需求:
spout输出一些手机品牌小写名称,第一个bolt将手机名称转成大写,第二个bolt在手机名称的后面再追加上时间。
项目目录:

导入相关的jar包。
RandomWordSpout.java:
package com.darrenchan.storm; import java.util.Map; import java.util.Random; import backtype.storm.spout.SpoutOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichSpout; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.utils.Utils; public class RandomWordSpout extends BaseRichSpout { private SpoutOutputCollector collector; // 模拟一些数据 String[] words = { "iphone", "xiaomi", "mate", "sony", "sumsung", "moto", "meizu" }; // 不断地往下一个组件发送tuple消息 // 这里面是该spout组件的核心逻辑 @Override public void nextTuple() { // 可以从kafka消息队列中拿到数据,简便起见,我们从words数组中随机挑选一个商品名发送出去 Random random = new Random(); int index = random.nextInt(words.length); // 通过随机数拿到一个商品名 String godName = words[index]; // 将商品名封装成tuple,发送消息给下一个组件 collector.emit(new Values(godName)); // 每发送一个消息,休眠500ms Utils.sleep(500); } // 初始化方法,在spout组件实例化时调用一次 @Override public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { this.collector = collector; } // 声明本spout组件发送出去的tuple中的数据的字段名 @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("orignname")); } }
UpperBolt.java:
package com.darrenchan.storm; import backtype.storm.topology.BasicOutputCollector; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseBasicBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; public class UpperBolt extends BaseBasicBolt { // 业务处理逻辑 @Override public void execute(Tuple tuple, BasicOutputCollector collector) { // 先获取到上一个组件传递过来的数据,数据在tuple里面 String godName = tuple.getString(0); // 将商品名转换成大写 String godName_upper = godName.toUpperCase(); // 将转换完成的商品名发送出去 collector.emit(new Values(godName_upper)); } // 声明该bolt组件要发出去的tuple的字段 @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("uppername")); } }
SuffixBolt.java:
package com.darrenchan.storm; import java.io.FileWriter; import java.io.IOException; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Map; import java.util.UUID; import backtype.storm.task.TopologyContext; import backtype.storm.topology.BasicOutputCollector; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseBasicBolt; import backtype.storm.tuple.Tuple; import clojure.main; public class SuffixBolt extends BaseBasicBolt { FileWriter fileWriter = null; // 在bolt组件运行过程中只会被调用一次 @Override public void prepare(Map stormConf, TopologyContext context) { try { fileWriter = new FileWriter("/home/hadoop/stormoutput/" + UUID.randomUUID()); } catch (IOException e) { throw new RuntimeException(e); } } // 该bolt组件的核心处理逻辑 // 每收到一个tuple消息,就会被调用一次 @Override public void execute(Tuple tuple, BasicOutputCollector collector) { Date date = new Date(); SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss"); String format = sdf.format(date); // 先拿到上一个组件发送过来的商品名称 String upper_name = tuple.getString(0); String suffix_name = upper_name + "-" + format; // 为上一个组件发送过来的商品名称添加后缀 try { fileWriter.write(suffix_name); fileWriter.write(" "); fileWriter.flush(); } catch (IOException e) { throw new RuntimeException(e); } } // 本bolt已经不需要发送tuple消息到下一个组件,所以不需要再声明tuple的字段 @Override public void declareOutputFields(OutputFieldsDeclarer arg0) { } }
TopoMain.java:
package com.darrenchan.storm; import backtype.storm.Config; import backtype.storm.StormSubmitter; import backtype.storm.generated.AlreadyAliveException; import backtype.storm.generated.InvalidTopologyException; import backtype.storm.generated.StormTopology; import backtype.storm.topology.TopologyBuilder; /** * 组织各个处理组件形成一个完整的处理流程,就是所谓的topology(类似于mapreduce程序中的job) * 并且将该topology提交给storm集群去运行,topology提交到集群后就将永无休止地运行,除非人为或者异常退出 * */ public class TopoMain { public static void main(String[] args) throws Exception { TopologyBuilder builder = new TopologyBuilder(); // 将我们的spout组件设置到topology中去 // parallelism_hint:4 表示用4个excutor来执行这个组件 // setNumTasks(8) 设置的是该组件执行时的并发task数量,也就意味着1个excutor会运行2个task builder.setSpout("randomspout", new RandomWordSpout(), 4).setNumTasks(8); // 将大写转换bolt组件设置到topology,并且指定它接收randomspout组件的消息 // .shuffleGrouping("randomspout")包含两层含义: // 1、upperbolt组件接收的tuple消息一定来自于randomspout组件 // 2、randomspout组件和upperbolt组件的大量并发task实例之间收发消息时采用的分组策略是随机分组shuffleGrouping builder.setBolt("upperbolt", new UpperBolt(), 4).shuffleGrouping("randomspout"); // 将添加后缀的bolt组件设置到topology,并且指定它接收upperbolt组件的消息 builder.setBolt("suffixbolt", new SuffixBolt(), 4).shuffleGrouping("upperbolt"); // 用builder来创建一个topology StormTopology demotop = builder.createTopology(); // 配置一些topology在集群中运行时的参数 Config conf = new Config(); // 这里设置的是整个demotop所占用的槽位数,也就是worker的数量 conf.setNumWorkers(4); conf.setDebug(true); conf.setNumAckers(0); // 将这个topology提交给storm集群运行 StormSubmitter.submitTopology("demotopo", conf, demotop); } }
执行命令:storm jar stormdemo.jar com.darrenchan.storm.TopoMain demotopo
在weekend02和weekend03的stormoutput目录下,我们可以看到生成了我们想要的文件


我们随便看其中的一个文件:
tail -f 1293f751-ffa5-403f-a989-9860ba6cd9c8

会源源不断地输出。
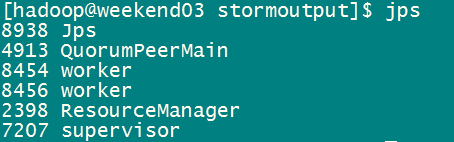
并且我们可以看到每台supervisor上面都有两个worker:

Topology运行机制
(1)Storm提交后,会把代码首先存放到Nimbus节点的inbox目录下,之后,会把当前Storm运行的配置生成一个stormconf.ser文件放到Nimbus节点的stormdist目录中,在此目录中同时还有序列化之后的Topology代码文件;
(2)在设定Topology所关联的Spouts和Bolts时,可以同时设置当前Spout和Bolt的executor数目和task数目,默认情况下,一个Topology的task的总和是和executor的总和一致的。之后,系统根据worker的数目,尽量平均的分配这些task的执行。worker在哪个supervisor节点上运行是由storm本身决定的;
(3)任务分配好之后,Nimbes节点会将任务的信息提交到zookeeper集群,同时在zookeeper集群中会有workerbeats节点,这里存储了当前Topology的所有worker进程的心跳信息;
(4)Supervisor节点会不断的轮询zookeeper集群,在zookeeper的assignments节点中保存了所有Topology的任务分配信息、代码存储目录、任务之间的关联关系等,Supervisor通过轮询此节点的内容,来领取自己的任务,启动worker进程运行;
(5)一个Topology运行之后,就会不断的通过Spouts来发送Stream流,通过Bolts来不断的处理接收到的Stream流,Stream流是无界的。
最后一步会不间断的执行,除非手动结束Topology。

有几点需要说明的地方:
(1)每个组件(Spout或者Bolt)的构造方法和declareOutputFields方法都只被调用一次。
(2)open方法、prepare方法的调用是多次的。入口函数中设定的setSpout或者setBolt里的并行度参数指的是executor的数目,是负责运行组件中的task的线程 的数目,此数目是多少,上述的两个方法就会被调用多少次,在每个executor运行的时候调用一次。相当于一个线程的构造方法。
(3)nextTuple方法、execute方法是一直被运行的,nextTuple方法不断的发射Tuple,Bolt的execute不断的接收Tuple进行处理。只有这样不断地运行,才会产生无界的Tuple流,体现实时性。相当于线程的run方法。
(4)在提交了一个topology之后,Storm就会创建spout/bolt实例并进行序列化。之后,将序列化的component发送给所有的任务所在的机器(即Supervisor节 点),在每一个任务上反序列化component。
(5)Spout和Bolt之间、Bolt和Bolt之间的通信,是通过zeroMQ的消息队列实现的。
(6)上图没有列出ack方法和fail方法,在一个Tuple被成功处理之后,需要调用ack方法来标记成功,否则调用fail方法标记失败,重新处理这个Tuple。
终止Topology:
通过在Nimbus节点利用如下命令来终止一个Topology的运行:
bin/storm kill topologyName
kill之后,可以通过UI界面查看topology状态,会首先变成KILLED状态,在清理完本地目录和zookeeper集群中的和当前Topology相关的信息之后,此Topology就会彻底消失。