Python
概述
简介
-
python是一种解释性,面向对象,动态数据类型的高级程序语言,
-
解释型,无编译过程,逐行解释为二进制
-
交互性,直接执行程序
-
应用广泛,
-
编译型:
特点
-
易于学习
-
易于维护
-
易于阅读
-
广泛的标准库
-
互动模式
-
可移植
-
可扩展:兼容c语言,可调用
-
数据库
-
GUI编程
-
可嵌入,c调python
缺点
-
运行慢:代码一行一行翻译成CPU理解的机器码运行,即一行一行运行,很慢;
而C语言直接翻译后成执行的机器码,很快
编程任务:
io型:复制,打开网页,所以说虽然速度慢,依然使用它
计算型:数据计算,用c 快
-
代码不能加密:只能发布源代码,不能编译
-
没有多线程
Python分类
推荐cpython, py->c语言的字节码->0000010101
jypython, py->java的字节码
ironpython,
其他语言的python
pypy, 一次性编译为py的字节码,速度快,开发效率相对低-->0101
这只是python解释器的分类,python语法规范相同
#-*- encoding:utf-8 -*-
# coding=utf-8 都可以
print("段志方")
#python2不支持中文默认是ascii
variable
字母数字下划线,空格不行,中文可以(但不要这样) 同java
a=12
b=a
c=b
b=100
print(a,b,c)->12,100,12
因为逐行执行
注释
单行注释:# 读,但不运行
多行注释:'''xxxx''' 或"""xxxx"""
数据交互,input
name=input("xxxx")
type(name)->str 全是字符串
数据类型
-
数字 type(100) -><class 'int'>
int
-
范围根据电脑变化 -2^31~2^31-1 32位
-
64位 31 换63即可
long 长整型
python3中没有全是int
python2中有
-
-
字符串str:单引双引
可相加,可相乘 与数字
"段志方"*8
msg='''
xxx
yyy
zzz
'''也可三个双引号
-
bool 布尔值:首字母大写
此时不是注释,里面格式不变
与字符串转换
空串为false
否则为true
与list,元祖,只要是空都是False
-
list:类型可不一致,储存大量数据
-
元组(只读列表):(1,2,3,"xxx")可存任何数据
-
字典dict:键值对 {"name":"段志方","age":21}也可大量数据,不限类型
如列表中有列表时可用lis[x][y]取出
-
集合:{1,2,3,"xxx"} 可求交集,差集
条件语句
if 条件:
4空格或tab 但不要混用
if True:
print(1)
print(2)
#都打印
if True:
xxx
else:
yyy
if a :
elif b :
elif c:
else:
while
#break continue 照样适用
while True:
print()
while .... else
正常执行完毕会执行else
被break打断不会执行else
count = 0
while count < 5:
count += 1
print(count)
break
else:
print("while->else")
for循环
s=字符串,列表等可迭代元素
for i in s:
print(i)
if "xxx" in s:
pass
not in
字符串与数字转换
str='1'
b=int(str) b变为int
str(int) 数字转换为字符串
格式化输出
转义字符是"%" %%表示正常输出%
#格式化输出
#% s d
name = input("input your name:")
age = input("input your age:")
height = input("input your height:")
msg = "My name is %s, I'm %s years old,%scm tall" % (name, age, height)
msg2 = '''-----------------------------
name:%s
age:%s
height:%s
-----------------------------
''' % (name, age, height)
print(msg)
print(msg2)
编码
ascii 初期 包含字符少只有7位 预留了第一位全为0
unicode
最开始
1字节表示所有英文,数字,特殊符号
2字节表示中文 ,不够,
后来全部使用32位表示英文与中文都是
升级->utf-8(一个字符最少8位) utf16 同理
中文3字节
英文1字节
欧洲文字2字节
gbk 中文2字节
英文1个字节
文件的储存与传输不能是unicode,只能是其他的几种
py3:str在内存中是使用unicode编码的,所以文件存取要转换
bytes类型 编码方式 ascii,utf-8,gbk等
所以str直接存储到文件传输,不可以
英文
str:表现方式 s="dzf“
编码方式 unicode 00001000 ...
bytes 表现方式 s=b"dzf"
编码 gbk 01000001...
中文
str同上
bytes表现方式=b"xe1xd5xa5" 3个字节表示
s="dzf".encode("utf-8") 为bytes类型 (将dzf转为bytes类型,utf-8编码方式)
s="段志方".encode("utf-8")->b'xe6xaexb5xe5xbfx97xe6x96xb9'
运算符
+,-,**,/ ,//
逻辑运算符(数字比较时想象为true,false即可)
注意没有"||" "&&"
&表示位运算符 当数字&时 与and不同 表示的是二进制相与
()>not >and >or
x or y
x为非零(真) 结果为x
x为零(假) 结果为 y
数字与bool可直接比较
x and y
x不为0 返回y
x为0 返回 x
int(True)=1
bool(1)=True
字符串常用操作方法
字符串切片
s[n]获取索引n的字符
获取一段s[m:n]字符串切片,顾头不顾尾
s[-1]从后向前
s[-2:-5] 从后向前
s[0:-1]不包含最后一个
s[:]=s[0:]全部
s[n:n]空
s[0:10:2]0到10内每隔2个取一个
s[4:0:-2]倒着取,没2个取一个
注意不能s[4:0]
str.capitalize() 首字母大写 数字无影响
upper() 全部大写
lower()全部小写
swapcase()大小写反转
title() "dzf非英文zbcd"->"Dzf非英文Zbcd"
center(n,"#")设置字符串长度为n,两边#填充 居中显示
expandtabs() 补全空格
startswith("xxx")是否已xxx开头
startswith("e",2,5)2到5组成的字符串是否已e开头
find("x")返回第一个x下标 找不到返回-1
index() 与find功能相同,但找不到会报错
strip()去掉前后空格,也可以去掉换行符中间的不处理
strip("%#@"):包含空格不管前后只要有其中的某个,即删除
lstrip,rstrip 同理
count("z",1,56)返回1-56中z出现的次数
spilt()分割 返回列表 空已包含
format 格式化输出
s="你是{},今年{},爱好{},我是{}".format("xxx",21,"yy","xxx")
s="你是{0},今年{1},爱好{2},我是{0}".format("xxx",21,"yy")
s="你是{name},今年{age},爱好{like},我是{name}".format(name="xxx",age=21,like="yy")
replace("old","new",count) old->new 替换count次
isdight() 全部是数字
isalpha()全部是字母
isalnum()全部是数字,字母
公共方法
len(str) 返回字符个数,英文,中文都表示个字符
int
bit_length() 转换为2进制最少的位数
列表(有序)32位5亿多个
排序 list.sort(),最快排序 list.sort(reverse=True)倒序 list.reverse()翻转 增删改查 增 list.append(object)增加到最后 无返回值 list.insert(3,object)指定位置插入 list.extend("DZF")最后插入(可迭代的对象:字符串。列表等) ->['D','Z','F'] 删 list.pop(1) 指定删除 有返回值:值 默认删最后一个 list.remove("xx")无返回值 list.clear()清空 del list 删除列表 del list[0:2] 切片删除 改 list[0]=[1,2,3] list[0]="dzf" list[0:2]="xxxx"切片插入都是按照迭代插入即x,x,x,x 查 for i in list: li[0:2]
列表的循环
列表的嵌套:list = ["dzf","工藤新一",[1,2,3],]
元祖,只读列表,可循环查询,可切片
儿子不能改,孙子可能可以改
zu=(1,2,3,4,[1,2,3,4])
zu不能改,但里边的列表可以改
a.join(可迭代元素x) 返回的是x中的每一个用a隔开:返回连接后字符串,列表的话就是拼接后返回
range 顾头不顾尾
for i in range(0,100):
for i in range(0,100,2)步长2
for i in range(10,0,-1)倒序
字典dict
数据类型:
可变数据类型:list,dict ,set 不可哈希
不可变数据类型:元祖,bool,int,str 可哈希
dict key 必须为不可变数据类型
dict value 任意类型
二分查找,存储关系型数据,好像无序,版本有关
-
增:dict["newKey"]=xxxx
dict.setdefault("xxx")添加"xxx":None
dict.setdefault("xxx","yyy") 若存在xxx的话不做操作
-
改:dict["oldKey"]=xxxx
dict1.update(dict2) dict1的所有添加到dict2 有覆盖,无添加
-
删:
dict.pop("key") 返回value
dict.pop("不存在键")报错
dict.pop("不存在键",XXX)不报错,若有删除,若无,返回xxx
dict.popitem():3.6以上默认删除最后一个,3.5版本是随机删除(好像是)
返回的是元祖形势的("key","value")
del dict["key"] #无返回值
del dict["不存在键"]#错误
del dict #delete the dict 打印报错
dict.clear() clear 打印不报错
-
查
dict.keys() 返回的是<class 'dict_keys'> 当做list就行 key列表,list(dict.keys())转换
dict.values() 同上
dict.items()同上 items列表 item是一个key-value元祖
dict可循环默认为key
i in dict ==dict.keys()
dict.items() ->每个元祖(key,value) 不美观
a,b=1,2
a,b=[1,2]
a,b分别为1和2
a,b=[1,2],[1,2]:分别为2个list
#一行交换,python专有
a,b=b,a
for k,v in dict.items():
print(k,y)
dict[key]=value key不存在会报错
dict.get(key,xxx)=value 不存在=None或自定义值
循环
for i in str 循环中改变str实际次数不变
in list 等可变类型 会发生改变
列表循环时可以删除
dict不可以
进阶
"=" 赋值运算,传递内存
== 比较是否相等
is 比较内存
id(obj) 对象的内存
i=6 j=6 id(i)=id(j) #若为300 则不相等与java类似 #数字,字符串小数据池,其他没有小数据池 #数字范围 -5到256 #字符串范围:不知道确切范围,规律: #(不含有特殊字符 则id相同,否则就不同) #str*20 相同 str*21 不同
元祖中只有一个元素t=([1]) 此时t是list类型
t2=([1],) 此时是元祖类型
集合及深浅copy
-
可变的数据类型
-
里边的元素必须不可变
-
无序
-
不重复
set1=set({1,2,3}) set2={1,2,3,4,5,6} #add set1.add("dzf") set.update("abc")->{1,2,3,"a","b","c"} #delete set1.pop() 随机删除,并返回删除的元素 set1.remove("xxxx")按元素删除,若不存在报错 set1.clear() ->set()空集合 del set1 删除整个集合 #update 因为是不可变数据类型,切无序,不能更改 #select for i in set1: pass #顺序变化 #可以求 #交 set1 & set2 set1.intersection(set2) #反交集 set1 ^ set2 set1.symmetric_difference(set2) #并 set1 | set2 set1.union(set2) #差set1独有的 set1-set2 #子集 set1>set2 #当set2是set1子集时返回True 1是2的超集 set1<set2 #1是2的子集 # set1 = set(list) #转换list为set 去重 # s =frozenset(set2) #转化为不可变数据类型,此时s不能更改文件操作
root,dirs,files = os.walk(path)
# file option """ 1,path 2,charset 3,privileges """ # mode = "r" encoding="utf8" utf8是文件建立时的编码方式 # mode = "rb" 不用指定,以文件建立时的方式打开,用以非文字文件 # mode = "w" encoding="utf8" wirte only # mode = "wb" 直接写入byte类型 不用编码方式,f.write("xxxx".encode("utf8")) # mode = "a" encoding = "utf8" 追加方式 # mode = "ab" 追加方式f.write("xxxx".encode("utf8")) # mode = "r+" 可读可写(等于追加) 读写是由mode决定光标位置,从光标处开始操作 # mode = "r+b" # mode = "w+" 先清除后再写,并无意义 # mode = "a+" 写 读 # f.seek(0)光标跳转 # 形成文件句柄f f = open("D:/desktop/云空间/profile", mode="r+", encoding="utf8") # content = f.read() # content type 是str类型 自动把utf8转换为unicode 由read()实现 # print(content) # f.close() # if not exist, will create it,if exist will overread it # f = open("log", mode="w", encoding="utf8") # f.write("dzf段志方") # f.read(3) 读取3个字符,一个汉字或一个英文 read读的都是##字符## # f.seek(3) 从第4个开始 按##字节##算,若正好位于中文,会报错 # f.tell() 获取光标位置 # f.readable() 是否可读 # line = f.readline() # 读一行,与java类似 # line = f.readlines() # 以每行为单位 形成列表 # f.truncate(5) 从光标开始截取原文件的5位 abcdef(不确定) # for i in f:print(i) 也可读 # f.close() # 自动关闭,可同时打开多个,推荐使用 # with open("D:/desktop/云空间/profile", mode="r+", encoding="utf8") as obj: # print(obj.read()) # with open("D:/desktop/云空间/profile", mode="r+", encoding="utf8") as obj, # open("D:/desktop/云空间/profile", mode="r+", encoding="utf8") as obj2: # print(obj.read()) # strip() 可以去掉空格或换行符 # 修改文件,文件是不能修改的,只能复制后,删除原来 # delete file rename file import os os.remove("path") os.rename("old","new")初始函数
# 函数调用时必须已经存在 # def my_len(s): # i = 0 # for k in s: # i += 1 # return None # # # print(my_len('段志方')) # # # def my_len(): # s="as" # i = 0 # for k in s: # i += 1 # return i """ 先定义,后调用 返回值情况, 1,无返回值,如输出就是None 不用写, 只写return (它是结束代码), return None,不常用 2,一个值 int,str,list,dict等 3,多个返回值 return 1,2 多个返回值用多个变量接受,不能多,也不能少 但可以用一个变量接受,按元祖返回 4,解释中输入1,2,3-->(1,2,3) a,b,c=[1,2,3] 可得a=1,b=2,c=3 """ # def func1(a, b = 1): # pass # # # func1((1,2,3)) """ 参数 若多个函数同名,距离调用最近的生效 若无参数,强制传参报错 若有参,不传不报错 1,无参 2,一个参数 3,多个参数def my(a,b): 按顺序传递 也可以 my(b=2,a=1)不报错 可以混用my(1,b=1),先按照位置传,再使用关键字 但my(1,b=1),my(a=1,1)报错,同一变量只能一个值 型参 位置参数:按照位置传递,必须传 默认参数:def my(a,b = 2) 不传及默认,因此默认参数只能在后边,先位置参数 动态参数:def my(*args) 函数中当做元祖,print() my(1,2,3,4.....) 先位置参数,再动态参数(只接受位置传参的),再默认参数,最后**kwargs 动态参数2:def my(**kwargs): 传入dict my(a=1,b=2,c=3)--->{"a":1,"b":2,"c":3} def my(*args,**kwargs) **args 在前,,,必须先位置参数,再关键字 动态参数另一种传参方式 列表或元祖当做位置参数传入 def my(*args): list=(1,2,3) my(*list) 表示按次序传给 def my(**kwargs): dict={"A":1,"B":2} my(**dict) 表示按次序传给 个人感觉这种就是只传一个参数 函数注释 """ # def my(arg): # """ # 功能 # :param arg: # :return: # """ # print(arg) # # # my([1,2,3]) user_list = [ {'username':'barry','password':'1234'}, {'username':'alex','password':'asdf'}, ] board = ['张三','李小四','王二麻子'] while 1: username = input('用户名:') if username.upper() == 'Q':break password = input('密码:') for i in board: if i in username: username = username.replace(i,'*'*len(i)) user_list.append({'username':username,'password':password}) print({'username':username,'password':password}) print(user_list) # 陷阱 # 若默认参数是可变数据类型,调用时,若不传递数据,公用一个资源,字典也类似 def f(a=[]): a.append(1) f() # [1] f() # [1,1] f([]) # [1] f() # [1,1] def f(k,a={}): a[k] = "v" f(1) # {1:"v"} f(2) # {1:"v",2:"v"} f(3) # {1:"v",2:"v",3:"v"}
函数进阶
# 内置命名空间--解释器 # 解释器启动就可以使用的名字,他们在解释器加载时加载进内存 # 全局命名空间--代码,非函数 # 程序加载时过程中加载的 # 局部命名空间--函数中代码 # 函数内部的名字,调用函数的时候才会产生,调用结束,消失 # 函数名不加括号 ,可打印出内存地址 # 地址+() 相当于执行 # a = 1 # def fun(): # a = 2 # fun() # print(a) # a=1 # def fun(): # global a # 不推荐使用 # a = 2 # fun() # print(a) # a=2 # 对于不可变数据类型,在局部可查看全局中的变量 # 但不能直接修改 # 若有修改,在函数中开始时加 global xx # 若在局部中声明一个global函数,那么此函数在局部内的操作对全局的变量有效 # globals() 永远全局,locals()会变化 # def f(): # x = "111" # y = "222" # print(locals()) # 放在本地查看局部中所有变量 字典形式 # print(locals()) # 放在全局,全局就是本地 # print(globals()) # 查看全局的与内置的 # def max(a,b): # return a if a>b else b # 三目运算符 # 变量 = 条件返回True的结果 if 条件 else 条件返回False的结果 # print(max(1,2)) # 函数嵌套定义 # def f():... # a = 1 # def outer(): # def inner1(): # a = 2 # def inner2(): # a = 3 # def inner3(): # nonlocal a # a += 1 # inner3() # print(a) # inner2() # print(a) # inner1() # outer() # print(a) # 注意 global var 此var必须是全局的,且全局的只有一层,局部可有多层(函数多层嵌套) # py3 nolocal var 声明了(上层)的(局部变量),局部若没有,会报错 # 函数作为,元素,参数,返回值 # 函数可以赋值 fun = fun1,可变量一样,亦可放在list,dict等作为容器元素 # 打印出来是<function fun_name at 0x0000000> # 加括号执行 list = [fun,fun2] list[0]()执行,也可作为参数再次传入函数 # def f(): # print(1) # list = [f] # list[0]() # 第一类对象, 函数名就符合 # 运行期创建 # 可作为函数参数或返回值 # 可存入变量的实体 # 闭包:嵌套函数,(内部)调用(外部函)数(变量),若不调用,就是嵌套函数 # def outer(): # a = 1 # def inn(): # print(a) # print(inn.__closure__) # <cell at addr:int....> 表示是闭包 # outer() # print(outer.__closure__) # None 不是闭包 # 常用形式, 外部调用函数内部函数, # 以前不用时,每次outer()内部数据都会建立, # 此时使用返回值,只要引用存在,数据创建一次,不会随outer结束而消失,避免多次创建 # def outer(): # a = 1 # def inn(): # print(a) # return inn # b = outer() # b() # import urllib # 模块,py文件 # from urllib.request import urlopen # # # def geturl(): # url = "http://www.xiaohuar.com" # def get(): # ret = urlopen(url).read() # return ret # return get # # get = geturl() # print(get()) # c = fun(10,20) 先执行, 在赋值,赋函数返回值,若无则是None
装饰器
# 装饰器形成过程
# 装饰器作用
# 不想修改函数的调用方式,但是还要在原始函数中加工能,java中的面向切面编程
# def fun():
# print("原始功能")
# def outer(f):
# def inner():
# print("前置额外功能")
# f()
# print("后置额外功能")
# return inner
# fun = outer(fun)
# fun()
# 被装饰函数可加返回值,需要在inner中接受并返回
# 也可以加参数,inner(*args(1,2,3,4),**kwargs) 接受,此时inner中args是个列表,f(*args,**kwargs) 表示把列表args,按位置传入
# print(*args)--> 1 2 3 4
# 接受聚合,调用打散
# 原则:开放封闭原则
# 对扩展开放,修改封闭
# 语法糖
# @outer @+装饰器函数名
# def fun():
# print("原始功能")
# 加上语法糖词句(可省)
# fun = outer(fun)
# 装饰器的固定模式(公式)
装饰器进阶
# 装饰器形成过程
# 装饰器作用
# 不想修改函数的调用方式,但是还要在原始函数中加工能,java中的面向切面编程
# def fun():
# print("原始功能")
# def outer(f):
# def inner():
# print("前置额外功能")
# f()
# print("后置额外功能")
# return inner
# fun = outer(fun)
# fun()
# 被装饰函数可加返回值,需要在inner中接受并返回
# 也可以加参数,inner(*args(1,2,3,4),**kwargs) 接受,此时inner中args是个列表,f(*args,**kwargs) 表示把列表args,按位置传入
# print(*args)--> 1 2 3 4
# 接受聚合,调用打散
# 原则:开放封闭原则
# 对扩展开放,修改封闭
# 语法糖
# @outer @+装饰器函数名
# def fun():
# print("原始功能")
# 加上语法糖词句(可省)
# fun = outer(fun)
# 装饰器的固定模式(公式)
# def fun():pass
# print(fun.__name__) 打印(执行函数)的字符串函数名,对于装饰器的话,返回的是inner的名字
# print(fun.__doc__) 打印函数注释,同上
# 添加from functools import wraps(固定的) 给inner函数加上@waraps+(原始函数名)
# 此时调用fun.___name__ 即可返回原始函数的信息
# 一个装饰器,装饰多个函数,在不同函数上加@语法糖即可
# 带参数的装饰器
# 500个函数要加装饰器,一个函数修饰多个函数
def timmer(f):
def inner(*args, **kwargs):
pass
ret = f(*args, **kwargs)
pass
return ret
return inner
@timmer
def fun(): pass
# 修改,三层装饰器,最多就是三层
FLAG = True
def timmer_out(flag):
def timmer(f):
def inner(*args, **kwargs):
if flag:
pass
ret = f(*args, **kwargs)
pass
else:
ret = f(*args, **kwargs)
return ret
return inner
return timmer
# 加上括号就是调用,先调用再@
# @timmer_out(FLAG) = timmer = timmer_out(FLAG);@timmer
@timmer_out(FLAG)
def fun(): pass
# 多个装饰器装饰一个函数
# 运行时先d1 的前置装饰,d2 的前置装饰,d2的后置装饰,d1的后置装饰
# 两个装饰器,先生效距离原函数近的语法糖,所以先生效的在内部
# 嵌套调用装饰器
def decorate1(f): # f--> fun
def inner1():
pass
def decorate2(f): # f-->inner
def inner2():
pass
@decorate1 # fun = decorate1(fun)->decorate1(inner)==inner2
@decorate2 # fun = decorate2(fun)=inner
def fun():
pass
# 此时调用fun()等于调用inner2
fun()
迭代器与生成器
# list(generator) 也可以从生成器取值,但是取全部,全部内容内存生成
# def generator():
# print(1)
# yield 1
# print(2)
# g = generator();
# print(g.__next__())
# 调用2次next 第二次会打印2 但会报错
# def generator():
# print(1)
# count = yield 1
# print(2)
# yield 2
# g = generator();
# print(g.__next__()) #执行到 yield 1
# print(g.send()) # send() 与next效果相同
# print(g.send("hello")) # 获取yield 时 传入新的值
# 修改yield 1 为 count = yield 1
# 此时执行到yield 1 时 停止,等待send() ,传入值给上个next,并赋值,在向下执行
# 注意第一次获取生成器时,必须使用next,
# 最后一个yield 不能接受外部的值,最后一个yield会后不能有代码,若必须使用,最后加yield 即可, 空
# 获取移动平均值
# def average():
# sum = 0
# count = 0
# avg = 0
# while 1:
# num = yield avg
# sum += num
# count +=1
# avg = sum / count
# avg = average()
# print(avg.__next__())
# print(avg.send(10))
# print(avg.send(20))
# def generator():
# a = "abcd"
# b = "1234"
# # for 循环yield a
# yield from a
# yield from b
# for i in generator():
# print(i) # a b c d 1 2 3 4
#
# 生成器表达式和列表推导式
# 推导式
# list = [i for i in range(10)]
# print(list)
# list = ["dzf%s" %i for i in range(10)]
# print(list)
# 其他推导式
# [元素或操作 for 元素 in 可迭代数据类型] 遍历后处理
# [满足条件的元素的操作 for 元素 in 可迭代数据类型 if 元素条件] 筛选功能
# 列表推导式
# [i for i in range(30) if i%3==0] -->[0,3,6....]
# 双层for 查找 双层list中数据
# names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],
# ['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']]
# [name for list in names for name in list if name.count('e')==2]
# 集合推导式,
# {x**2 for x in [1,-1,2]} -->{1,4} 自带去重
# [x**2 for x in [1,-1,2]] -->[1,1,4]
# 字典推导式
# 调换字典的key-value
# dict = {"a":1,"b":2,"A":7,"B":45}
# dict2 = {dict[k]:k for k in dict}
# 合并大小写对应的value值,将k统一成小写
# dict3 = {k.lower(): dict.get(k.lower(),0)+dict.get(k.upper(), 0) for k in dict}
# print(dict3)
# 表达式,括号不同,g为生成器.
# g = (i for i in range(10))
# print(g)
# for i in g:
# print(i)
# print(type(list()))
# print(type({1,2,34,5,5,5,}))
# 作业
# def find(path):
# with open(path,encoding="utf-8") as f:
# for line in f:
# if "xxx" in line:
# yield line
# for line in find("xxx"):
# print(line)
# 生成器面试题
# def demo():
# for i in range(4):
# yield i
# g = demo()
# g1 = (i for i in g) # -->此时未for循环,只生成生成器
# def fun():
# for i in g:
# yield i
# g2 = (i for i in g1)
# print(list(g1)) # -->[1,2,3,4],g1,执行生成器,全部取出
# print(list(g2)) # -->[],此时从g1取值没有了,为空
# 2
def add(n,i):
return n+i
def test():
for i in range(4):
yield i
g=test()
for n in [1,10,5]:
g = (add(n,i) for i in g)
#
# n = 1
# g=(add(n,i) for i in g)
# n = 10
# g=(add(n,i) for i in g) # -->g=(add(n,i) for i in (add(n,i) for i in g))
print(list(g))
list1 = [ # 列表剥皮
1,
2,
[
3,
4,
[5,6,7]
],
[
3,
4,
[
5,
6,
7,
[8,9,10]
]
]
]
def f3(x): # 生成器
return [a for b in x for a in f3(b)] if isinstance(x, list) else [x]
def f2(x):
l = []
for i in x:
if isinstance(i,list):
for k in f2(i):
l.append(k)
else:
l.append(i)
return l
def f(x,l=[]):
for i in x:
if isinstance(i,list):
f(i)
else:
l.append(i)
return l
print(f(list1))
print(f2(list1))
print(f3(list1))
内置函数
https://www.processon.com/view/link/5d4fa21be4b0ac2b61744998
http://assets.processon.com/chart_image/5d4fa098e4b0869fa40f9454.png
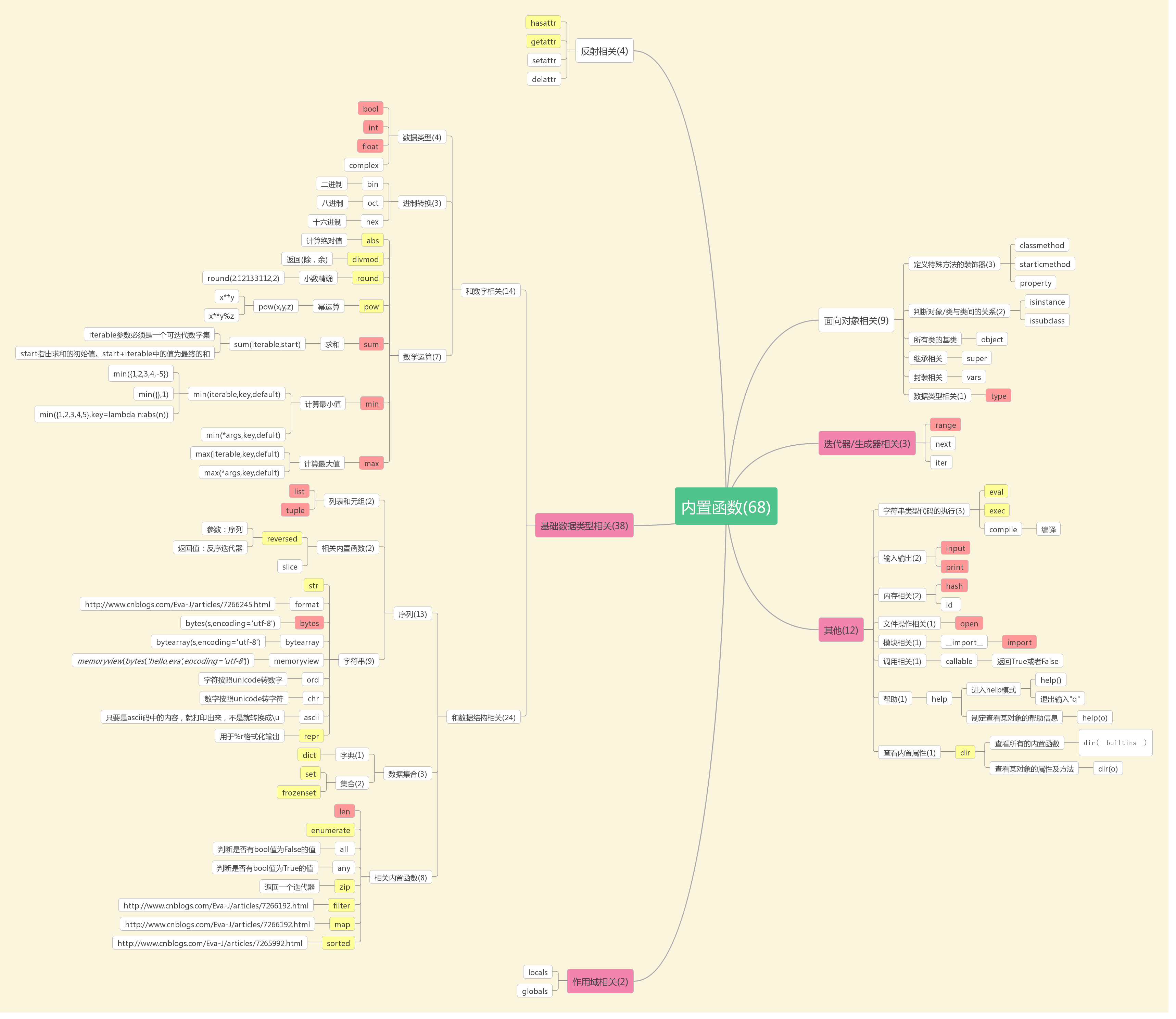{kind=link}
# 内置函数
# callable('xxx') # 检测是不是函数--->True or False
# help(str) # 显示str的帮助信息
# (导入)import time=time = __import__('time')
# print(time.time())
# f=open()
# f.read()
# print(f.writable()) # 检测是否可写
# print(f.readable()) # 检测是否可读
# # 内存相关
# id()
# hash(),一次执行中,相同的对象hash值不变,不管对象多大,hash值有范围
# print(hash(123456))
# print(hash('123456'))
# print(hash([1,2,3,4,5,6])) # 不可hash
# print(hash((1,2,3,4,5,6)))
# print()
# print("xxxx") # 自带换行符
# print("xxx",end='') # 取消换行
# print("xxx",sep='|') # 指定分隔符
# f = open('file','w') # 指定打印文件位置,控制台也是文件
# print("xxx",file=f)
# f.close()
# 进度条
#
表示回到行首
#
使最后换行
# flush=True, 传入字符立即写入,不缓存再写
# import time
# for i in range(0,101,2):
# time.sleep(0.1)
# char_num = i//2
# per_str="
%s%%:%s
" % (i,'*'*char_num) if i==100 else "
%s%%:%s" % (i,'*'*char_num)
# print(per_str,end='',flush=True)
# exec eval, 都可执行字符串代码,exec 无返回值
# eval 只能用明确知道的要执行的代码,不常用
# eval -- 有结果的简单计算
# exec -- 简单流程控制
# exec('print(123)') # 123
# eval('print(123)') # 123
# print(eval('1+2+3+4')) # 10
# print(exec('1+2+3+4')) # None
# compile 把代码编译为字节码,下次调用节省时间,
# code1 = 'for i in range(0,10):print(i)'
# # '' 为文件名,没有的话置空
# compile1 = compile(code1,'','exec')
# code2 = '1+2+3+4'
# compile2 = compile(code2,'','eval')
# print(eval(compile2))
# code3 = 'name = input("please input your name:")'
# compile3 = compile(code3,'','single')
# # name 执行前name不存在
# exec(compile3) # 执行后有name,虽然报错,但存在
# print(name)
# complex 复数 ,实部,虚部都是float
# print(complex(12,3)) # -->12 + 3j
"""
实数
有理数:小数,有限循环小数
无理数:无线不循环小数
虚数:x的平方式负数,i**2 = -1
复数:实数+虚数,5+ni ,不能比较大小,
"""
# 浮点数
# print(float(12))
"""
354.123 = 3.45123*10**2=35.4123*10,点回浮动 所以叫浮点数
float:有限循环,无限循环,
不是float:无线不循环
"""
# 进制转换 bin() 0b, oct() 0o,hex() 0x
# abs(n) 绝对值
# divmod(x,y) -->(n,m) x/y 商n余m,print(divmod(8,2))
# round(3.456879,2) 精确值,会四舍五入
# pow(x,y) 幂运算 pow(x,y,z) x**y % z 幂运算后取余
# sum(可迭代,切里边是数字)
# print(sum([1,2,3,4])) 基础值为0 ->10
# print(sum([1,2,3,4],10)) 基础值为10 -> 20
# min() 最小值,可传迭代,也可*args
# min([1,2,3,4])
# min(1,2,3,4)
# min(1,2,3,-4,key=abs) 可以 把key 用方法计算后求函数值
# max同min 注意,返回的是参数值,不是进过处理后的值
# reversed(list) #不改变原来列表,返回一个迭代器
# l=slice(1,5,2) 切片规则
# list[l]
# formate(数字)->转字符串
# formate('test','<20') 20空间 左对齐
# formate('test','>20') 右对齐
# formate('test','^20') 居中
# 等
# bytes 转换bytes类型
# 拿到gbk 转unicode 再转到utf8
# str = bytes("你好",encoding="gbk") # unicode转gbk的bytes类型
# str.decode("gbk") # 你好
# str = bytes("你好",encoding="utf8") # unicode转utf8的bytes类型
# str.decode("utf8") # 你好
# bytearray("你好",encoding="utf8") 返回byte 列表,修改里边的16进制可实现更改
# ord('a')查看编码 按照unicode
# print(ord('段'))
# print(chr(97))
# ascii('xxx')
# %s,%r
# print(repr('1')) # --> '1'
# print(repr(1)) # --> 1
# 枚举 l = [1,2,3,4] enum = enumerate(l)
# all([]) 判断里边字符是否全为True
# print(all([1,2,3,0]))
# any() 看上边
# zip()
"""
l = [1,2,3]
l2 = ["a","b","c"]
for i in zip(l,l2) 两边数可不同,开可以加l3,l4,若为字典(注意无序),只能加上key
print(i) -->(1,'a') (2,'b') (3,'c')
"""
# filter(),返回handler处理后的结果,bool
# 等于[i for i in [1,2,3,4,5] if i%2==1]
# ret = filter(handler,可迭代的元素) ret是迭代器
# def fun(x):
# return x%2==1
# ref = filter(fun,[1,2,3,4,5,6])
# print(list(ref)) --> [1,3,5]
# import math
# print(math.sqrt(9))
# print(1.5%1)
# map(fun,可迭代元素) 分处理后,返回可迭代元素
# ret = map(abs,[1,-4,-8])
# sorted(可迭代元素,key=fun,reserve=True) 自定义排序,返回新列表,元数据不变
# l.sort(key=abs) 按绝对值排序
匿名函数
# 匿名函数
# 必须在一行,
# lamdba 定义,n,m参数,冒号后边直接是返回值
calc = lambda n,m:m*n+2
# 调用,还可以有名字, 匿名的时候对于函数名做参数时使用
# max([],key=lambda k:xxx)
# max,min,sorted,filter,map
print(calc(1,2))
# 面试题
#现有两元组(('a'),('b')),(('c'),('d')),
# 请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}]
# ret = zip((('a'),('b')),(('c'),('d')))
# ret = map(lambda t:{t[0]:t[1]},ret)
# print(list(ret))
# max min sorted filter map
# 匿名函数 == 内置函数
# zip
# ret = zip((('a'),('b')),(('c'),('d')))
# res = map(lambda tup:{tup[0]:tup[1]},ret)
# print(list(res))
# 下面代码的输出结果是什么?
# def multipliers():
# return [lambda x:i*x for i in range(4)] # 返回4个lambda ,但最后i最后都是3
# print([m(2) for m in multipliers()]) [6,6,6,6]
# return (lambda x:i*x for i in range(4)) 生成器,
# --->[0,2,4,6]
# 作业
# 3.用map来处理字符串列表,把列表中所有人都变成sb,比方alex_sb
name=['alex','wupeiqi','yuanhao','nezha']
# def func(item):
# return item+'_sb'
# ret = map(func,name) #ret是迭代器
# for i in ret:
# print(i)
# print(list(ret))
# ret = map(lambda item:item+'_sb',name)
# print(list(ret))
# 4.用filter函数处理数字列表,将列表中所有的偶数筛选出来
# num = [1,3,5,6,7,8]
# def func(x):
# if x%2 == 0:
# return True
# ret = filter(func,num) #ret是迭代器
# print(list(ret))
#
# ret = filter(lambda x:x%2 == 0,num)
# ret = filter(lambda x:True if x%2 == 0 else False,num)
# print(list(ret))
# 5.随意写一个20行以上的文件
# 运行程序,先将内容读到内存中,用列表存储。
# 接收用户输入页码,每页5条,仅输出当页的内容
# with open('file',encoding='utf-8') as f:
# l = f.readlines()
# page_num = int(input('请输入页码 : '))
# pages,mod = divmod(len(l),5) #求有多少页,有没有剩余的行数
# if mod: # 如果有剩余的行数,那么页数加一
# pages += 1 # 一共有多少页
# if page_num > pages or page_num <= 0: #用户输入的页数大于总数或者小于等于0
# print('输入有误')
# elif page_num == pages and mod !=0: #如果用户输入的页码是最后一页,且之前有过剩余行数
# for i in range(mod):
# print(l[(page_num-1)*5 +i].strip()) #只输出这一页上剩余的行
# else:
# for i in range(5):
# print(l[(page_num-1)*5 +i].strip()) #输出5行
# 6.如下,每个小字典的name对应股票名字,shares对应多少股,price对应股票的价格
# portfolio = [
# {'name': 'IBM', 'shares': 100, 'price': 91.1},
# {'name': 'AAPL', 'shares': 50, 'price': 543.22},
# {'name': 'FB', 'shares': 200, 'price': 21.09},
# {'name': 'HPQ', 'shares': 35, 'price': 31.75},
# {'name': 'YHOO', 'shares': 45, 'price': 16.35},
# {'name': 'ACME', 'shares': 75, 'price': 115.65}
# ]
# 6.1.计算购买每支股票的总价
# ret = map(lambda dic : {dic['name']:round(dic['shares']*dic['price'],2)},portfolio)
# print(list(ret))
# 6.2.用filter过滤出,单价大于100的股票有哪些
# ret = filter(lambda dic:True if dic['price'] > 100 else False,portfolio)
# print(list(ret))
# ret = filter(lambda dic:dic['price'] > 100,portfolio)
# print(list(ret))
# 每周大作业
# 这一周写得所有博客地址,精确到页的url,至少三篇,内容不限
# 大作业 : py readme(对作业描述,顺便可以写点儿你想和导员沟通的) 流程图
#
初识递归
# 初识递归 最大深度1000左右 997 或998
# 设置默认次数
# import sys
# sys.setrecursionlimit(100)
# 若递归次数太多,则不适合递归
# 二分查找算法 必须处理有序的列表
# l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
# 5000000 4999998
# 代码实现
# def find(l,aim):
# mid_index = len(l) // 2
# if l[mid_index] < aim:
# new_l = l[mid_index+1 :] 每次传入新列表,最终查到时下标不对
# find(new_l,aim)
# elif l[mid_index] > aim:
# new_l = l[:mid_index]
# find(new_l, aim)
# else:
# print('找到了',mid_index,l[mid_index])
#
# find(l,66)
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
# def find(l,aim,start = 0,end = None):
# end = len(l) if end is None else end # end = len(l) 24
# mid_index = (end - start)//2 + start #计算中间值 12 + 0 = 12
# if l[mid_index] < aim: #l[12] < 44 #41 < 44
# find(l,aim,start =mid_index+1,end=end) # find(l,44,start=13,end=24)
# elif l[mid_index] > aim:
# find(l, aim, start=start, end=mid_index-1)
# else:
# print('找到了',mid_index,aim)
#
# def find(l,aim,start = 0,end = None): # l,44,start=13,end=24
# end = len(l) if end is None else end # end = 24
# mid_index = (end - start)//2 + start #计算中间值 24-13/2 = 5 + 13 = 18
# if l[mid_index] < aim: #l[18] < 44 #67 < 44
# find(l,aim,start =mid_index+1,end=end)
# elif l[mid_index] > aim: # 67 > 44
# find(l, aim, start=start, end=mid_index-1) # find(l,44,start=13,end=17)
# else:
# print('找到了',mid_index,aim)
#
# def find(l,aim,start = 0,end = None): # l,44,start=13,end=17
# end = len(l) if end is None else end # end = 17
# mid_index = (end - start)//2 + start #计算中间值 17-13/2 = 2 + 13 = 15
# if l[mid_index] < aim: #l[15] < 44 #55 < 44
# find(l,aim,start =mid_index+1,end=end)
# elif l[mid_index] > aim: # 55 > 44
# find(l, aim, start=start, end=mid_index-1) # find(l,44,start=13,end=14)
# else:
# print('找到了',mid_index,aim)
#
# def find(l,aim,start = 0,end = None): # l,44,start=13,end=14
# end = len(l) if end is None else end # end = 14
# mid_index = (end - start)//2 + start #计算中间值 14-13/2 = 0+ 13 = 13
# if l[mid_index] < aim: #l[13] < 44 #42 < 44
# find(l,aim,start =mid_index+1,end=end) # find(l,44,start=14,end=14)
# elif l[mid_index] > aim: # 42 > 44
# find(l, aim, start=start, end=mid_index-1)
# else:
# print('找到了',mid_index,aim)
def find(l,aim,start = 0,end = None):
end = len(l) if end is None else end
mid_index = (end - start)//2 + start
if start <= end:
if l[mid_index] < aim:
return find(l,aim,start =mid_index+1,end=end)
elif l[mid_index] > aim:
return find(l, aim, start=start, end=mid_index-1)
else:
return mid_index
else:
return '找不到这个值'
ret= find(l,44)
print(ret)
# 参数 end
# 返回值
# 找不到的话怎么办
# l.index()
# 67 发生两次调用
# 66 发生好几次
# 44 找不到
# age,二分查找,三级菜单的代码看一遍
# 斐波那契 # 问第n个斐波那契数是多少
# 阶乘
#3! 3*2*1
# 附加题 :考试附加题
# 递归实现
# l = [1,2,3]
# print(l[1:1])
# 超过最大递归限制的报错
# 只要写递归函数,必须要有结束条件。
# 返回值
# 不要只看到return就认为已经返回了。要看返回操作是在递归到第几层的时候发生的,然后返回给了谁。
# 如果不是返回给最外层函数,调用者就接收不到。
# 需要再分析,看如何把结果返回回来。
# 循环
# 递归
# 斐波那契 # 问第n个斐波那契数是多少
# 1,1,2,3,5,8 #fib(6) = fib(5) + fib(4)
# def fib(n):
# if n == 1 or n==2:
# return 1
# return fib(n-1) + fib(n-2) #两次递归非常慢
# print(fib(50))
# fib(6) = fib(5) + fib(4)
# fib(5) = fib(4)+fib(3)
# fib(4) = fib(3)+fib(2)
# fib(3) = fib(2)+fib(1)
# fib(2) = 1
# fib(1) = 1
# def fib(n,l = [0]):
# l[0] +=1
# if n ==1 or n == 2:
# l[0] -= 1
# return 1,1
# else:
# a,b = fib(n-1)
# l[0] -= 1
# if l[0] == 0:
# return a+b
# return b,a+b
# print(fib(50))
# 没看懂
def fib(n,a=1,b=1):
if n==1 : return a
return fib(n-1,b,a+b)
print(fib(50))
# 阶乘
#3! 3*2*1
# 2! 2*1
# 1! 1
# def fac(n):
# if n == 1 :
# return 1
# return n * fac(n-1)
#
# print(fac(100))
# 附加题 :考试附加题
# 递归实现
模块
# 模块的导入
# 导入的时候会执行里面的语句,有print()也会输出,多次导入只调用一次
"""
需求模块:本模块测试,print()会执行,其他文件调用,print()等不执行
__name__:本模块名字,单若在某个模块中开始运行的,输出是__main__,否则就是文件名
解决方法
被调用模块中:
def func():
pass
if __name__ == '__main__'
fun()
"""
# import xxxx # 找到模块,读内容到专属命名空间
# xxxx.func() xxxx.var
# 已经导入的modules字典,所以不会重复导入 名字:路径
# import sys
# print(sys.modules)
# import time as t 给模块起别名,提高兼容性
# import time, sys, os 同时引入多个代码,但不推荐
# 先导内置,扩展django,自己的
# from demo import func,var 都可以
# from demo import func as t
# from time import * 不安全
# 被调用的模块第一行加入 __all__ = ['var','fun']
# 其他文件用 *导入 该模块时 只能使用 list中含有的量
正则模块
#正则模块
"""
. 换行外任意字符
w 数字字母下划线
s 任意空白字符
d 数字
# 上边3个大写就是非,任意两对就是匹配全局
换行
制表
匹配单词结尾,用得少,前边加些字符,不然不显示
^x 以x开头,只匹配一个
() 一个组
[^ab] ab都不匹配 ,非
以上都是单个字符匹配
* + ? 等 只约束 前面的一个规则,若有每个,都加+即可
d* 多次匹配,空也可匹配
d+ 匹配一次或多次
d? 匹配一次
{n} 匹配n次
{n,m} n到m次
()? ()中只出现一次
.*?x 前边任意长度,直到出现x结束
转义符匹配
正则中\n 匹配
语言中\\n 匹配
为每个""转义
或r'\n' 匹配
取消""的转义功能
"""
# re模块
import re
# match (从头)开始匹配,匹配上就返回一个变量,search即时在中间也可以查到
# group显示
# 没有匹配返回Nnoe,调用group出错
ret = re.match('[a-z]+',"123 dzf gyg lzt")
print(ret)
# findall 匹配所有符合的放在列表中
ret = re.findall("[a-z]+","dzf gyg lzt")
print(ret)
# search,找到第一个就返回,返回一个对象,ret.group()回去值
# 若找不到返回None,使用group()则会报错
ret = re.search("[a-z]+","123 dzf gyg lzt")
print(ret.group())
# 分割,先按照a,分割再按b分割
re.split("[ab]","abcd")
# 替换所有数字为H,若没有1 表示匹配一次
re.sub('d',"H","cacasccass366asdas",1)
# 返回替换后的结果 并返回次数 元祖("str",次数)
re.subn('d',"H","cacasccass366asdas",1)
# 编译正则表达式
re.compile('d{3}') # 供后使用
# 返回一个存放结果的迭代器
ret = re.finditer("d","huoiuhizai23nusdwhjj")
#查看
next(ret).group() # 查看第一个
next(ret).group() # 查看第二个
for i in ret: #第3个开始
i.group()
# 对于search group() 返回一个完整的匹配
# group(1) group(2) 返回其中的一部分
# ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
# print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
# 保留分组优先
# ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
# print(ret) # ['www.oldboy.com']
ret=re.split("d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan']
ret=re.split("(d+)","eva3egon4yuan")
print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']
#re.findall(x,xx,flag)
# flag = rs.I 或略大小写
# flag = rs.M 多行模式,改变^$的行为
# flag = rs.S 点可以匹配换行,以及任意字符
# flag = rs.L 做本地化识别的匹配,表示特殊字符集 s,w 等,不推荐
# flag = rs.U 使用w w等,使用取决于unicode定义的字符属性,pythons默认使用
# flag = rs.X 冗长模式,pattern可以是多行,忽略空白字符,可添加注释
正则模块2
# 正则表达式
# 字符组 [字符]
# 元字符
# w d s
# W D S
# . 除了换行符以外的任意字符
#
#
# ^ $ 匹配字符串的开始和结束
# () 分组 是对多个字符组整体量词约束的时候用的
#re模块:分组是有优先的
# findall
# split
# | 从左到右匹配,只要匹配上就不继续匹配了。所以应该把长的放前面
# [^] 除了字符组内的其他都匹配
# 量词
# * 0~
# + 1~
# ? 0~1
# {n} n
# {n,} n~
# {n,m} n~m
# 转义的问题
# import re
# re.findall(r'\s',r's')
# 惰性匹配
# 量词后面加问号
# .*?abc 一直取遇到abc就停
# re模块
# import re
# re.findall('d','awir17948jsdc',re.S)
# 返回值:列表 列表中是所有匹配到的项
# ret = search('d(w)+','awir17948jsdc')
# ret = search('d(?P<name>w)+','awir17948jsdc')
# 找整个字符串,遇到匹配上的就返回,遇不到就None
# 如果有返回值ret.group()就可以取到值
# 取分组中的内容 : ret.group(1) / ret.group('name')
# match
# 从头开始匹配,匹配上了就返回,匹配不上就是None
# 如果匹配上了 .group取值
# 分割 split
# 替换 sub 和 subn
# finditer 返回迭代器
# compile 编译 :正则表达式很长且要多次使用
import re
# ret = re.search("<(?P<tag_name>w+)>w+</(?P=tag_name)>","<h1>hello</h1>")
# #还可以在分组中利用?<name>的形式给分组起名字
# #获取的匹配结果可以直接用group('名字')拿到对应的值
# print(ret.group('tag_name')) #结果 :h1
# print(ret.group()) #结果 :<h1>hello</h1>
# ret = re.search(r"<(w+)>w+</1>","<h1>hello</h1>")
# #如果不给组起名字,也可以用序号来找到对应的组,表示要找的内容和前面的组内容一致
# #获取的匹配结果可以直接用group(序号)拿到对应的值
# print(ret.group(1))
# print(ret.group()) #结果 :<h1>hello</h1>
import re
# ret=re.findall(r"d+.d+|(d+)","1-2*(60+(-40.35/5)-(-4*3))")
# print(ret) #['1', '2', '60', '40', '35', '5', '4', '3']
# ret.remove('')
# print(ret)
# ret=re.findall(r"-?d+.d*|(-?d+)","1-2*(60+(-40.35/5)-(-4*3))")
# print(ret) #['1', '-2', '60', '', '5', '-4', '3']
# ret.remove("")
# print(ret) #['1', '-2', '60', '5', '-4', '3']
# 首先得到一个字符串
# 去空格
# 没有空格的字符串
# 先算最里层括号里的 : 找括号 ,且括号里没有其他括号
# 得到了一个没有括号的表达式 :只有加减乘除 从左到右先找到第一个乘除法 —— 重复
# 所有的乘除法都做完了
# 计算加减 —— 加减法
# 只有一个数了 就可以结束了
collection
# collections 扩展数据类型
# 时间模块
# random 随机数模块
# os 操作系统
# sys 与python解释器有关
# 序列化模块 数据类型与str的转换
# collections
"""
namedtuple:
deque:双端队列
counter:计数器
orderedDict:有序字典
defaultdict:带默认值的字典
"""
# 列表,字典,字符串,集合,frozenset,字符串,堆栈
# namedtuple 可用名字获取值,
# from collections import namedtuple
# Point = namedtuple("point",['x','y','z'])
# p = Point(1,2,3)
# p2 = Point(1,2,3)
# print(p.x) # 1
# print(p.y) # 2
# print(p.z) # 3
# print(p) # (x=1,y=2)
# 花色与数字
# Card = namedtuple("card",["suits","number"])
# c1 = Card("红桃",2)
# print(c1)
# queue 队列,内容不可看
# import queue
# q = queue.Queue() # q不可for,不可放多个值,但可放其他元素类型
# q.put(10)
# q.put(10)
# q.put(10)
# q.put(10)
# print(q.get())
# print(q.get())
# print(q.get()) # 取内容时,若没有了,阻塞,等待再次添加,继续
# print(q.qsize()) # 查看剩余的,
# deque 双端队列,两端都可以存取
# from collections import deque
# dq = deque([1,2])
# dq.append('a') # 从后边放数据[1,2,'a']
# dq.appendleft('b') # 从前边放数据['b',1,2,'a']
# dq.insert(2,3) # ['b',1,3,2,'a']
# print(dq.pop()) # 从后边取数据 a
# print(dq.popleft()) # 从前边取数据 b
# print(dq) # deque([1, 3, 2]) 可看内容
# 有序字典
# from collections import OrderedDict
# 初始化时要如下定义,列表型定义,所以有序
# od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
# print(od) # -->OrderedDict([('a', 1), ('b', 2), ('c', 3)])
# OrderedDict的Key是有序的
# print(od['a']) # 仍可这样访问
# for k in od:
# print(k)
# defaultdict
# from collections import defaultdict
# d = defaultdict(lambda: 5) # value 默认是5
# print(d['k'])
# d = defaultdict(list) # 使字典的value默认为list,其他元素也可
# d['k'].append(1)
# print(d)
# from collections import Counter
# c = Counter("asdaquidbqu9fu9qnnaibcba")
# print(c) # Counter({'a': 4, 'q': 3, 'u': 3, 'b': 3, 'd': 2, 'i': 2, '9': 2, 'n': 2, 's': 1, 'f': 1, 'c': 1})
time
思考题,时间相减
import time
# time.sleep(100) # stop100 second
# time.time() # 返回s为单位的浮点数
# 格式化时间 —— 字符串: 给人看的 string str
# 时间戳时间 —— float时间 : 计算机看的 timestamp
# 结构化时间 —— 元祖 :计算用的 struct_time
# %a 简称英文星期
# %A 全称英文星期
# print(time.strftime("%Y-%m-%d %a %H:%M:%S")) #year month day HOUR MINUTE SECOND
# print(time.strftime("%Y/%m/%d %H:%M:%S")) #year month day HOUR MINUTE SECOND
# print(time.strftime("%m-%d %H:%M:%S")) #year month day HOUR MINUTE SECOND
# print(time.strftime("%H:%M:%S")) #year month day HOUR MINUTE SECOND
# print(time.strftime("%H:%M")) #year month day HOUR MINUTE SECOND
# struct_time = time.localtime()
# print(struct_time)
# print(struct_time.tm_year)
# 时间戳和结构化时间
# t = time.time()
# print(t)
# print(time.localtime(3000000000)) # 结构北京时间
# print(time.gmtime(t)) # 结构 格林威治时间
# print(time.mktime(time.localtime())) # 时间戳
# print(time.strptime('2000-12.31','%Y-%m.%d')) # 转为结构化时间
# print(time.strftime('%m/%d/%Y %H:%M:%S',time.localtime(3000000000))) # 结构化转格式化
# print(time.asctime()) # asc串
# print(time.asctime(结构化)) # 转asc
# print(time.ctime(时间戳)) # 转asc
# 思考题:两个时间相减,显示差了几年,几月,几天
# 张天福 —— 中国茶叶之父
# 陈味聪
# 周天霖
# 绿茶 : 龙井 碧螺春 竹叶青 信阳毛尖 六安瓜片 太平猴魁 安吉白茶
# 白茶 : 福鼎白茶 银针(100%芽) 白牡丹(一芽一叶) 贡眉(一芽两叶) 寿眉(一芽三叶)
# 黄茶 : 黄山毛峰 霍山黄芽
random
import random random.random() # 大于0小于1 random.uniform(1,3) # 大于1 小于3 random.randint(1,5) # 大于等于1 小于等于5 random.randrange(1,10,2) # 大于等于1 小于10 之间的奇数 random.choice([1,'23',[4,5]]) # 1或'23'或[4,5] 任意一个 random.sample([1,'23',[4,5]],2) # 任意两个组合 [[4,5],'23']
os
root,dirs,files in os.walk(path) 返回的是生成器
第一条,root = path,dir= path里边的第一级目录,files为第一级文件,
第二次循环,root为path的上一个循环中root中的第一个
依次循环
和使用os.walk(path).__next()__获取第一次记录
import os
os.getcwd() # 获取当前路径
os.chdir(r"xxxx") # 改变当前脚本执行路径,再次getcwd()会变化
os.curdir() # "."
os.pardir() # ".."
# os.chdir("..") = os.chdir(os.pardir())
os.makedirs("xxx/yyy") # 新建文件夹,级联
os.removedirs("目录") # 删除后,到上一级,为空就继续删除
os.mkdir("xxx") # 单级目录
os.rmdir("xxx") # 单级空目录
os.listdir("xxx")
os.remove("xxx") # 删除文件
os.rename("old","new") #
os.stat("path/file") # 获取文件/目录信息 ,大小,修改时间等
os.sep # 路径分隔符 win \ linux / 跨平台使用
os.linesep # 当前终止符 win
linux
os.pathsep # 路径文件分隔符 win ; linux :
os.name # 字符串指示当前使用的平台 win nt; linux posix
os.system("bash command") # 不用打印直接输出,但无返回值
os.popen("bash command").read() # 获取执行结果,
os.environ # 环境变量
os.path
os.path.abspath("path") # 返回path绝对路径
os.path.split("path") # 返回目录与文件名,元祖返回
os.path.dirname("path") # 返回path目录,不包括文件
os.path.basename("path") # 返回最后的文件名,若/ 结尾返回空
os.path.exists("path") #True Flase
os.path.isabs("path") # 是否是绝对路径
os.path.isfile("path")
os.path.isdir("path") # 是否存在(目录)
print(os.path.join("xxx","yyy","zzz")) # 拼接为 xxxyyyzzz,
os.path.getatime("path") # 最后访问时间
os.path.getmtime("path") # 最后修改时间
os.path.getsize("path") # 大小
sys
import sys sys.platform # 返回操作系统位数 sys.version # 返回python版本 sys.exit() # 程序退出 0 正常退出,非0 不正常 sys.path # 所有搜索模块的路径,list,当前路径,python默认包路径等... sys.path.clear() # 清空后 import os 无效 sys.argv # python xxx.py a b c ; # 用于接收 a b c 等参数 list # 不用input,节省时间
序列化模块
'abdsafaslhiewhldvjlmvlvk['
# 序列化 —— 转向一个字符串数据类型
# 序列 —— 字符串
"{'k':'v'}"
# 数据存储
# 网络上传输的时候
# 从数据类型 --> 字符串的过程 序列化
# 从字符串 --> 数据类型的过程 反序列化
# json ***** 非常重要
# pickle ****
# shelve *** python3 新出现的
# json # 数字 字符串 列表 字典 元组(转为list),反序列后还是list
# 通用的序列化格式
# 只有很少的一部分数据类型能够通过json转化成字符串
# 只有json,方式文件中的可读
# pickle
# (所有的python中的数据类型)都可以转化成字符串形式
# pickle序列化的内容(只有python能理解)
# 且部分反序列化依赖python代码
# shelve
# 序列化句柄
# 使用句柄直接操作,非常方便
# json dumps序列化方法 loads反序列化方法 内存数据
# dic = {1:"a",2:'b'}
# print(type(dic),dic) # <class 'dict'> {1:"a",2:'b'}
# import json
# str_d = json.dumps(dic) # 序列化
# print(type(str_d),str_d) # <class 'str'> {1:"a",2:'b'}
# # '{"kkk":"v"}' 字符串元素全部双引号显示
# dic_d = json.loads(str_d) # 反序列化
# print(type(dic_d),dic_d)
import json
# json (dump) load 文件数据
# dic = {1:"a",2:'b'}
# f = open('fff','w',encoding='utf-8')
# json.dump(dic,f)
# f.close()
# f = open('fff') # 没中文可不用写编码
# res = json.load(f)
# f.close()
# print(type(res),res)
import json
# json dump load
# dic = {1:"中国",2:'b'}
# f = open('fff','w',encoding='utf-8')
# json.dump(dic,f,ensure_ascii=False) # 默认以bytes写入,改为false时可以写中文
# json.dump(dic,f,ensure_ascii=False)
# 可以两次写
# f.close()
# f = open('fff',encoding='utf-8')
# res1 = json.load(f)
# res2 = json.load(f)
# f.close()
# print(type(res1),res1)
# print(type(res2),res2)
# 一次读会报错
# json
# dumps {} -- > '{}
'
# 一行一行的读
# '{}
' 读出来一行
# '{}' loads 队一行loads
# 例 逐行写入
# l = [{'k':'111'},{'k2':'111'},{'k3':'111'}]
# f = open('file','w')
# import json
# for dic in l:
# str_dic = json.dumps(dic)
# f.write(str_dic+'
')
# f.close()
# 读
# f = open('file')
# import json
# l = []
# for line in f:
# dic = json.loads(line.strip())
# l.append(dic)
# f.close()
# print(l) # 转回list
import pickle #
# dic = {'k1':'v1','k2':'v2','k3':'v3'}
# str_dic = pickle.dumps(dic)
# print(str_dic) #一串二进制内容
#
# dic2 = pickle.loads(str_dic)
# print(dic2) #字典
# import time 文件操作时用rb,wb,(可以分部调用)
# struct_time1 = time.localtime(1000000000)
# struct_time2 = time.localtime(2000000000)
# f = open('pickle_file','wb')
# pickle.dump(struct_time1,f)
# pickle.dump(struct_time2,f)
# f.close()
# f = open('pickle_file','rb')
# struct_time1 = pickle.load(f)
# struct_time2 = pickle.load(f)
# print(struct_time1.tm_year)
# print(struct_time2.tm_year)
# f.close()
# =======================================
# 会产生三个临时文件,且不支持多个应用同时写
# import shelve
# f = shelve.open('shelve_file')
# f['key'] = {'int':10, 'float':9.5, 'string':'Sample data'} #直接对文件句柄操作,就可以存入数据
# f.close()
#
# import shelve
# f1 = shelve.open('shelve_file')
# existing = f1['key'] #取出数据的时候也只需要直接用key获取即可,但是如果key不存在会报错
# f1.close()
# print(existing)
# ======================================
# 只读方式打开,本应该不能够修改,但有时候却可以修改
# import shelve
# f = shelve.open('shelve_file', flag='r')
# existing = f['key']
# print(existing) 原来内容
# f.close()
#
# f = shelve.open('shelve_file', flag='r')
# existing2 = f['key'] 修改
# f.close()
# print(existing2) 再次打印
# ============================================
# 修改不生效
import shelve
# f1 = shelve.open('shelve_file')
# print(f1['key'])
# f1['key']['new_value'] = 'this was not here before'
# f1.close()
# writeback = True 生效, 会消耗内存, 一般都是重新建文件,写入,重命名
f2 = shelve.open('shelve_file', writeback=True)
print(f2['key'])
# f2['key']['new_value'] = 'this was not here before'
f2.close()
# ============================================
包
# 把解决一类问题的模块放在同一个文件夹里 —— 包'
# import xx.yy.zz 点的左边必须是包
# from xx.yy import zz
# from xx import yy.zz 错误
# 例: 包1/包2/包3/文件
# import 包1
# 包1.包2.包3.文件.fun() 会出错
# import package 会自动执行包下__init__py文件
# from 包1 import 包2 # 包1 下init
# from 包1.包2 import 包3 # 包2 init
# from 包1.包2.包3 import 文件 # 包3下 init
# import 包1
# 包1.包2.包3.文件.fun() 此时不会出错
# 绝对路径,直观,但移动不方便,
# 但调用不出错,随便使用
# ===================
# 使用相对路径
# from . import 包2 # 包1 下init
# from . import 包3 # 包2 init
# from . import 文件 # 包3下 init
# 找到包的位置,都可以使用包中的文件
# 注意:
# 包1/包2,包3,文件1
# 包2中文件调用 包3中文件 运行包2下那个文件 出错
# 若非要使用,在包2的那个文件中,添加包2的上级目录,即包1 进入sys.path
# 包2 文件 from 包3 import 包3文件 即可使用
# 文件1调用 包2,包3中文件 运行文件1 不出错
# #####文件1 调用包2文件引用文件3的那个方法(不错)
# 包中,包中文件调用出错,只有包外部文件可调用包内文件
# 相对路径,只能找到上层目录,但不能找到上层的上层
#======================
# 还有* 与__all__ 配合使用
#=======================================
# 总之,最重要的一点 from 或 import 包,文件的时候,看他是否在sys.path 中
#=======================================
# import os
# os.makedirs('glance/api')
# os.makedirs('glance/cmd')
# os.makedirs('glance/db')
# l = []
# l.append(open('glance/__init__.py','w'))
# l.append(open('glance/api/__init__.py','w'))
# l.append(open('glance/api/policy.py','w'))
# l.append(open('glance/api/versions.py','w'))
# l.append(open('glance/cmd/__init__.py','w'))
# l.append(open('glance/cmd/manage.py','w'))
# l.append(open('glance/db/models.py','w'))
# map(lambda f:f.close() ,l)
# import glance.api.policy as policy
# policy.get()
#
# from dir.glance.api import policy
# policy.get()
# import sys
# sys.path.insert(0,'C:\Users\Administrator\PycharmProjects\s9\day21\dir')
# # print(sys.path)
# from glance.api import policy
# policy.get()
# from dir import glance
# glance.db.models.register_models('mysql')
# glance.api.policy.get()
# 使用绝对路径 不管在包内部还是外部 导入了就能用
# 不能挪动,但是直观
# from dir import glance
# glance.api.policy.get()
# 相对路径
# 可以随意移动包 只要能找到包的位置,就可以使用包里的模块
# 包里的模块如果想使用其它模块的内容只能使用相对路径,使用了相对路径就不能在包内直接执行了
# bin
# start.py
# conf
# config.py
# my_log_setting.py
# setting.py
# core 核心代码
# core.py
# db 数据信息
# alex_json
# dzf_json
# lib 自定义模块,三方模块
# read_ini.py
# log
# access_log
# error_log
异常处理
# 语法错误,逻辑错误
# 1/0
# name
# 2+'3'
# [][3]
#{}['k']
# =========================================================
# try:
# print('1111')
# # 1/0
# print('2222')
# # name
# # 2+'3'
# # [][3]
# # {}['k']
# ret = int(input('number >>>'))
# print(ret*'*')
# except ValueError:
# print('输入的数据类型有误')
# except Exception:
# print('你错了,老铁')
# else:
# print('没有异常的时候执行else中的代码') # 正常执行完后执行,异常终止时,不处理
# =========================================================
# def func():
# try:
# f = open('file','w')
# ''''''
# return True
# except:
# return False
# finally:
# print('执行finally了')
# f.close()
#
# print(func())
# 程序一旦发生错误,就从错误的位置停下来了,不在继续执行后面的内容
# 使用try和except就能处理异常
#try是我们需要处理的代码
#except 后面跟一个错误类型 当代码发生错误且错误类型符合的时候 就会执行except中的代码
#except支持多分支
#有没有一个能处理所有错误的类型 : Exception
# 有了万能的处理机制仍然需要把能预测到的问题单独处理
# 单独处理的所有内容都应该写在万能异常之前
# else : 没有异常的时候执行else中的代码
# finally : 不管代码是否异常,都会执行
# finally和return相遇的时候 依然会执行
# 函数里做异常处理用,不管是否异常去做一些收尾工作 f.close,会先执行finally 再return
# try:
# main()
# except Exception:
# pass
try:
print('1111')
# 1/0
print('2222')
# name
# 2+'3'
# [][3]
# {}['k']
ret = int(input('number >>>'))
print(ret*'*')
except Exception as error: # 可输出错误信息
print('你错了,老铁',error)
面向对象
# 面向对象编程
# 所谓模子 就是 类 抽象的 我能知道有什么属性 有什么技能 但不能知道属性具体的值
# jin alex nezha 就是对象 有具体的值,属性和技能都是根据类规范的
# 自定义类
# def 函数名():
# pass
#=================
# class 类名:
# 属性 = 'a'
#=================
# print(类名.属性)
# 类名的作用 就是操作属性 查看属性
#==============================
# class Person: # 类名
# country = 'China' # 创造了一个只要是这个类就一定有的属性
# # 类属性 静态属性
# def __init__(self,*args): # 初始化方法,self是对象,是一个必须传的参数,等于构造方法
# # self就是一个可以存储很多属性的大字典 ,等于this, __dict__
# self.name = args[0] # 往字典里添加属性的方式发生了一些变化
# self.hp = args[1]
# self.aggr = args[2]
# self.sex = args[3]
#
# def walk(self,n): # 方法,(一般情况下必须传self参数),且必须写在第一个
# # 后面还可以传其他参数,是自由的
# print('%s走走走,走了%s步'%(self.name,n))
#========================================
# 静态属性查看
# # print(Person.country) # 类名 可以查看类中的属性,不需要实例化就可以查看
#========================================
# 普通属性查看
# alex = Person('狗剩儿',100,1,'不详') # 类名还可以实例化对象,alex对象 # 实例化
# print(alex.__dict__) # 查看所有属性
# print(alex.name) # 查看属性值
# print(alex.hp) # 查看属性值
#================================================
# 方法调用
# alex.walk(5) # 都可以调用
# Person.walk(alex,5) # 调用方法 类名.方法名(对象名)
#================================================
# print(Person.__dict__['country']) # 查看静态属性
# Person.__dict__['country'] = '印度'
# print(alex.__dict__['name'])
# alex.__dict__['name'] = '二哥'
# print(alex.__dict__)
# print(alex.name)
# print(alex.name)
# alex.name = '二哥'
# alex.__dict__['name'] = '二哥'
# alex.age = 83
# print(alex.__dict__)
# print(alex.name)
# 对象 = 类名()
# 过程:
# 类名() 首先 会创造出一个对象,创建了一个self变量
# 调用init方法,类名括号里的参数会被这里接收
# 执行init方法
# 返回self
# 对象能做的事:
# 查看属性
# 调用方法
# __dict__ 对于对象的增删改查操作都可以通过字典的语法进行,only contain dynamic attributes
# 类名能做的事:
# 实例化
# 调用方法 : 只不过要自己传递self参数
# 调用类中的属性,也就是调用静态属性
# __dict__ 对于类中的名字只能看 不能操作,用"."可以操作
# 几乎与java类似
# 定义类
# init方法
# self是什么 self拥有属性都属于对象
# 調用類的時候創建self,是一個空的對象,有init初始化
# 类中可以定义静态属性
# 类中可以定义方法,方法都有一个必须传的参数self
# 实例化
# 实例、对象
# 对象查看属性
# 对象调用方法
# 命名空間
# class has static attribute,function
# object has owner namespace,attribute not (contain static) attribute and a pointer to class,
# beacuse it, if you change class static attribute by obj , equal you change memory address ,if the attr is str,int and so on
# you will only change the one obj,it will add a dynamic attribute in obj’s __dict__
# if the static is list ,dict and so on, all obj and the static attr will be changed
# object execute the static attribute ,but can't find it ,will find it in class namespace
面向对象2
# 导入包的时候,相当于实例化对象,对调用__init__ 在进行方法使用
# 面向对象:继承 多态 封装
# =======================
# 继承:单继承与多继承(独有)
# 父类,超类,基类
# 子类,派生类
# class Person:pass
# class Substance:pass
# class Student(Person,Substance):pass
#
# print(Student.__bases__) # (<class '__main__.Person'>, <class '__main__.Substance'>)
# print(Person.__bases__) # (<class 'object'>,) python3中,没有显示继承类,都默认继承object类
# class Animal:
# def __init__(self,name,aggr,hp):
# self.name = name
# self.aggr = aggr
# self.hp = hp
# self.func() # 子类的fun
# def func(self):
# print(123)
# #
# class Dog(Animal):
# def func(self):
# print(456)
# def bite(self,person):
# person.hp -= self.aggr
# d1 = Dog("dzf",1)
# print(d1)
# 子类没有init 会默认执行父类的init ,即把参数传给父类的init 注意与java不同
# 对于方法的重写,与java相同,字节实现自己的方法若要包含父类的方法Father.fun(self)即可 python3 中 有super
# super().__init__(x,x) 此种也可以,不用传递self
# super(原对象,self) 这两个参数是省略的
# 在类外部super(x,self).fun() 可调用x父类的fun方法
# 当子类有init时 调用自己的, super(x,y,x) ----> Father.__init__(self,x,y);self.z=z
# 推荐使用单继承,设计模式中 使用多继承,不常用
# 多继承
# 子类继承父类方法,并重写,切父类都有这个方法
# 父类的方法时,会按照次序,先自己,从左向右调用父类的
# 经典问题:钻石继承问题 图1,3
# 此时同父类:A B,C 继承A ,D继承BC, D调用方式,先按照顺序BC,再A
# 先广度找,再深度,广度优先 bc
# 若 B 继承A, C继承F D继承bc, 此时先 b a 再 c d
# 即若后边可以找到,就放在后边找,
# 按照(广度)优先遍历算法 ,不能重复 2
# python2中按照深度优先查找,一条路到黑
# 注意super() 再多继承时调用的不是父类的方法,而是按照查找顺序 调用 图4
# Class.mro() 列表返回class 到object 的继承顺序
# class A:pass
# class B(A):pass
# class C(A):pass
# class D(B):pass
# class E(C):pass
# class F(D,E):pass
#
# print(F.mro())
# 接口类:原生不支持
# 抽象类:原生支持
# from abc import abstractmethod,ABCMeta # 装饰器
# class Payment(metaclass=ABCMeta):
# @abstractmethod
# def pay(self,x):
# pass
# 规范
# 接口类,默认多继承,接口类中所有方法都要不实现(pass)
# 抽象类,不支持多继承,里面方法可以有一些实现 ,当两者书写形式相同
# 其他类继承时 必须要实现
# 接口隔离,一个接口与一个方法
# 本是没有接口的,因为自带多继承,通过这种方式模拟,接口 抽象类
# 与java相同,二者不能实例化
# python 天生支持多态 不用通过第三个类,实现一起调用
# 鸭子类型:依赖父类的情况下实现两个同名方法
# 封装性,隐藏属性,方法
class Person:
def __init__(self,name,passwd):
self.name=name
self.__passwd = passwd # 属性以双下划线开头 即为私有属性
dzf = Person("dzf","123456")
print(dzf)
print(dzf.name)
# print(dzf.passwd) # 打印出错
print(dzf.__dict__) # -->{'name': 'dzf', '_Person__passwd': '123456'}能查看
# 私有属性变为 “_类名属性名
# 对于方法相同,双下划线开头即为私有方法
# 静态属性也可定义为私有的
print(dzf._Person__passwd) # 能查到
# 没有真的约束,只是代码级别变形,外部通过——类名——名字 直接调用 内部——名字调用
# 父类的私有属性,子类不能调用(静态属性),
面向对象3
# isinstance(object,cls) # obj 是不是cls的子类
# issubclass(sub,super) sub 是super的子类
# __dict__ 类中中有方法,有属性,但方法不能通过dict执行
# 对象的__dict__只有属性
# sys.modules 列表显示模块简称:位置
# sys.modules['__main__'] 获取当前模块
# getattr(sys.modules['__main__'],xxx) # 从当前模块反射,防止其他模块重名反射
# 但一般不用__main__ 防止其他模块引用,用___name__代替
# 反射还可以拿到模块中的类,加括号 表示实例化
# 类中的内置方法,__init__,__str__,__repr__等,后两个必须返回字符串
# str(obj) -->obj.__str__ 等同于toString() 方法,默认情况继承object 打印地址
# __repr__ ,父类的一样也是打印地址
# %s 按照 __str__
# %r 按照__repr__
# repr 是str的备胎,若没有str,会找本类repr, 再找父类str,
# 但str不是repr的备胎,找不到子类repr 直接找父类repr 一般都实现repr
#内置方法很多,不一定都在obj __len__
# del 析构函数
# def __del__():pass
# del obj 先执行这个方法,再删除,即时不del 会在解释器结束的时候,调用del
# __call__ 方法
# a = A()()---> a()--->执行a的call方法,若没有则报错
# item系列
# class中实现item,可以通过 a['name']=a.name
# def __getitem__(self,item):
# if(hasattr(self,item))
# return getattr(self,item)
# f[item(属性名)]
# setitem
# def __setitem__(self,key,value): # 修改属性
# self.__dict__[key] = value
# 实现setitem,getitem后即可切片
# delitem
# 正常情况 del cls.name 对应的是 __delattr__(self,item):self.__dict__pop(item) object原生的
# def __delitem__(self,item):
# del self.__dict__[item]
#
# __init__ 初始化方法
# __new__构造方法:创建一个对象,不常用
# def __new__(cls,*args,**kwargs):
# return object.__new__(类名,*args,**kwargs) # 这两个参数可以不加,加了可能报错 此时没有self, 创建后给init
# 先执行new方法,再init
# 一个类 始终 只有 一个 实例
# 当你第一次实例化这个类的时候 就创建一个实例化的对象
# 当你之后再来实例化的时候 就用之前创建的对象
# class A:
# __instance = False
# def __init__(self,name,age):
# self.name = name
# self.age = age
# def __new__(cls, *args, **kwargs):
# if cls.__instance:
# return cls.__instance
# cls.__instance = object.__new__(cls)
# return cls.__instance
#
# egon = A('egg',38)
# egon.cloth = '小花袄'
# nezha = A('nazha',25)
# print(nezha)
# print(egon)
# print(nezha.name)
# print(egon.name)
# print(nezha.cloth)
# __eq__
# 默认对象"="比较 返回地址比较结果,写了__eq__之后 "=" 机会按照eq 与java不同
# is 比较的是地址,不绑定方法,当值str等直接存值的类型时,相同则返回True,其他类型 比较地址
# hash() 绑定__hash__ hash()中的是按照内存地址hash
# 通过修改__hash__ 可自定义hash,对于不可变类型,hash值相同
# nametuple 相当于创建一个类
list1 =[1,2,3]+list('JQKA')
print(list1)
from random import shuffle # 打乱顺序,依赖__len__方法 ,__setitem__方法
shuffle(list1)
print(list1)
# set去重依赖hash() 与 eq方法
property
# property
# 内置装饰器函数 只在面向对象中使用,没什么其他的作用
from math import pi
class Circle:
def __init__(self,r):
self.r = r
@property
def perimeter(self):
return 2*pi*self.r
@property
def area(self):
return self.r**2*pi
# c1 = Circle(5)
# print(c1.area) # 圆的面积
# print(c1.perimeter) # 圆的周长
# class Person:
# def __init__(self,name,high,weight):
# self.name = name
# self.high = high
# self.weight = weight
# @property
# def bmi(self):
# return self.weight / self.high**2
# jin = Person('金老板',1.6,90)
# jin.bmi = 18 # 当做属性时,不能修改
# classmethod
# staticmethod
# class Person:
# def __init__(self,name):
# self.__name = name
# @property # 当做属性
# def na(self):
# return self.__name + 'sb'
# @na.setter # 设置setter方法 3个na必须一致
# def na(self,new_name):
# self.__name = new_name
#
# tiger = Person('泰哥')
# print(tiger.name)
# tiger.name = '全班' # 可修改
# print(tiger.name)
# class Goods:
# discount = 0.8
# def __init__(self,name,price):
# self.name = name
# self.__price = price
# @property
# def price(self):
# return self.__price * Goods.discount
# apple = Goods('苹果',5)
# print(apple.price)
# 属性 查看 修改 删除
# class Person:
# def __init__(self,name):
# self.__name = name
# self.price = 20
# @property
# def name(self):
# return self.__name
# @name.deleter # 属性删除
# def name(self):
# del self.__name
# @name.setter
# def name(self,new_name): # 只能定义一个参数
# self.__name = new_name
# brother2 = Person('二哥')
# del Person.price
# brother2.name = 'newName'
# brother2
# del brother2.name
# print(brother2.name) # 查看报错 ,实际是私有的属性__name 没有了,调用了delete 内部语句 2个name()还存在
# 函数属于类,对象不能删除函数
反射
#反射 *****
# name = 'alex'
# 'name'
class Teacher:
dic = {'查看学生信息':'show_student','查看讲师信息':'show_teacher'}
def show_student(self):
print('show_student')
def show_teacher(self):
print('show_teacher')
@classmethod
def func(cls):
print('hahaha')
alex = Teacher()
# getattr(Teacher,'fun') # 只能获静态属性,类方法,(静态方法也可)返回方法地址,
# func = getattr(alex,'show_student') # 获取对象属性,变量 方法,动态属性
# func() 加括号即可调用
# 没有get到会报错
# hasattr getattr delattr
# if hasattr(Teacher,'dic'):
# ret = getattr(Teacher,'dic') # Teacher.dic # 类也是对象
# # ret2 = getattr(Teacher,'func') # 类.方法 teacher.func
# # ret2()
# print(ret)
# 通过反射
# 对象名 获取对象属性 和 普通方法
# 类名 获取静态属性 和类方法 和 静态方法
# 普通方法 self
# 静态方法 @staticmethod
# 类方法 @classmethod
# 属性方法 @property
class_static_method
# method 方法
# staticmathod 静态的方法 ***
# classmethod 类方法 ****
# 类的操作行为
# class Goods:
# __discount = 0.8
# def __init__(self,name,price):
# self.name = name
# self.__price = price
# @property
# def price(self):
# return self.__price * Goods.__discount
# @classmethod # 把一个方法 变成一个类中的方法,这个方法就直接可以被类调用,不用传入对象
# def change_discount(cls,new_discount): # 修改折扣,默认传入cls 表示类
# cls.__discount = new_discount
# apple = Goods('苹果',5)
# print(apple.price)
# Goods.change_discount(0.5) # Goods.change_discount(Goods) 默认传入cls
# print(apple.price)
# 当这个方法的操作只涉及静态属性的时候 就应该使用classmethod来装饰这个方法
# java
class Login:
def __init__(self,name,password):
self.name = name
self.pwd = password
def login(self):pass
@staticmethod
def get_usr_pwd(): # 静态方法 ,与类没有关系,不用传入cls
usr = input('用户名 :')
pwd = input('密码 :')
Login(usr,pwd)
Login.get_usr_pwd()
# 在完全面向对象的程序中,
# 如果一个函数 既和对象没有关系 也和类没有关系 那么就用staticmethod将这个函数变成一个静态方法
# 类方法和静态方法 都是类调用的
# 对象可以调用类方法和静态方法么? 可以 一般情况下 推荐用类名调用,与java相同
# 类方法 有一个默认参数 cls 代表这个类 cls
# 静态方法 没有默认的参数 和普通函数一样
常用模块
hashlib
# import hashlib
# md5 = hashlib.md5(bytes("盐值",encoding="utf8")) # 加颜值 sha1,sh3_224,sha3_512
# md5.update(b'dzf123') # 只能使用bytes类型,
# md5.update(b"123") # 支持分批加密
# print(md5.hexdigest()) #16进制
# 设置颜色
"""
�33[显示方式;前景色;背景色m; xxx �33[0m
前:30-37 黑红绿黄,蓝紫青白
背:40-47 黑红绿黄,蓝紫青白
显示方式:0 终端默认显示
1 高亮显示
4 使用下划线
5 闪烁 (不好用)
7 反白显示
8 不可见
"""
# print("�33[0;40;37m dzf �33[0m")
# menu = [('a',2),('b',4),('c',6)]
# for i,j in enumerate(menu,1):
# print(i,j) # i 表示序号,j 每一个元祖
logging
# logging 日志模块
# 有5种级别的日志记录模式 :
# 两种配置方式:basicconfig 、log对象
# logging.debug('debug message') # 低级别的 # 排错信息
# logging.info('info message') # 正常信息 ,默认info向上,不包括info
# logging.warning('warning message') # 警告信息
# logging.error('error message') # 错误信息
# logging.critical('critical message') # 高级别的 # 严重错误信息
# =============================================================
# format 中参数
# name Logger的名字
# levelno 数字形式日志级别
# levelname 文字形式日志级别
# pathname 日志输出模块的完整路径
# filename 日志输出函数的模块的文件名
# module 日志输出函数的模块名
# funcName 日志输出函数的函数名
# lineno 行号
# created 当前时间,unix 浮点数表示
# relativeCreated 自logger创建以来的毫秒数
# asctime 当前时间 默认格式:"2019-08-16 21:20:20,875" 毫秒
# thread 线程ID ,可能没有
# threadName 线程Nname ,可能没有
# process 进程ID ,可能没有
# message 用户输出的消息
# =============================================================
# basicconfig 简单 能做的事情相对少
# 中文的乱码问题,好像还不能解决
# 不能同时往文件和屏幕上输出
# import logging
# level=logging.WARNING # 表示警告及以上的
# logging.basicConfig(level=logging.WARNING,
# format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
# datefmt='%a, %d %b %Y %H:%M:%S',
# filename="log.log",
# filemode="a")
# try:
# int(input('num >>'))
# except ValueError:
# logging.error('输入的值不是一个数字')
# print("%(x)s"%{"x":"value"}) # 传入x ,值为value
# print("%s"%("x")) # 传入x ,值为value
# =================================================================
# 配置log对象 稍微有点复杂 能做的事情相对多
import logging
logger = logging.getLogger() # 创建对象
fh = logging.FileHandler('log.log',encoding='utf-8') # 打开文件
sh = logging.StreamHandler() # 创建一个屏幕控制对象
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
formatter2 = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s [line:%(lineno)d] : %(message)s')
# 文件操作符 和 格式关联
fh.setFormatter(formatter)
sh.setFormatter(formatter2)
# logger 对象 和 文件操作符 关联
logger.addHandler(fh)
logger.addHandler(sh)
logging.debug('debug message') # 低级别的 # 排错信息
logging.info('info message') # 正常信息
logging.warning('警告错误') # 警告信息
logging.error('error message') # 错误信息
logging.critical('critical message') # 高级别的 # 严重错误信息
configparser
# configparser处理配置文件
import configparser
# 写文件
config = configparser.ConfigParser() # 实例化
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9',
'ForwardX11':'yes'
}
config['bitbucket.org'] = {'User':'hg'}
config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'}
with open('example.ini', 'w') as f:
config.write(f)
"""效果:
[DEFAULT]
serveraliveinterval = 45
compression = yes
compressionlevel = 9
forwardx11 = yes
[bitbucket.org]
user = hg
[topsecret.server.com]
host port = 50022
forwardx11 = no
"""
# import configparser
#
# config = configparser.ConfigParser()
# #---------------------------查找文件内容,基于字典的形式
# # priprint(config.sections()) # ---> []
# ==============================
# config.read('example.ini')
# print(config.sections()) # ---> ['bitbucket.org', 'topsecret.server.com'] default 默认不显示
# 只要有就会用上
# print('bytebong.com' in config) # False
# print('bitbucket.org' in config) # True
# ===============================
# print(config['bitbucket.org']["user"]) # hg
# print(config['DEFAULT']['Compression']) #yes
# print(config['topsecret.server.com']['ForwardX11']) #no
# ==============================
# print(config['bitbucket.org']) # <Section: bitbucket.org> 地址,不是里边的全部
#
# for key in config['bitbucket.org']: # 注意,有default会默认default的键,不管循环那个default都会打印
# print(key)
# print(config.options('bitbucket.org')) # 同for循环,找到'bitbucket.org'下所有键
# =============================
#
# print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有键值对
# 列表返回,元祖,元祖中2各元素,key,value
# print(config.get('bitbucket.org','compression')) # yes get方法Section下的key对应的value
# ==================================
# 修改
# import configparser
# config = configparser.ConfigParser()
# config.read('example.ini') # 读文件
# config.add_section('yuan') # 增加section
# config.remove_section('bitbucket.org') # 删除一个section
# config.remove_option('topsecret.server.com',"forwardx11") # 删除一个配置项
# config.set('topsecret.server.com','k1','11111')
# config.set('yuan','k2','22222')
# f = open('new2.ini', "w")
# config.write(f) # 写进文件,注意不是原文件修改,改后重新写入
# f.close()
socket
# socket 应用层与传输层之间的抽象层
# 操作网络的接口
# 基于文件(本地通信),网络
# AF_INET ipv4(常用)
import socket
sk = socket.socket()
# sock.setsockopt(socket.SQL_SOCKET,socket.SO_REUSEADDR,1) # 服务重启时,可能端口未释放,报错,通过词此语句解决
# 报错socket没有SQL_SOCKET 不知道怎么回事,可能是版本问题
sk.bind(("127.0.0.1",8089)) # 只有一个参数,元祖,传入元祖
sk.listen() # listen(n) 表示最大连接数,默认不限制
conn,addr = sk.accept() # 接收到连接,返回连接对象,对方addr
ret = conn.recv(1024) # 接受对方数据
print(ret)
conn.send(b'hello world') # 必须bytes 不能发空b'' 否则一直等待
conn.send(bytes("段志方",encoding="utf8")) # 必须bytes 不能发空b'' 否则一直等待
conn.close() # 关闭连接
sk.close() # 关闭socket
# 发送发发送一次,接收方对于未接收完的字节可多次接受
# 但发送方 发送多次,接收方 要接受多次,不能一次接受
import socket
sk = socket.socket()
sk.connect(("127.0.0.1",8089)) # 对方的信息
# socket.connect(("106.15.39.74",80)) # 对方的信息
sk.send(b'dzf')
ret = sk.recv(1024)
ret2 = sk.recv(1024)
print(ret,ret2.decode("utf8"))
sk.close()
udp
# accept 与recv(1024) 都会阻塞,参数不写报错
import socket
msg = """
<html>
<head>
<title>first tcp test</title>
<meta charset="utf8"/>
</head>
<body>
Hello,段志方!
</body>
</html>
"""
msg = bytes(msg,encoding="utf8")
sk =socket.socket()
sk.bind(("127.0.0.1",80))
sk.listen()
while True:
conn,addr=sk.accept()
ret = conn.recv(1024)
print(ret)
conn.send(msg)
conn.close() # 若此时不关连接其他无法接入
sk.close()
# sk = socket.socket(type=socket.SOCK_DGRAM) # datagram
# sk.bind(("127.0.0.1",80))
# rece,addr = sk.recvfrom(1024) # 只能先接受消息
# print(rece.decode("gbk"))
# sk.sendto(b"hello",addr)
# sk.close()
# 服务器被动接收连接,自带地址,发信息时必须携带对方地址
import socket
# sk = socket.socket(type=socket.SOCK_DGRAM)
# ip_port = ("127.0.0.1",80)
# sk.sendto(b"hello",ip_port)
# ret,addr = sk.recvfrom(1024)
# print(ret)
# sk.close()
# 客户端执行 服务器发的系统命令
# op.popen() 返回执行后的信息,错误的,正确的
import subprocess
# 错误信息,正确信息,放入管道
res = subprocess.Popen("runas /user:Administrator ipconfig",shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
print("stdout:",res.stdout.read().decode("gbk"))
print("sterr:",res.stderr.read().decode("gbk"))
# 黏包 tcp 短时间间隔 发送短消息,tcp 会合并发送
# 大小有限制,一次发送太多数据,一次拿不完,要多次
# udp 无黏包,有包大小限制65507,若sendto大于它,会直接报错
# socket 应用层与传输层之间的抽象层
# 操作网络的接口
# 基于文件(本地通信),网络
# AF_INET ipv4(常用)
import socket
sk = socket.socket()
# sock.setsockopt(socket.SQL_SOCKET,socket.SO_REUSEADDR,1) # 服务重启时,可能端口未释放,报错,通过词此语句解决
# 报错socket没有SQL_SOCKET 不知道怎么回事,可能是版本问题
sk.bind(("127.0.0.1",8089)) # 只有一个参数,元祖,传入元祖
sk.listen() # listen(n) 表示最大连接数,默认不限制
conn,addr = sk.accept() # 接收到连接,返回连接对象,对方addr
ret = conn.recv(1024) # 接受对方数据
print(ret)
conn.send(b'hello world') # 必须bytes 不能发空b'' 否则一直等待
conn.send(bytes("段志方",encoding="utf8")) # 必须bytes 不能发空b'' 否则一直等待
conn.close() # 关闭连接
sk.close() # 关闭socket
# 发送发发送一次,接收方对于未接收完的字节可多次接受
# 但发送方 发送多次,接收方 要接受多次,不能一次接受
黏包
# import socket
# sk = socket.socket()
# sk.bind(("127.0.0.1",80))
# sk.listen()
# conn,addr=sk.accept()
# ret=conn.recv(2)
# ret2=conn.recv(1024)
# tcp:若客户端只发送一次,服务器两次接受, 不知道对方发送的长度
# tcp:连发两次,服务器可能一次接受(优化算法,连续小数据包会合并)
# 客户端,断开后,默认给服务器发空消息
# udp :服务器只接受一次,且只接受两个,剩余的就不接受了
# =========================================
# 黏包
# 两个send 小数据
# 两个recv 第一个接受的特别小
# 本质上 不知道要接受多大数据
# 解决方法:发送一下数据长度,在发送数据,
# 优点:确定接受多大数据,
# 可在配置项 设置, 一般防止多个连接情况 最大4MB
# 当要发送大数据时,明确告诉接收方多大,用于接受数据
# 用在多文件传输
# 大文件传输,一般读固定的字节
# 发送前 xxx send(4096)
# recv xxx recv(2048) 知道xxx变为0
# 缺点:多一次交互
# 但注意,send,sendto 一定量数据都会报错
# 解决方法struct
import struct
# 将数字或其他类型数据,转为固定长度的bytes 4个字节,其中可能包含字母,符号
ret = struct.pack("i",4096) # 模式,"i"代表将数字转换为bytes
print(ret)
num = struct.unpack("i",ret)
print(num) # (4096,) 返回元祖,通过num[0] 获取数字
"""
发送方:data
sk.send(struct.pack("i",len(data)))
sk.send(data)
接收方:
num = sk.recv(4)
sk.recv(int(num))
"""
# 自定义报文头
# 自己定义前n个字节存放报头信息
server_socket
# socket server
import socketserver
class Myserver(socketserver.BaseRequestHandler):
def handle(self): # self.request == conn
while True:
msg = self.request.recv(1024).decode("utf8")
if msg=='q':
break
print(msg)
info = input(">>>")
self.request.send(bytes(info,encoding="utf8"))
if __name__ == "__main__":
server = socketserver.ThreadingTCPServer(("127.0.0.1",8080),Myserver)
server.serve_forever()
socket其他方法
sk =socket.socket() sk.setblocking(False) sk.... sk.accept() # 会直接执行,经错此语句时若没有连接会报错,可用try,revc 方法也不会阻塞 sk.sendall() # 一次性发送全部数据 sk.send() # 分次发送,建议使用send