1、摘要
大多数编码器-解码器框架在预测当前词时严重依赖之前生成的词,这样的方法不能有效地利用未来预测到的信息去学习完整的语义。这篇文章提出了Context-Aware Auxiliary Guidance(CAAG)机制,它可以指导模型掌握全局上下文的信息,CAAG利用语义注意力有选择性地关注全局上下文信息去生成当前的单词。
2、介绍
最大似然估计的训练方法会造成暴露偏差,后来的工作中提出了RL算法来解决这个问题,它通过直接优化不可微序列级别的指标。
当前图像字幕的方法在进行当前词预测的时候只依赖之前生成的单词,这会导致模型没有学到完全的语义信息,而未来预测的单词可能对当前预测的词具有更多关键的信息,所以在预测当前词的时候应该也考虑未来预测词的信息。
为了更好地理解图片信息,提出了CAAG机制。首先使用字幕模型(称为主要网络)生成一个完整的句子,被当做全局的上下文。基于这个全局上下文以及隐藏状态,CAAG通过语义注意力重新生成目标词,语义注意力可以帮助CAAG有选择性地利用以前预测单词的信息或者未来预测单词的信息。
文章的主要贡献:1.提出了CAAG机制,利用未来预测词的信息指导模型掌握更完全的语义信息。
2.这个模型是通用的,可以与现在存在的基于强化学习的模型结合起来。
3.模型在COCO数据集上超过了很多SOTA模型。
3、架构
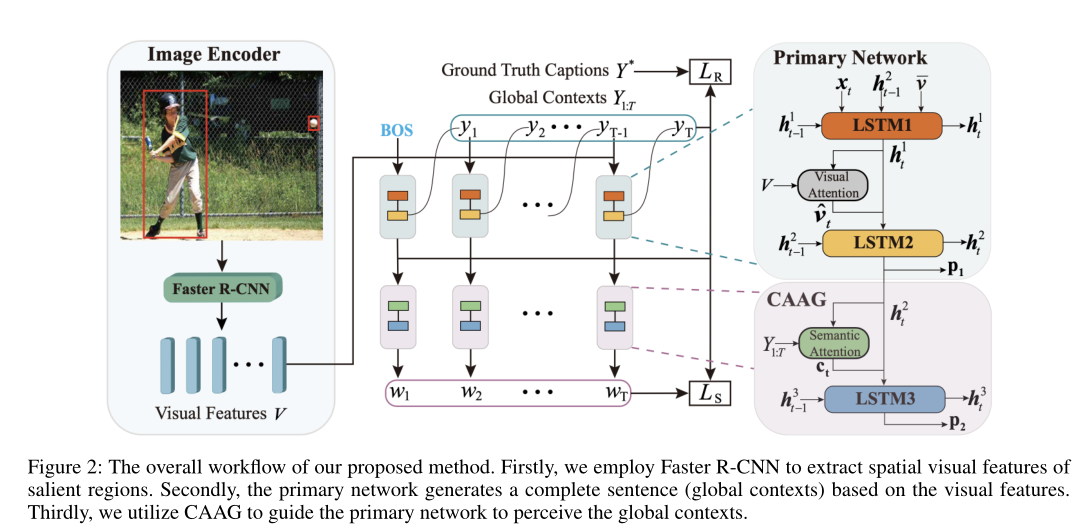
首先用在Visual Genome数据集上预训练的Faster R-CNN抽取图片上显著区域的空间视觉特征,然后基于这些视觉特征使用主要网络生成全局上下文,最后使用CAAG指导主要网络掌握全局上下文信息。