链接:https://www.zhihu.com/question/37082800/answer/126430702
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:循环神经网络RNN打开手册 - 混沌巡洋舰 - 知乎专栏
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
最近朋友前小伙伴都已经传播疯了的谷歌翻译,实现了令人惊艳的性能。这里的技术核心, 就是RNN- 我们常说的传说中的循环神经网络。 RNN可以称得上是深度学习未来最有前景的工具之一。 你想了解它的威力的根源吗? 你想知道一些最新的RNN应用?请看下文。
为什么RNN会有如此强大的效力? 让我们从基础学起。首先, 要看RNN和对于图像等静态类变量处理立下神功的卷积网络CNN的结构区别来看, “循环”两个字,已经点出了RNN的核心特征, 即系统的输出会保留在网络里, 和系统下一刻的输入一起共同决定下一刻的输出。这就把动力学的本质体现了出来, 循环正对应动力学系统的反馈概念,可以刻画复杂的历史依赖。另一个角度看也符合著名的图灵机原理。 即此刻的状态包含上一刻的历史,又是下一刻变化的依据。 这其实包含了可编程神经网络的核心概念,即, 当你有一个未知的过程,但你可以测量到输入和输出, 你假设当这个过程通过RNN的时候,它是可以自己学会这样的输入输出规律的, 而且因此具有预测能力。 在这点上说, RNN是图灵完备的。

图: 图1即CNN的架构, 图2到5是RNN的几种基本玩法。图2是把单一输入转化为序列输出,例如把图像转化成一行文字。 图三是把序列输入转化为单个输出, 比如情感测试,测量一段话正面或负面的情绪。 图四是把序列转化为序列, 最典型的是机器翻译, 注意输入和输出的“时差”。 图5是无时差的序列到序列转化, 比如给一个录像中的每一帧贴标签。 图片来源 The unreasonable effective RNN。
我们用一段小巧的python代码让你重新理解下上述的原理:
classRNN:
# ...
def step(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return y
这里的h就是hidden variable 隐变量,即整个网络每个神经元的状态,x是输入, y是输出, 注意着三者都是高维向量。隐变量h,就是通常说的神经网络本体,也正是循环得以实现的基础, 因为它如同一个可以储存无穷历史信息(理论上)的水库,一方面会通过输入矩阵W_xh吸收输入序列x的当下值,一方面通过网络连接W_hh进行内部神经元间的相互作用(网络效应,信息传递),因为其网络的状态和输入的整个过去历史有关, 最终的输出又是两部分加在一起共同通过非线性函数tanh。 整个过程就是一个循环神经网络“循环”的过程。 W_hh理论上可以可以刻画输入的整个历史对于最终输出的任何反馈形式, 这是RNN强大的关键。
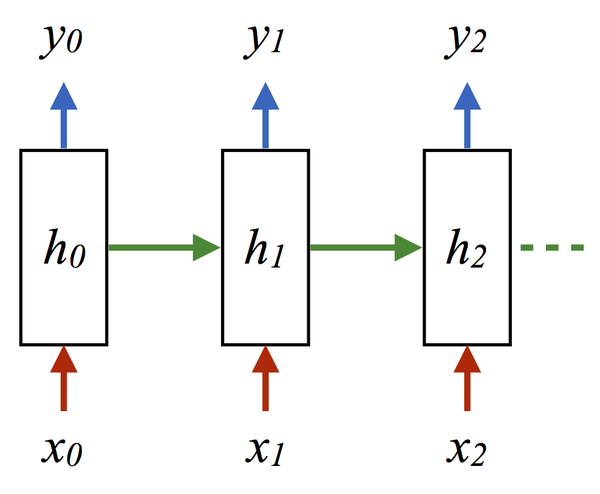
那么CNN似乎也有类似的功能? 那么CNN是不是也可以当做RNN来用呢? 答案是否定的,RNN的重要特性是可以处理不定长的输入,得到一定的输出。当你的输入可长可短, 比如训练翻译模型的时候, 你的句子长度都不固定,你是无法像一个训练固定像素的图像那样用CNN搞定的。而利用RNN的循环特性可以轻松搞定。
RNN的本质是一个数据推断(inference)机器, 它可以寻找两个时间序列之间的关联, 只要数据足够多,就可以得到从x(t)到y(t)的概率分布函数, 从而达到推断和预测的目的。 这里我们无疑回想到另一个做时间序列推断的神器- HMM, 隐马尔科夫模型, 在这个模型里, 也有一个输入x和输出y,和一个隐变量h, 而这的h和刚刚的RNN里的h区别是迭代法则, 隐马通过跃迁矩阵把此刻的h和下一刻的h联系在一起。跃迁矩阵随时间变化, 而RNN中没有跃迁矩阵的概念,取而代之的是神经元之间的连接矩阵。 HMM本质是一个贝叶斯网络, 因此每个节点都是有实际含义的,而RNN中的神经元只是信息流动的枢纽而已,并无实际对应含义。两者还是存在千丝万缕的联系, 首先隐马能干的活RNN几乎也是可以做的,比如语言模型,但是就是RNN的维度会更高。在这些任务上RNN事实上是用它的网络表达了隐马的跃迁矩阵。在训练方法上, 隐马可以通过类似EM来自最大后验概率的算法得出隐变量和跃迁矩阵最可能的值。 而RNN可以通过一般的梯度回传算法训练。
那么我们看一些RNN处理任务的具体案例吧:
比如说, 学说话! 如何叫计算机说出一段类似人话的东西呢?
此处我们从一个非常具体的程序讲起, 看你如何一步步的设计一个程序做最简单的语言生成任务,这个任务的目标类似是让神经网络做一个接龙, 给它一个字母,让它猜后面的, 比如给它Hell, 它就跟着街上o。 示意图如下:
data = open('input.txt', 'rw').read() # should be simple plain text file
chars = list(set(data)) # vocabulary
data_size, vocab_size = len(data), len(chars)
print 'data has %d characters, %d unique.' % (data_size, vocab_size)
char_to_ix = { ch:i for i,ch in enumerate(chars) } # vocabulary
ix_to_char = { i:ch for i,ch in enumerate(chars) } # index
首先我们把字母表达成向量,用到一个叫enumerate的函数, 这如同在构建语言的数字化词典(vocabulary), 在这一步之后, 语言信息就变成了数字化的时间序列
hidden_size = 100 # size of hidden layer of neurons
seq_length = 25 # number of steps to unroll the RNN for
learning_rate = 1e-1
# model parameters
Wxh = np.random.randn(hidden_size, vocab_size)*0.01 # input to hidden
Whh = np.random.randn(hidden_size, hidden_size)*0.01 # hidden to hidden
Why = np.random.randn(vocab_size, hidden_size)*0.01 # hidden to output
bh = np.zeros((hidden_size, 1)) # hidden bias
by = np.zeros((vocab_size, 1)) # output bias
下一步我们要初始化三个矩阵,即W_xh, W_hh,W_hy 分别表示输入和隐层, 隐层和隐层, 隐层和输出之间的连接,以及隐层和输出层的激活函数中的bias( bh和by):
Loss=[ ]
Out=[ ]
while True:
# prepare inputs (we're sweeping from left to right in steps seq_length long)
if p+seq_length+1 >= len(data) or n == 0:
hprev = np.zeros((hidden_size,1)) # reset RNN memory
p = 0 # go from start of data
inputs = [char_to_ix[ch] for ch in data[p:p+seq_length]]
targets = [char_to_ix[ch] for ch in data[p+1:p+seq_length+1]]
下一步是正是开始程序, 首先准备输入:
# sample from the model now and then
if n % 100 == 0:
sample_ix = sample(hprev, inputs[0], 200)
txt = ' '.join(ix_to_char[ix] for ix in sample_ix)
print '---- %s ----' % (txt, )
这一步要做的是每训练一百步看看效果, 看RNN生成的句子是否更像人话。 Sample的含义就是给他一个首字母,然后神经网络会输出下一个字母,然后这两个字母一起作为再下一个字母的输入,依次类推:
# forward seq_length characters through the net and fetch gradient
loss, dWxh, dWhh, dWhy, dbh, dby, hprev,y = lossFun(inputs, targets, hprev)
smooth_loss = smooth_loss * 0.999 + loss * 0.001
if n % 100 == 0: print 'iter %d, loss: %f' % (n, smooth_loss) # print progress
这一步是寻找梯度, loss function即计算梯度 , loss function的具体内容关键即测量回传的信息以供学习。函数内容再最后放出
最后一步是根据梯度调整参数的值,即学习的过程。
# perform parameter update with Adagrad
for param, dparam, mem in zip([Wxh, Whh, Why, bh, by],
[dWxh, dWhh, dWhy, dbh, dby],
[mWxh, mWhh, mWhy, mbh, mby]):
mem += dparam * dparam
param += -learning_rate * dparam / np.sqrt(mem + 1e-8) # adagrad update
p += seq_length # move data pointer
n += 1 # iteration counter
Loss.append(loss)
Out.append(txt)
这就是主程序,没错, 就是这么简单, 刚刚省略的loss function 如下:
def lossFun(inputs, targets, hprev):
"""
inputs,targets are both list of integers.
hprev is Hx1 array of initial hidden state
returns the loss, gradients on model parameters, and last hidden state
"""
xs, hs, ys, ps = {}, {}, {}, {}
hs[-1] = np.copy(hprev)
loss = 0
# forward pass
for t in xrange(len(inputs)):
xs[t] = np.zeros((vocab_size,1)) # encode in 1-of-k representation
xs[t][inputs[t]] = 1
hs[t] = np.tanh(np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t-1]) + bh) # hidden state
#Whh*hs-->Whh*y_syn*hs; y_syn[t+1]=MishaModel(y_syn[t],tau,U,hs) xe*xg(t)
ys[t] = np.dot(Why, hs[t]) + by # unnormalized log probabilities for next chars
ps[t] = np.exp(ys[t]) / np.sum(np.exp(ys[t])) # probabilities for next chars
loss += -np.log(ps[t][targets[t],0]) # softmax (cross-entropy loss)
# backward pass: compute gradients going backwards
dWxh, dWhh, dWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why)
dbh, dby = np.zeros_like(bh), np.zeros_like(by)
dhnext = np.zeros_like(hs[0])
for t in reversed(xrange(len(inputs))):
dy = np.copy(ps[t])
dy[targets[t]] -= 1
# backprop into y. see CS231n Convolutional Neural Networks for Visual Recognition if confused here
dWhy += np.dot(dy, hs[t].T)
dby += dy
dh = np.dot(Why.T, dy) + dhnext # backprop into h
dhraw = (1 - hs[t] * hs[t]) * dh # backprop through tanh nonlinearity
dbh += dhraw
dWxh += np.dot(dhraw, xs[t].T)
dWhh += np.dot(dhraw, hs[t-1].T)
dhnext = np.dot(Whh.T, dhraw)
for dparam in [dWxh, dWhh, dWhy, dbh, dby]:
np.clip(dparam, -5, 5, out=dparam) # clip to mitigate exploding gradients
return loss, dWxh, dWhh, dWhy, dbh, dby, hs[len(inputs)-1],ys
让我们看看RNN得到的一些训练结果,训练素材是网上随便找的一小段莎剧评论文章:
期初一些乱码:
T. TpsshbokKbpWWcTxnsOAoTn:og?eu l0op,vHH4tag4,y.ciuf?w4SApx? eh:dfokdrlKvKnaTd?bdvabr.0rSuxaurobkbTf,mb,Htl0uma4HHpeas n4ub::wslmpscsWmtm?xbH us:HOug4nvdWS4nil hTkbH Smeu wo0tocvTAfyuvme0vihkpviiHT0:
过一会开始有一些单词模样的东西出来, 甚至有Shakespear:
am Shakespeare brovid thiais on an 4iwpes cis oets, primarar Sorld soenth and hathiare orthispeathames ses, An ss porkssork. utles thake be ynlises hed and porith thes, proy ditsor thake provf provrde
最后已经像是人话了,那真的是人模狗样的句子啊,以至于让我猜测它是不是开始思考了,也就是训练了半小时样子:
of specific events in his life and provide little on the person who experis somewhat a mystery. There are two primary sources that provide historians with a basic outline of his life…
语言结构通过神经网络可以从一堆乱码中涌现出来, 这正是目前机器翻译的state of the art SMT(统计机器翻译)的基础, 下面让我们了解一下大明明鼎鼎的google翻译又是用了哪些炫技。 首先google翻译的基础正是这个游戏般容易, 却思想内容极为深刻的RNN。 但是这里却做了若干步变化。 这里要提到RNN的一个变种LSTM。
LSTM(Long short term memory)顾名思义, 是增加了记忆功能的RNN, 首先为什么要给RNN增加记忆呢? 这里就要提到一个有趣的概念叫梯度消失(Vanishing Gradient),刚刚说RNN训练的关键是梯度回传,梯度信息在时间上传播是会衰减的, 那么回传的效果好坏, 取决于这种衰减的快慢, 理论上RNN可以处理很长的信息, 但是由于衰减, 往往事与愿违, 如果要信息不衰减, 我们就要给神经网络加记忆,这就是LSTM的原理了。 这里我们首先再增加一个隐变量作为记忆单元,然后把之前一层的神经网络再增加三层, 分别是输入门,输出门,遗忘门, 这三层门就如同信息的闸门, 控制多少先前网络内的信息被保留, 多少新的信息进入,而且门的形式都是可微分的sigmoid函数,确保可以通过训练得到最佳参数。
信息闸门的原理另一个巧妙的理解是某种“惯性” 机制,隐变量的状态更新不是马上达到指定的值,而是缓慢达到这个值, 如同让过去的信息多了一层缓冲,而要多少缓冲则是由一个叫做遗忘门的东西决定的。 如此我们发现其实这几个新增加的东西最核心的就是信息的闸门遗忘门。 根据这一原理,我们可以抓住本质简化lstm,如GRU或极小GRU。 其实我们只需要理解这个模型就够了,而且它们甚至比lstm更快更好。
我们看一下最小GRU的结构:
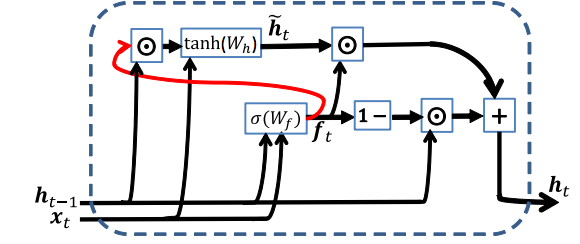
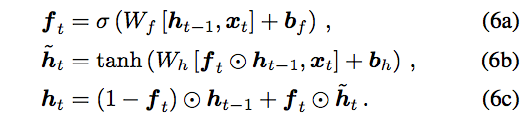
摘自论文: Minimal Gated Unit for Recurrent Neural Networks
第一个方程f即遗忘门, 第二方程如果你对比先前的RNN会发现它是一样的结构, 只是让遗忘门f来控制每个神经元放多少之前信息出去(改变其它神经元的状态), 第三个方程描述“惯性” ,即最终每个神经元保持多少之前的值,更新多少。
这个结构你理解了就理解了记忆体RNN的精髓。
好了是时候看一下google 翻译大法是怎么玩的, 首先,翻译是沟通两个不同的语言, 而你要这个沟通的本质是因为它们所表达的事物是相同的, 我们自己的大脑做翻译的时候,也是根据它们所表达的概念相同比如苹果-vs-apple来沟通两个语言的。如果汉语是输入,英语是输出,神经网络事实上做的是这样一件事:
Encoding: 用一个LSTM把汉语变成神经代码
Decoding:用另一个LSTM把神经代码转化为英文。
第一个lstm的输出是第二个lstm的输入, 两个网络用大量语料训练好即可。 Google这一次2016寄出的大法, 是在其中加入了attention机制 ,这样google的翻译系统就更接近人脑。

运用记忆神经网络翻译的核心优势是我们可以灵活的结合语境,实现句子到句子,段落到段落的过度, 因为记忆特性使得网络可以结合不同时间尺度的信息而并非只抓住个别单词, 这就好像你能够抓住语境而非只是望文生义。也是因为这个RNN有着无穷无尽的应用想象力, 我们将在下一篇继续讲解google翻译以及rnn的各种应用。
参考文献 :
The unreasonable effective RNN
Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Minimal Gated Unit for Recurrent Neural Networks