前言
主要讲解原理,基于2.6.32版本内核源码。本文整体思路:先由简单内存模型逐渐演进到当下通用服务器面对的内存模型,讨论每一个内存模型下slab设计需要解决的问题。
历史简介
linux内核运行需要动态分配内存,有两种分配方案:
第一种:以页为单位分配内存,一次申请内存的长度必须是页的整数倍
第二种:按需分配内存,一次申请内存的长度是随机的。
第一种分配方案通过buddy子系统实现,第二种分配方案通过slab子系统实现。slab子系统随内核的发展衍生出slub子系统和slob子系统。最新通用服务器内核一般默认使用slub子系统,slob子系统一般用在移动端和嵌入式系统,较老内核默认用slab。slab,slob,slub功能相同,但效率上的偏重点不一样。现下内核提供编译选项,供用户选择用三者中的哪一个。slab子系统是内核使用的原始方案,经过相当长一段时间演进,因此本系列博客讲解slab子系统的实现。充分理解slab后,理解slub和slob就很简单了。
slab和buddy的关系,以及slab存在的必要性
让我们考察buddy子系统和slab子系统提供的接口函数:
buddy子系统主要接口
1 //分配2的order次方个物理地址相邻的页面,返回第一个页的page描述符虚的拟地址 2 static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order) 3 //释放2的order次方个物理地址相邻的页面,addr指向第一个页中第一个byte的虚拟地址 4 void free_pages(unsigned long addr, unsigned int order)
slab子系统接口
1 /* 分配size字节大小的内存,返回这段内存的虚拟地址 */ 2 static __always_inline void *kmalloc(size_t size, gfp_t flags) 3 /* 释放objp指向的一段内存 */ 4 void kfree(const void *objp)
两者之间的关系:slab子系统基于buddy子系统系统实现。kmalloc内部调用alloc_pages, 将分配到的页拆分,取适合长度的内存段返回,把拆分剩下的内存段管理起来。linux内核内存管理架构中两者所处的位置如图(0)
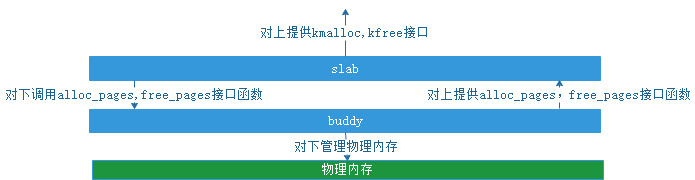
图(0)
既然有了buddy子系统,为什么又基于buddy子系统实现slab子系统呢?
出于空间效率:页的长度太小,会增加系统管理负担,一般页长度为4KB。举个例子:open系统调用中,用file数据结构描述被打开的文件。存放file数据结构需要的内存远远小于一个页,如果没有slab子系统,内核只有通过buddy子系统申请一个完整的页。一部分给file数据结构用,剩下的内存有两种方法处理。其一:open流程管理剩余内存,留作它用。如果内核的所有函数都要自己管理这种剩余内存,内存管理代码会分散到系统各个地方,显然是不科学的。其二:将每一个file装到一个页中,这个页剩余的内存不要了,这样会浪费内存空间。
出于时间效率:buddy子系统相对于slab子系统复杂很多,每次调用alloc_pages和free_pages要付出惨重代价。内核中有些代码又必须频繁申请释放内存。slab充当内核各个子系统和buddy子系统之间的空闲内存“缓冲池”。内存被kfree释放后,短时期停留在slab子系统中,再次kmalloc时,直接从slab分配。避免每次内存分配释放都调用alloc_pages和free_pages。
既然有了slab子系统,是不是所有的内存分配都经过slab子系统接口分配?
当然不是:
1.slab子系统时为了内核申请内存专门设计的,比如应用程序缺页还是要通过alloc_pages和free_pages申请内存。
2.内核中很多子系统必须通过alloc_pages和free_pages直接分配物理上连续的内存页。
3.另外一点slab子系统申请的内存一定在NORMAL区或DMA区,分配不到HIGHMEM区的内存,而alloc_pages和free_pages能分配到HIGHMEM区的内存
slab子系统调用alloc_pages申请完整页,然后将这些页切分成小段内存,slab是怎么将这些个小段内存管理起来的呢?
这正是本文要说的重点.
第一个处理机模型:
本节阐述如下模型下,linux实现的slab子系统:
1.内存是平坦的(非numa架构),并且不存在zone的概念,就是说所有的内存都同一个zone中(与实际情况不符,为了阐述方面,权且认为成立)
2.单处理器
3.Linux分页长度是4KB
4.buddy以及底层内存管理子系统为我们提供如下接口
1 /* 分配2的order次方个页,并返回这些页的文件描述符page的数组,2的order次方个页的物理地址和虚拟地址都是连续的 */ 2 static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order) 3 /* 释放2的order次方个物理地址连续的页,addr指向第一个页中第一个byte的虚拟地址 */ 4 void free_pages(unsigned long addr, unsigned int order) 5 /* 以文件描述符page作为参数,返回page描述的页的虚拟地址 */ 6 #define page_to_virt(page) 7 /* 以虚拟地址作为参数返回虚拟地址所在的页对应的页描述符地址*/ 8 #define virt_to_page(addr) 9 /* !!!上面这些接口正是内核实现的buddy系统接口原型 */
kmalloc流程
kmalloc流程必须要解决下面两个问题:
1.kmalloc给定size要快速找到一段满足要求的空闲内存段。
2.slab子系统中的空闲内存不够时,调用alloc_pages从buddy子系统中分配内存。
slab子系统管理的空闲内存段的长度是几个固定值,一般范围是{2^5,2^6……2^22},最短为32B,最长4MB。而kmalloc的参数size的理论范围为1到无穷大。用如下算法将kmalloc的入参size聚合到{2^5,2^6……2^22}中的各个值:
if(size<= 2^5) size=2^5 elif(size <= 2^6) size=2^6 elif(size <= 2^7) size=2^7 …… elif(size <= 2^22) size=2^22 else ERROR
这么聚集是没有问题的,因为调整后的size大于等于kmalloc的入参size,这样kmalloc返回的内存段的长度大于申请的内存段长度(只有kmalloc返回的内存段长度小于申请的长度时,才会导致内存被踩)。这样会导致内存浪费,例如:kmalloc的入参size=2^5+1时,调整后的size=2^6,这样kmalloc实际返回长度为2^6B空闲内存段,但kmalloc的调用者认为这个空闲内存段只有(2^5+1)B,这样一来,(2^6-2^5-1)B就浪费了。这种浪费最坏情况下接近slab子系统已分配出去内存的1/2. 还有一个问题:当size>2^22次方的情况是一个错误,slab子系统在4K分页下,默认能分配的最大内存段长度是2^22B。用18个kmem_cache数据结构分别管理长度为2^5,2^6……2^22次方的空闲内存段。需要引入两个数据结构——kmem_cache,cache_sizes。两个数据结构的关如图(1),其中malloc_sizes数组长度是18,元素是cache_sizes,每一个cache_sizes有一个指针指向一个kmem_cache,kmem_cache负责管理特定长度的空闲内存段,即同一个size的内存段由同一个kmem_cache管理。
1 /* Size description struct for general caches. */ 2 struct cache_sizes { 3 size_t cs_size; 4 struct kmem_cache *cs_cachep; 5 };
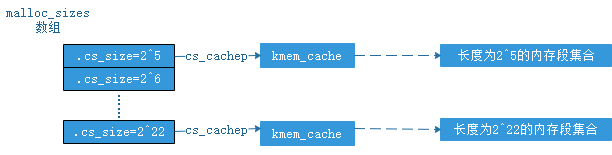
图(1)
接下来分析kmem_cache是如何将空闲内存段集合组织起来?
展开kmem_cache数据结构如下,新引入一个数据结构slab. 以cs_size=2^10为例,kmem_cache,kmem_list3以及slab三者之间的关系如图(2).kmem_cache内嵌数据结构kmem_list3,kmem_list3中有三个双向链表:partial,full,free.链表中链接了slab数据结构。每个slab数据结构中的s_mem字段指向了需要管理的“一大片”空闲内存,这“一大片”空闲内存虚拟地址连续(物理地址也连续),被分成了若干个2^10B大小的内存段。图(1)中标红的内存段是已经分配出去的,标蓝的是未分配出去的。这样就很好理解partial,full,free链表了:partial链表中链接的slab数据结构,其下管理的1KB内存段有部分已被分配出去,部分是空闲的。full链表链接的slab数据结构,其下管理的1KB内存段已全部被分配出去。free链接链接的slab数据结构,其下管理的1KB内存段都没有被分配出去。
1 struct kmem_cache { 2 unsigned int gfporder; 3 int buffer_size; 4 struct kmem_list3 5 } 6 struct kmem_list3 { 7 struct list_head slabs_partial; /* partial list first, better asm code */ 8 struct list_head slabs_full; 9 struct list_head slabs_free; 10 } 11 struct slab { 12 struct list_head list; 13 void *s_mem; /* including colour offset */ 14 unsigned int inuse; /* num of objs active in slab */ 15 kmem_bufctl_t free; 16 }; 17 struct list_head { 18 struct list_head *next, *prev; 19 };
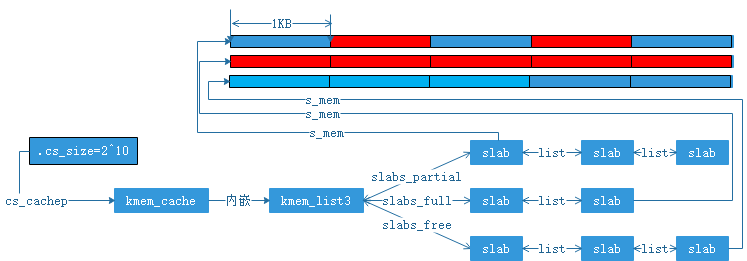
图(2)
引入几个概念:slab对象(object):图(2)中s_mem指向“一大片”内存中的1KB内存段。slab描述符:用来表示图(2)中的slab数据结构。那么slab描述符是如何描述自己管理的slab对象哪些已经分配出去,哪些是空闲的呢?其实就是使用了一个静态链表。下面让我们展开讨论这个链表,如图(3),静态链表虚拟地址挨着slab描述符.其中slab::free=3表示s_mem指向的内存中第3个object空闲,图(3)静态链表下标为3的槽位中填写的是0,表示s_mem指向的内存中第0个object空闲。图(3)中链表的头是free,尾是第6个“节点”0xF".通过如图(3)所示的静态链表,被slab描述符管理的空闲对象链接成一个链表。从链表中取一个元素ret(s_mem指向的内存中第ret个对象空闲,将被分配出去):{ret = slab->free; slab->free=((unsigned int)(slab+1))[slab->free];},向链表中添加一个元素add(s_mem指向的内存中第add个元素被释放掉):{((unsigned int)(slab+1))[add]=slab->free; slab->free=add;}
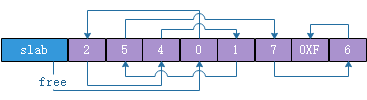
图(3)
上文描述完malloc_sizes数组,cache_sizes,kmem_cache,kmem_list3,slab数据结构,可以描述kmalloc流程
1.先将size对其到{2^5,2^6……2^22}中的某一个值,然后索引malloc_sizes数组,得到kmem_cache
2.查看kmem_cache::kmem_list3::slabs_partial链表是否为空,如果为空跳转第7步
3.取下kmem_cache::kmem_list3::slabs_partial中的一个slab
4.用操作{ret = slab->free; slab->free=((unsigned int)(slab+1))[slab->free];}得到该slab中一个空闲对象下标(ret)
5.addr = slab->s_mem+slab_kmem_cache::buffer_size * ret 得到空闲对象的地址,作为kmalloc申请到的内存段地址
6.slab->inused++;如果 slab->free=0XF那说明本slab种的object已经全部分配出去,将slab添加到kmem_cache::kmem_list3::slabs_full链表,返回。如果slab->free!=0XF,将slab添加到slab_partial链表,然后返回。
7. 查看kmem_cache::kmem_list::slab_free链表是否为空,如果为空,则跳转第9步
8.取下kmem_cache::kmem_list::slab_free中的一个slab,跳转到第4步
9.调用alloc_pages分配2的kmem_cache::gfporder次方个虚拟地址连续的页面(其实这些页的物理地址也是连续的),页面首地址为page_addr;
10.申请新的slab描述符+静态链表,slab->s_mem=page_addr; 然后根据kmem_cache::buffer_size 初始化slab的静态链表
11.将初始化完成的slab放到kmem_cache::kmem_list::slab_free中,跳转到第2步。
总结:
1.流程在第6步返回。
2.第9步点出了调用alloc_pages时机:kmem_cache下没有空闲对象时,就调用buddy子系统接口来分配新的空闲内存页面。
2.1.一次申请到的空闲页面数是2的kmem_cache:gfp_order次个。
2.2.由2.1可以导出:同一个kmem_cache下所有slab中s_mem字段指向的“大片内存”长度近似相同(现阶段可以认为相同,由于受slab着色机制的影响会有些差异)
3.同一个kmem_cache下slab管理的对象个数也是彼此相同。
4.第5步点出同一kmem_cache下的对象具有相同的长度(等于kmem_cache::buffer_size),到此为止,我们回答完了第一个问题。
kfree流程
kfree需要解决的问题:
1.kfree只有一个参数objp,必须知道objp指向内存段所在的kmem_cache和slab,我们才能将objp归还给slab子系统。(从哪里来到哪里去)
2.slab子系统中空闲内存过多时,调用free_pages将空闲页归还给buddy子系统。
linux使用页描述中的如下两个字段来建立对象地址objp和kmem_cache及slab描述符的关系, 本节开头提到过宏define virt_to_page(addr)可以将一个虚拟地址addr转换成addr所在页面的页描述符的地址。当slab子系统调用alloc_pages从buddy子系统分配到页后(上面讨论kmalloc流程的第9步)对page->lru这个字段做初始化,使得page->lru->next指向页面所在的kmem_cache,page->lru->pre指向页面所在的slab描述符。这样在调用kfree(objp)时,addr指向对象所在的kmem_cache就是{virt_to_page(objp)->lru->next},所在的slab描述符是{virt_to_page(objp)->lru->prev}.kmem_cache,slab描述符,以及其下的页面描述符具有如图(4)的关系,其中虚线双向箭头不表示指针,而是表示通过宏page_to_virt以及virt_to_page建立页描述符和页内虚拟地址之间的联系。
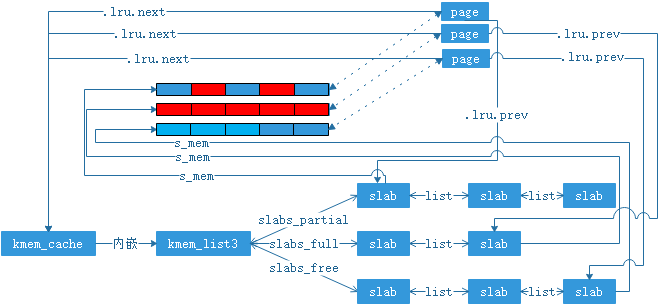
图(4)
这里解释下lru字段:linux历史上引入lru字段确实时为了实现lru算法,但是随linux发展,这个字段在不同的子系统中逐渐表示不同的意义(例如上文提到页面被slab子系统占用时,lru就指向了kmem_cache和slab描述符)。既然这样可以给lru字段取一个更科学的名字,但现实是对“lru”的引用已经遍及各个内核子系统以及各种硬件驱动,如果贸然改动,会导致驱动,以及各个内核子系统源代码不兼容,所以就一直保留到今天。所以,一个合格的工程师在起名字的时候要具有前瞻性,不可以任性。
1 struct page { 2 struct list_head lru; 3 } 4 struct list_head { 5 struct list_head *next, *prev; 6 };
为了解决第二个问题,linux在上面提到的kmem_list3的基础上又引入了两个变量,引入变量后的kmem_list3如下,针对这两个值的设定linux默认采用经验值,并导出文件到/proc,提供接口供用户根据服务器工作负荷特点调节。这两个值的调整方法以及默认值的选择机制,在后续slab性能调优章节会讲到。kfree将对象放到slab描述符下后:如果free_objects大于free_limit slab子系统认为空闲对象达到了上限,并且本次kfree调用导致当前slab描述符下的对象全部是空闲对象时,slab子系统会调用free_pages将当前slab描述符下的页面归还给buddy系统。
1 struct kmem_list3 { 2 struct list_head slabs_partial; /* partial list first, better asm code */ 3 struct list_head slabs_full; 4 struct list_head slabs_free; 5 unsigned long free_objects; 6 unsigned int free_limit; 7 }
通过上面的讨论,将kfree流程归纳如下:
1.{virt_to_page(objp)->lru->prev}得到对象所在的slab描述符:pslab,{virt_to_page(objp)->lru->next}得到对象所在的kmem_cache:pkmem_cache
2.将pslab从其所在的链表上摘下来
3.((void*) objp - pslab->s_mem)/pkmem_cache->buffer_size得到对象在slab描述符管理的“一大片”内存中的索引:index
4. {((unsigned int)(pslab+1))[index]=pslab->free; pslab->free=index;} 把对象放入pslab的静态链表
5.pslab->inuse--,pkmem_cache->kmem_list3->free_objects++
6.如果pslab->inuse !=0 pslab重新插入到pkmem_cache->kmem_list3->slab_partial链表,然后跳转到第9步
7.如果pslab->inuse == 0 且 pkmem_cache->kmem_list3->free_objects <= pkmem_cache->kmem_list3->free_limit 则将链表放入到pkmem_cache->kmem_list3->slab_free链表,然后跳转9步
8.如果pslab->inuse == 0 且 pkmem_cache->kmem_list3->free_objects > pkmem_cache->kmem_list3->free_limit 则调用free_pages(pslab->s_mem,pkmem_chache->gfporder) 将pslab中的页释放给buddy子系统。接着释放掉pslab指向的slab描述符。然后跳转到第9步
9.返回
总结:
1.objp通过virt_to_page关联到具体的页描述符page,page通过lru::next和lru::pre字段关联到具体的kmem_cache和slab.从而建立起了objp和kmem_cache,slab的映射
2.第8步点出,调用free_pages的时机,并且,同一个slab下的内存时经过一次alloc_pages被分配,相应经过一次free_pages被释放。
到此为止,介绍完了基本的kmalloc和kfree流程。上面介绍的技术,在本节的处理机模型下基本可以完整slab子系统的功能。接下来介绍linux使用的几个性能优化技术。
1.考虑系统会频繁的调用kmalloc和kfree,如果每次kmalloc和kfree都完成上文提到的所有操作,有没有办法再上文提实现的基础上,再做一个“缓冲池”,使得大部分时候kmalloc和kfree不需要执行上文提到的完整流程呢? linux为此引入新的数据结构array_cache,其结构如下,并将array_cache内嵌到kmem_cache中,新array_cache和修改后的kmem_cache如下。数据结构的关系如图(5).array_cache::entry是一个指针数组,用来存储对象地址。avail是entry数组中还有多少个对象空闲(entry数组类似“栈”,avail类似“栈顶指针”)。kmalloc首先选定kmem_cache:pkmem_cache后,做操作{obj=pkmem_cache->array->entry[--pkmem_cache->array.avail]},然后将obj(对象地址)返回即可,只有当avail等于0时,才去partial或free链表中依次取出pkmem_cache->array.batchcount个对象,并将对象地址依次填充到pkmem_cache->array.entry数组中,同时返回一个obj地址。kfree做操作{pkmem_cache->array->entry[pkmem_cache->array.avail++]=objp}同理只有pkmem_cache->array->avail>pkmem_cache->array->limit时,才依次将pkmem_cache->array->entry中pkmem_cache->array->batchcount个对象释放到partial链表。这样做的好处是:比如一个流程依次申请释放特定长度对象各10000次,假设不存在其他流程对这个长度对象kmem_cache干扰,那么理想状态下,这些申请释放是不会操作到kmem_list3的,都在array_cache中完成。
1 struct kmem_cache { 2 struct array_cache array 3 unsigned int gfporder; 4 int buffer_size; 5 struct kmem_list3 nodelists; 6 } 7 struct array_cache { 8 unsigned int avail; 9 unsigned int limit; 10 unsigned int batchcount; 11 unsigned int touched; 12 spinlock_t lock; 13 void *entry[]; 14 };
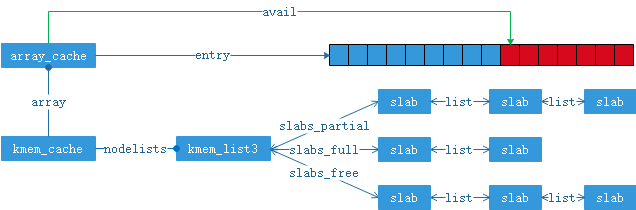
图(5)
第二个处理机模型:
1.内存是平坦的(即不存在空洞,非numa架构),内存中有DMA内存区
2.单处理器
3.Linux分页长度是4KB
4.buddy以及底层内存管理子系统为我们提供的接口不变,另外内核提供如下宏
1 #define GFP_DMA __GFP_DMA 2 #define __GFP_DMA ((__force gfp_t)0x01u) 3 typedef unsigned __bitwise__ gfp_t;
首先解释内存分区的概念:这个是linux以及硬件发展的历史结果,主要考虑到两个方面的因素,其一,历史上32位系统,linux内核虚拟地址空间只有1G。其中直接映射896MB,这部分虚拟地址空间一但系统初始化完成就和从物理地址0开始的896MB物理内存建立了简单线性映射(简单偏移)。剩下的128MB地址空间没有这种线性映射,而是可以动态的映射到任意可用的物理地址。据此,内核按虚拟地址将内存分成normal区(896MB),和highmem区(128MB).其二,由于硬件限制,历史上有些硬件在做DMA时,只能用物理地址的前16MB(是由外设地址寄存器的位宽决定,但现下这部分硬件越来越少,相信在不久的将来会消失,这样DMA区就没有存在的必要了)。为了让这部分硬件驱动和相关的核心态代码使用slab子系统和buddy子系统的接口,必须从986MB中划分出前16MB形成一个单独的内存区(DMA区)。因此32位系统下内存区有三种按地址大小依次是DMA,NORMAL和HIGHMEM。
上文提到过kmalloc的第一个参数size,始终没有提及第二个参数gfp_t flags,讨论完内存区的概念后,下面讨论flags参数中的一个bit,即GFP_DMA。如果kmalloc的调用者要求自己分配到的内存必须在DMA内存区,可以先做{flags|=GFP_DMA;}然后调用函数kmalloc(size,flags)。上文提到kmalloc是调用alloc_pages来获取页,因此buddy子系统必须也有类似的flag机制,alloc_pages的第二个如果被设置了__GFP_DMA(#define __GFP_DMA ((__force gfp_t)0x01u))那么alloc_pages返回的页一定来至DMA区,否者返回的页来至非DMA区。
上文提到将size通过算法聚集到{2^5,2^6.......2^21,2^22}中的值,然后用18个kmem_cache管理这些内存段,每一个kmem_cache管理一种长度的内存段。为了对DMA的支持,linux引入了两组kmem_cache数据结构,每组18个kmem_cache。一组专门用来管理DMA内存区中的内存段,一组用来管理非DMA内存区的内存段。为此必须更新cache_sizes数据结构,如下:
1 /* Size description struct for general caches. */ 2 struct cache_sizes { 3 size_t cs_size; 4 struct kmem_cache *cs_cachep; 5 #ifdef CONFIG_ZONE_DMA 6 struct kmem_cache *cs_dmacachep; 7 #endif 8 };
其中cs_cachep指向管理非DMA内存区中内存段的kmem_cache,而cs_dmacachep指向管理DMA内存去中内存段的kmem_cache。因此我们相应的需要更新图(1)为图(6).kmalloc调用在这种情况下需要新增如下逻辑:根据入参size,按上文说的方法选定某个cache_sizes,然后根据入参gfp_t flags选定对应的kmem_cache数据结构。
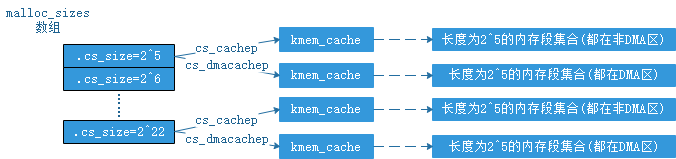
图(6)
第三个处理机模型
(这个模型就是现下linux内核面临的实际情况)
1.numa架构,并且内存中有DMA内存区
2.多处理器
3.Linux分页长度是4KB
4.buddy以及底层内存管理子系统为我们提供的接口不变
numa架构特点如下:有多颗CPU,多个内存节点,并且各个CPU访问同一个内存节点的时间可能不同,同一个CPU访问不同内存节点的时间也可能不同。因此,将CPU按内存节点(node)分组,对于特定node,将访问该node花费时间最短的一组CPU叫做该node的本地CPU,其他CPU叫做该node的非本地CPU;相应,将该node叫做对应CPU的本地内存节点,其他的node叫做对应CPU的非本地内存节点。内存节点和CPU一般是一对多的关系。
在这个模型下基于上文讨论的模型我们做如下改进:
1.对array_cache的改进
上文提到每一个size的kmam_cache都由一个中间缓存array_cache,在系统中有多颗cpu的情况下,举个例子:针对size=1024的kmem_cache,当系统中由2颗CPU的时候,第1颗cpu上运行的内核控制路径在操作array_cache时候,第2颗cpu也可能发起size=1024的kmalloc系统调用,也就有可能操作到同一个array_cache,这样这2颗cpu上执行的控制路径会在array_cache上交汇,为了array_cache数据的一致性,就必须引入自旋锁对array_cache保护。随着cpu颗数的增加。这种交汇变得很频繁,导致有些CPU因竞争自旋锁空转。
为了解决上面的问题,linux针每一个size的kmem_cache引入一个array_cache数组,数组的长度时系统中cpu的个数,这样每个size的kmalloc_cache针对系统中的每一个cpu都有一个独立的array_cache中间缓存,每一个cpu上的控制路径访问自己独自的array_cache数据结构,也就没有必要再引入自旋锁。改进后kmem_cache,array_cache,以及cpu的关系如图(7),数据结构如下文程序段:
1 struct kmem_cache { 2 struct array_cache *array[NR_CPUS]; 3 unsigned int gfporder; 4 int buffer_size; 5 struct kmem_list3 nodelists; 6 } 7 struct array_cache { 8 unsigned int avail; 9 unsigned int limit; 10 unsigned int batchcount; 11 unsigned int touched; 12 spinlock_t lock; 13 void *entry[]; 14 };

图(7)
2.对kmem_list3的改进
当系统中有多个node的时候,我们期望达到的目标是,当某颗cpu上的控制路径需要发启了kmalloc系统调用时,我们希望kmalloc申请到的内存优先在该cpu的本地内存节点分配,如果本地内存节点不能满足时,才到当前cpu的非本地节点分配。
为了对kmalloc分配出来的对象所来至的node做更精细的控制,对上文提到的kmem_cache中内嵌的kmem_list3做扩展,将内嵌的kmem_list3扩展成kmem_list3数组,数组的长度时当前系统中内存节点的个数,扩展后的kmem_cache和kmem_list3的关系如图(8),以及内核数据结构代码片段如下:
1 struct kmem_cache { 2 struct array_cache *array[NR_CPUS]; 3 unsigned int gfporder; 4 int buffer_size; 5 struct kmem_list3 *nodelists[MAX_NUMNODES]; 6 }
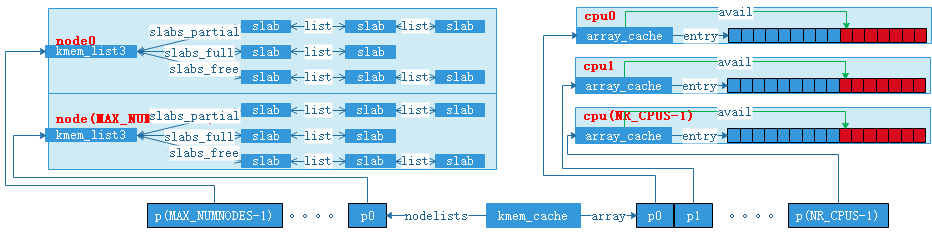
图(8)
3.kmem_list3和array_cache的关系
内核会根据各个CPU的负载进行负载均衡,有可能进程1在cpu1上发起了一组size=1024的kmalloc,假设cpu1属于node1.并且分配到的对象都来至node1,可是运行一段时间进程1被迁移到其他cpu2运行了,假设cpu2属于node2,这时进程1调用了kfree将以前申请到的对象释放掉。