读出来了之后文件里就从之后开始 光标不知道在哪
编码的进阶:

背景:
ASCII:英文字母,数字,特殊符号,------------>二进制的对应关系
str:
一个字符 --------------->一个字节
a:0001 0000
Unicode :万国码:世界上所有文字的
1个字符------------》4个字节
a:0001 00000001 00000001 00000001 0000
中:0001 00000001 00000001 00000001 0000
因为上面浪费
utf-8 : 至少使用一个
a:一位映射的ASCII
中:三位
gbk:国标
a:映射的ASCII
中:三位
1.不同的编码之间的0101011 是不能互相识别的
2.网络传输,数据存储到磁盘,--------------> 01010101二进制,不能使用unicod的编码本去编译
(Unicode) 四位 , 浪费的资源太多
大背景: python3X 版本
str:它在 内存中的编码方式:Unicode 涵盖所有的文字
但是 写入文件的内容,传输给别人的数据, 一般都是str的形式
矛盾点: 传输 和 使用 。
解决: 利用str 发送或者传输(转换,将unicodez转换成非U)----------->发送,传输
int
bytes 数据类型
Int
Bool
Str
Bytes 数据类型 与str 几乎一模一样 方法全有基本
List
Dict
Set
Tuple
英文:
Str :
在内存中的编码:Unicode
表现形式---à: ‘t’
Bytes:在内存中的编码:非Unicode
表现形式--à:b‘t’
编码:encode () 默认“utf-8”
# str --------> utf-8 bytes s1 = 'a太白' # encode 默认 utf-8 b1 = s1.encode() b1 = s1.encode('utf-8') print(b1)#b'axe5xa4xaaxe7x99xbd' # str --------> gbk bytes s1 = 'a太白' b1 = s1.encode('gbk') print(b1)#b'axccxabxb0xd7'
中文:
Str :
在内存中的编码:Unicode
表现形式---à: ‘t’
Bytes:在内存中的编码:非Unicode
表现形式--à:b‘t’
若只是英文的话可以,但是中文的话表示成16进制
s1 = b'中国'
^
SyntaxError: bytes can only contain ASCII literal characters.
6个
编码:
Str(Unicode) ----->bytes(非Unicode)
S1 = ‘a 太白’
Encode 默认使用 utf-8
B1 = s1.endcode(‘utf-8’)
B1 = s1.endcode(‘gbk’)
解码:
Utf-8 bytes ------>str Unicode
B3 = b'axe5xa4xaaxe7x99xbd'
S2 = b3.decode(‘utf-8’)
终极转换
Utf-8 bytes gbk bytes
And gb2312 Utf-16
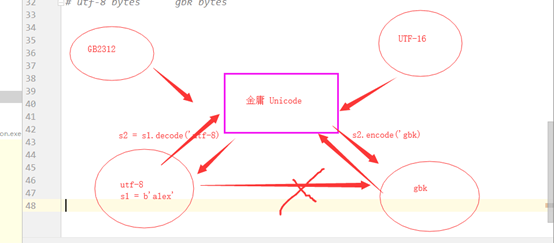
# 终极转换 # utf-8 bytes --------> gbk bytes b3 = b'axe5xa4xaaxe7x99xbd' # s = b3.decode() s = b3.decode('utf-8') print(s) b4 = s.encode('gbk') print(b4) #b'axccxabxb0xd7'
对于 他们的英文 映射的英文的话可以
互相转化 ,特殊情况
读文件:(5+5)
#__author : 'liuyang' #date : 2019/3/8 0008 f = open('G:path.txt',encoding='utf-8',mode='r') print(f.read()) # utf-8 是 读写 无论什么格式 而且 有的不对 无法编码 # f变量:f , f1 ,file , file_hander,fh ,f_h...文件句柄. ''' open()python的内置函数,python提供的一个功能, 底层调用的是操作系统的调用文件命令,接口 windows : 编码: gbk (默认)(国标) 为什么用种问 (美国用ASCII码) linux ,mas : 编码是utf-8 . ''' ''' 操作文件的流程: 1,打开文件,产生一个文件句柄 2,对文件句柄进行相应的操作(中间过程多) 3.关闭文件句柄''' f.close()
5文件的读:(r r+ rb r+b)
r 操作:r
# read () 全读 f1 = open('r模式' ,encoding='utf-8') # 默认是r模式 print(f1.read()) f1.close() #看他的数据类型 f1 = open('r模式' ,encoding='utf-8') # 默认是r模式 # content= f1.read() # print(content,type(content)) #字符 # f1.close()
读字节:
# f1 = open('r模式' ,encoding='utf-8') # 默认是r模式 # print(f1.read(3)) # f1.close()
读每行 和多行 列表(字符串存储)
print(f1.readline()) print(f1.readline().strip()) # 有换行符 去strip() # print(f1.readline()) print(f1.readlines()) #剩余的 ! 前面也是。 返回一个列表() # 列表的每一个元素 是 字符 f1.close()'''
读大文件的方法:
# 5 循环读取 f1 = open('r模式',encoding='utf-8') for line in f1: print(line) print(line) # 在内存之中 只出现 一次 然后显示给显示器 # 下一次 释放了 f1.close()
# w w+ wb w+b
# 没有文件 创建文件写入内容 (写了个 w 模式的文件)
f = open('w模式',encoding='utf-8',mode='w') f.write('随便写一点') f.close()
先清空后写
f.write('abcdefgh') # 没空格 一直写 f.write('abcdefgh ') f.write('abcdefgh') f.write('abcdefgh') f.write('abcdefgh ') for i in range(3): f.write('abcdefgh ') f.close()
文件的读写与输出 复制 粘贴
# wb f1 = open('image.jpg',mode='rb') content = f1.read() f1.close()# 产生了数据 关不关 不影响 f2 = open('image1.jpg',mode='wb') f2.write(content) f2.close()
image.jpg-----------------> image1.jpg
追加:
# a 模式 追加 文件的追加 # a ab a+ a+b # a 没有文件 ,创建文件,写入内容
f = open('a模式',encoding='utf-8',mode='a') f.write('6666') f.close()# 不close() 一直在内存占着 网站开着 以后一直占用
# 先读后写 和追加的区别是什么 可以写进去但是不显示
f1 = open('r模式',encoding='utf-8',mode='r+')
print(f1.read())
# f1.seek()
f1.write('1')
f1.close() #
r+ 先写后读 先读后写
# r+ 先读后写 加到最后 # f = open('r模式',encoding='utf-8',mode='r+') # content = f.read() # print(content) # f.write('dsdjal') # f.close()

# 先写后读 光标 先写 会替换掉 f = open('r模式',encoding='utf-8',mode='r+') f.write('dlaonanhail') content = f.read() print(content) f.close() print(f) # 读入的没有写出 还有替换被write 前面的
#第一种 规范代码

# 第二种 把光标放最前面
f1 = open('r模式',encoding='utf-8',mode='r+')
f1.write('111sss1')
# f1.flush()
f1.seek(0)
a = f1.read()
print(a)
f1.close()
# 经常用到的 # r r+ w a # 网络 :rb wb
文件描述符 , 强制保存
f1 = open('r模式',encoding='utf-8') # 默认是读操作 # print(f1.read()) print(f1.fileno()) # 文件描述符 f1.close() f2 = open('其他操作方法',encoding='utf-8',mode='w') f2.write('aldjlajll') # f1.flush()# 强制保存 f1.close()
writeable readable
f3 = open('r模式',encoding='utf-8') # 默认是读操作 print(f3.readable()) f3.close() # readable writeable 判断文件句柄是否可读 可写 if f3.writable(): f3.write('12222') f3.close()
seek 的光标 不改变 tr 的截取 截取从头开始 到 字节 处
# 网络编程 : FTP的作业,断电续传的功能 # seek tell 断了之后 获取光标的位置 下次下的时候在此调整到这 f1 = open('r模式',encoding='utf-8') # 默认是读操作 f1.seek(9) # 默认字节 之后 print(f1.read()) print(f1.tell())# 获取光标的位置 f1.close()

truncate
f1 = open('w模式',encoding='utf-8',mode='w') # 默认是读操作 f1.write('wwajfaldjakgjdlajglajdg') print(f1) f1.close() # truncate # 对源文件进行截取 # 它 必须在可写的情况下适用 a(追加) w r+(读写) 都可写 f1 = open('w模式',encoding='utf-8',mode='r+') # 默认是读操作 # 从开始截9个 只剩下 9个字节 print(f1.truncate(1)) # seek 不好使 r模式下 是字符 rb 模式下是字节! # f1 = open('r',encoding='utf-8',mode='rb') # a = f1.read() # print(a) # f1.close()
# 最常用的几个方法 read seek tell flush readable writeable
# open close 都得写
# 有些时候不需要 写close()
# 一个with 语句可以操作多个文件
# 他是检查 是否操作完 然后 关闭 有时间间隔
# 打开文件的第二种方式 with open('其他操作方法',encoding='utf-8') as f1, open('r模式',encoding='utf-8',mode='w') as f2: #付给 f1 print(f1.read()) f2.write('da爱活动公交偶就FFljdkj') print(f2.write('sjdiasjidj')) ## 写了多少位 14
# 有些时候不需要 写close()
# 一个with 语句可以操作多个文件
# 他是检查 是否操作完 然后 关闭 有时间间隔
#缺点:with open as 主动关闭 检查
with open('其他操作方法',encoding='utf-8') as f1: print(f1.read()) # 在打开 的过程中 可能会关闭 然后报错IOErrorr with open('其他操作方法',encoding='utf-8') as f2: pass
09 文件的改 文件的改只能采取这种方法把,不能在一个文件里先读后改 只能通过一个中介在同一个文件里写错误 可以追加
1.以读的模式打开源文件
2.以写的模式创建一个新文件
3.将源文件内容读取出来,按照你的要求改成新内容,写入新内容,
4.删除原文件
5.将新文件重命名成原文件
import os with open('amoshi ',encoding='utf-8' ) as f1 , open('a模式',encoding='utf-8',mode='w') as f2:
#low 版 内存太大的操作不了 # old_content = f1.read() # new_content = old_content.replace('alex','sb') # f2.write(new_content)
for old_line in f1: new_line = old_line.replace('sb','alex')# 有就改 没有也不报错 f2.write(new_line) #字符串操作 # 4.删除原文件 os.remove('amoshi ') #5.将新文件重命名成原文件''' # python相同目录下 os.rename('a模式','amoshi ')
浅copy 一个代码块和两个代码块一样 深浅copy 在于 可变的不一样 共用的没区别
深copy
#__author : 'liuyang'
#date : 2019/3/8 0008
'''
09 文件的改
1.以读的模式打开源文件 open r
2.以写的模式创建一个新文件 w
3.将源文件内容读取出来,按照你的要求改成新内容,写入新内容,
a = old b = replace()
4.删除原文件
5.将新文件重命名成原文件'''
# low 版
'''
import os
with open('amoshi ',encoding='utf-8') as f1 ,
open('a模式',encoding='utf-8',mode='w')as f2:
# old_content = f1.read()
# new_content = old_content.replace('alex','sb')
# f2.write(new_content)
for old_line in f1:
new_line = old_line.replace('sb','alex')# 有就改 没有也不报错
f2.write(new_line)
#字符串操作
# 4.删除原文件
os.remove('amoshi ')
#5.将新文件重命名成原文件 # python相同目录下
os.rename('a模式','amoshi ')
'''
# f = open('amoshi',encoding='utf-8',mode='r')
# a=f.read()
# f1=open('a' ,encoding='utf-8',mode='w')
# f =a.replace('alex','sb')
# f.close()
# f1.close()
# 不行
# 深浅 copy
# 赋值运算 变量指的是同一个
l1 = [1,2,3,[11,22]]
l2 = l1 # 鲁迅 = 周树人
# 共用一个
# 元组的列表也可以
l2.append(666)
l2[-2].append(666)
print(l1)
print(l2)
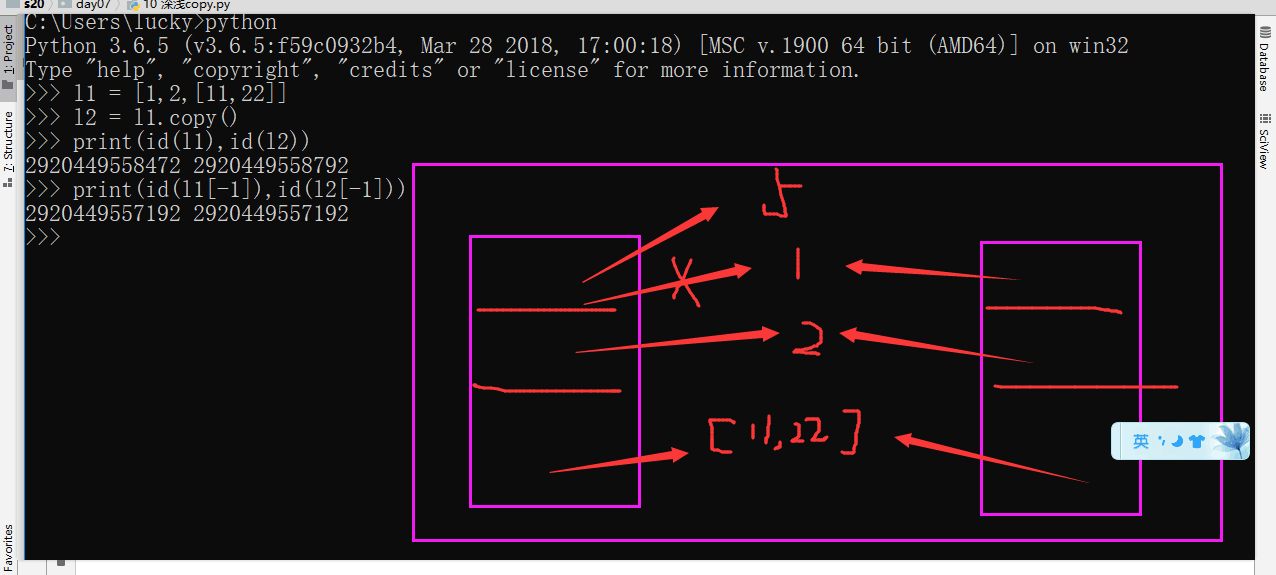
# 浅 copy # 面试题考的较多 深浅copy
#copy 复制,浅浅的复制一份
# lisT dict set 都可以
l1 = [1,2,3,[11,22]]
l2 =l1.copy()
# 只是copy了一个列表 元素还是沿用了之前的元素
# copy 了一个外壳
# 整容 成一样的了 但是不一样人
print(id(l1))
print(id(l2))
# 内存地址不一样
# 元素内存地址一样
print(id(l1[0]))
print(id(l2[0]))
# l1 变 l2 不变 内存里的两个
l1.append(666)
print('前:',l1)
print(l2)
#
l1[-2].append(22)
print(l1)
print(l2)
# 浅 copy: 复制一个外壳(列表),
#但是列表里面的所有元素,都共用一个。
# 深copy:深深的复制一下
import copy
l1 = [1,2,3,[11,22]]
l2 = copy.deepcopy(l1)
print(id(l1),id(l2))
# 不可变数据类型 共用 指向同一个
print(id(l1[0]))
print(id(l2[0]))
# 可变的数据类型 不共用一个
print(id(l1[-1]))#43439688
print(id(l2[-1]))#43378888
# 不改变
l1[-1].append(222)
print(l1)
print(l2)
# 深copy:同一个代码块不同代码块
#不仅创建一个
# 浅copy 只 copy 一个外壳
# 其它的内容全部共用

# 下周一 上午 总结知识点
#(知识点,带着做题)
# 晚上考试
写文件 和 追加 文件 'w'和 ‘a’ 没有文件创建一个新文件
with open('wenjian' , 'w' , encoding='utf-8')
with open('wenjian' , 'a' , encoding='utf-8')