1、摘要
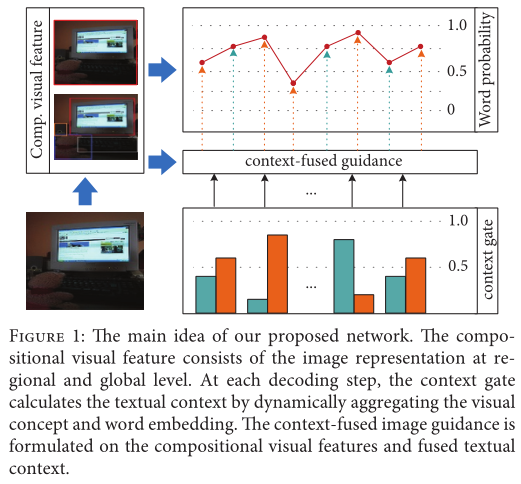
编码器与解码器的分离导致了图片和句子间关系的断连,最终生成的字幕只包含主要的实例但是意外地忽视了其他的物体和场景。为了解决这个问题,本文提出了一个上下文融合指导的图片字幕生成系统,它将局部和全局的图片表示作为合成的视觉特征去学习图片中的物体及其属性;为了整合图片级别的语义信息,采用了visual concept;通过有选择性地融合visual concept和词嵌入的信息,上下文融合门控机制被引入来计算文本上下文。上下文融合指导模型就是基于合成的视觉特征和文本上下文。除此之外,为了解决暴露偏差,本文还使用sequence decision-making训练模型。
2、编码器-解码器框架需要关心的问题
从计算机视觉角度来看,视觉证据对解码器并不总是必不可少的,因为描述的句子通常包含对应于视觉特征的显著物体。解码器与编码器的分离通常导致了特征向量和生成字幕之间的断连。考虑到图片区域中的实例在词汇表中没有对应的词汇,所以提出了visual concept,visual concept是一组描述显著图像对象的常用词汇,它从区域级别加强了图片和文本之间的联系。
用MLE训练模型可能会导致暴露偏差的问题,为了解决这个问题,引入了RL策略。但是由于梯度估计的高方差,并不能直接使用RL策略训练模型。Self-critical sequence training框架通过序列级别的训练来使用RL策略,在推理阶段,SCST使用已生成的样本作为基准来正则化奖励,然后网络使用不可微的序列级别标准(eg,CIDEr)来评估语言质量而不是使用词级别的交叉熵损失。
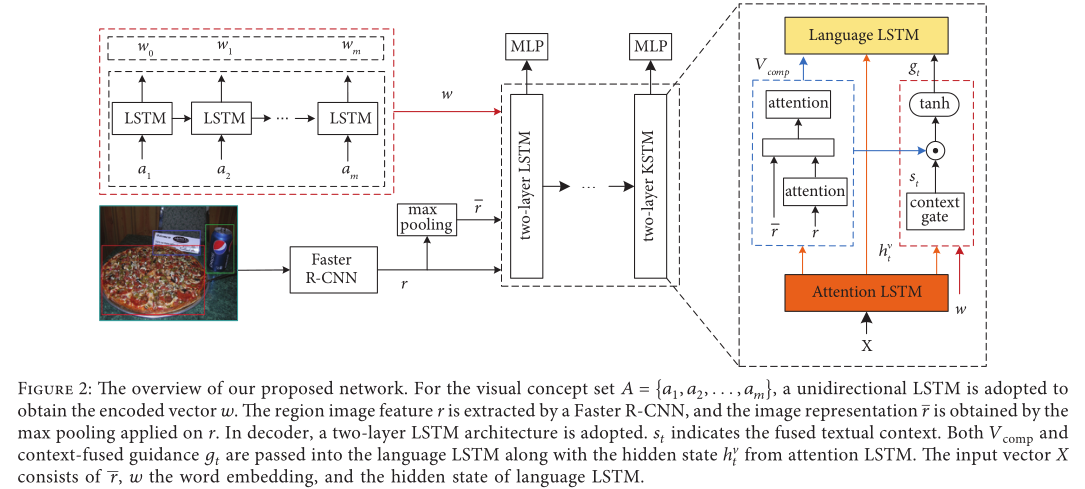
3、模型
CFG模型利用合成的视觉特征来进行多级别的图像学习,通过上下文融合门控机制,CFG自适应地结合visual concept和词嵌入。
4、实验结果
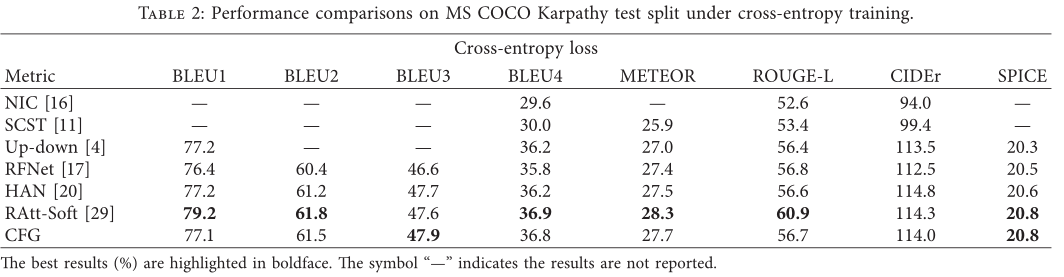
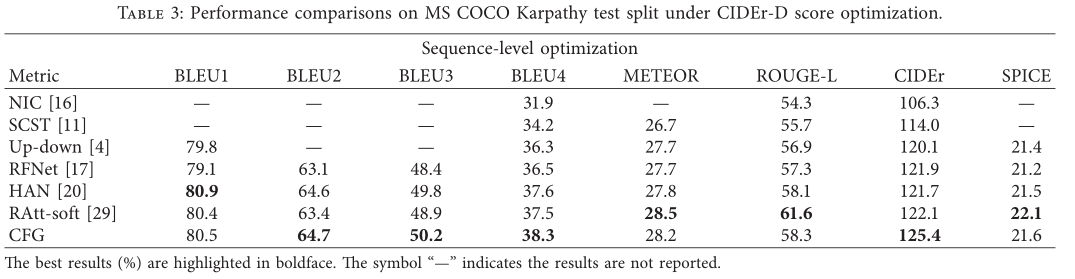
实验结果表明,模型通过利用合成的视觉特征和上下文融合的图片指导能够改善字幕表现,但是在SPICE上的得分并不高,这是本文模型需要改进的地方。
实验结果还表明本文模型不能充分准确地推断出物体之间的关系,特别是图片中有多个物体的时候,一个可能的解决方案是引入场景图,它含有丰富复杂的图片和句子的结构表示。