1 简单扩展
"jump,hop,leap"
搜索jump会检索出包含jump、hop或leap的词
1.1 扩展应用在索引阶段
1.2 扩展应用在查询阶段
1.3 对比

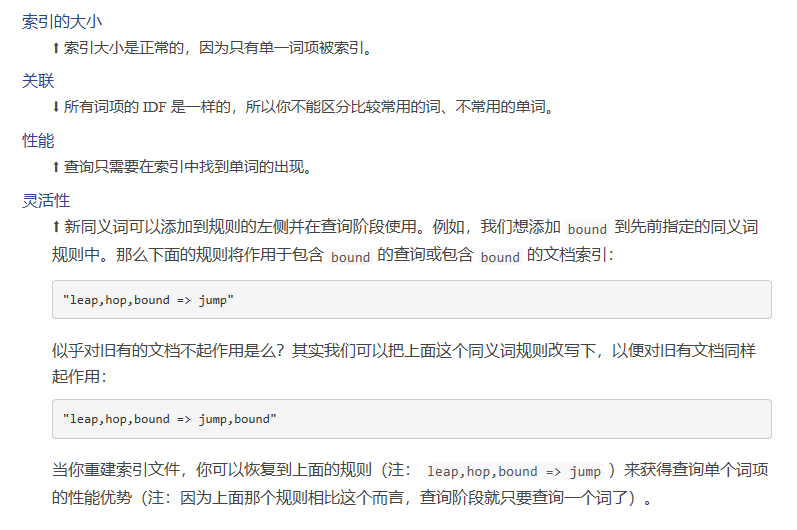
2 简单收缩
把左边的多个同义词映射到了右边的单个词:
"leap,hop => jump"
必须同时应用于索引和查询阶段,以确保查询词项映射到索引中存在的同一个值。
优缺点:
3 类型扩展
"cat => cat,pet",
"kitten => kitten,cat,pet",
"dog => dog,pet"
"puppy => puppy,dog,pet"
如第一行,所有包含cat的文档ID会被索引到倒排索引cat和pet里面。
注意,右边扩大了左边词的的范围。因此,倘若你在索引和查询阶段都使用类型扩展,当你搜索某个词(如cat)的时候,由于cat的IDF值就是cat本来的IDF值,pet的IDF值会比实际上pet的IDF值偏小,因此,包含cat的文档的分数会比包含pet的文档,因而排在更前面。
4 注意
4.1 PET->pet词义变化
经过lowercase过滤器后,包含PET(正电子发射断层扫描)的文档ID会被索引到倒排索引pet中。
解决方案:
在lowercase过滤器之前,利用使用一层同义词词汇单元过滤器,将特殊的单词转化为特殊的词单元,如:
"CAT,CAT scan => cat_scan"
"PET,PET scan => pet_scan"
"Johnny Little,J Little => johnny_little"
"Johnny Small,J Small => johnny_small"
经过lowercase过滤器之后,在进行一次常规的同义词词汇单元过滤器,如:
"cat => cat,pet"
"dog => dog,pet"
"cat scan,cat_scan scan => cat_scan"
"pet scan,pet_scan scan => pet_scan"
"little,small"
4.2 短语查询
如果同义词中有短语词组,如:
"usa,united states,u s a,united states of america"
一定要在分词之前,使用词义收缩,否则会造成严重不匹配(原因)
"united states,u s a,united states of america=>usa"
这个方法的缺点是,因为把 united states of america 转换成了同义词 usa, 你就不能使用 united states of america 去搜索出 united 或者 states 。 你需要使用一个额外的字段并用另一个解析器链来达到这个目的。
4.3 符号同义词
符号表情能够很好地表示语义。为了在分词过程中损失掉这部分信息。可以通过映射字符过滤器将表情符号转化为一个表示它的特殊同义词。如,
":)=>emoticon_happy"