Node.js--Stream
1. 概述
流(stream)在 Node.js 中是处理流数据的抽象接口(abstract interface)。 stream 模块提供了基础的 API 。使用这些 API 可以很容易地来构建实现流接口的对象。
流可以是可读的、可写的,或是可读写的。所有的流都是 EventEmitter 的实例。
2. Readable Stream(可读流)
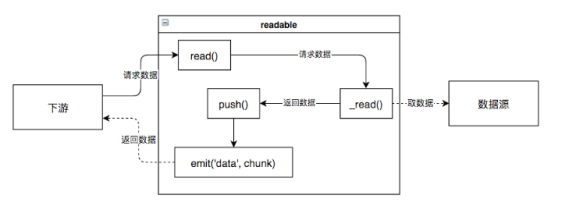
创建可读流时,需要继承Readable,并实现_read方法。
① _read方法是从底层系统读取具体数据的逻辑,即生产数据的逻辑。
② 在_read方法中,通过调用push(data)将数据放入可读流中供下游消耗。
③ 在_read方法中,可以同步调用push(data),也可以异步调用。
④ 当全部数据都生产出来后,必须调用push(null)来结束可读流。
⑤ 流一旦结束,便不能再调用push(data)添加数据。
// 继承Read class ToReadable extends Readable { constructor(iterable) { super() this.iterator = iterable } // 子类需要实现的方法 _read() { const res = this.iterator.next() if (res.done) { // 数据源枯竭 调用push(null)结束 this.push(null) } else { this.push(res.value+ ' ') } } } const iterable = function *(limit) { while(limit--) { yield Math.random() } }(100) const readable = new ToReadable(iterable) readable.on('data', data => process.stdout.write(data)) readable.on('end', ()=> process.stdout.write('end'))
下游通过read()方法来读取数据,并通过事件发射通知下游,内部相关逻辑如下图:
Readable Stream 具有两种模式,分别为 flowing 和 paused。
在 flowing 模式下, 可读流自动从系统底层读取数据,并通过 EventEmitter 接口的事件尽快将数据提供给应用。(即readable便会持续不断地调用_read(),通过触发data事件将数据输出)
在 paused 模式下,必须显式调用 stream.read() 方法来从流中读取数据片段。
可读流的“两种操作模式”是一种简单抽象。它抽象了在可读流实现(Readable stream implementation)内部发生的复杂的状态管理过程。
在任意时刻,任意可读流应确切处于下面三种状态之一:
readable._readableState.flowing = null
readable._readableState.flowing = false
readable._readableState.flowing = true
若 readable._readableState.flowing 为 null,由于不存在数据消费者,可读流将不会产生数据。 在这个状态下,监听 'data' 事件,调用 readable.pipe() 方法,或者调用 readable.resume() 方法, readable._readableState.flowing 的值将会变为 true 。这时,随着数据生成,可读流开始频繁触发事件。
调用 readable.pause() 方法, readable.unpipe() 方法, 或者接收 “背压”(back pressure), 将导致 readable._readableState.flowing 值变为 false。 这将暂停事件流,但 不会 暂停数据生成。 在这种情况下,为 'data' 事件设置监听函数不会导致 readable._readableState.flowing 变为 true。
readable.pause() 方法将会使 flowing 模式的流停止触发 'data' 事件, 进而切出 flowing 模式。任何可用的数据都将保存在内部缓存中。
调用readable.resume()可使流进入流动模式
主要相关API:
.isPause() // 返回可读流的当前操作状态。
.pause() // 将可读流的flowing模式切出。
.pipe() // 将可读流切入flowing模式,并自动将数据写到可写流,即自动管理数据流
.read() // 非flowing模式下,手动读取数据。
.resume() // 将暂定模式切入到flowing模式,触发data事件
3. Writable Stream(可写流)
创建可写流,需要继承Writable,并实现_write()方法。
① 上游通过调用writable.write(data)将数据写入可写流中。write()方法会调用_write()将data写入底层。
② 在_write中,当数据成功写入底层后,必须调用next(err)告诉流开始处理下一个数据。
③ next的调用既可以是同步的,也可以是异步的。
④ 上游必须调用writable.end(data)来结束可写流,data是可选的。此后,不能再调用write新增数据。
⑤ 在end方法调用后,当所有底层的写操作均完成时,会触发finish事件。
// 继承Write const Writable = require('stream').Writable class ToWritable extends Writable { constructor() { super() } _write(data, enc, next) { process.stdout.write(data) process.nextTick(next) } } const writable = new ToWritable() writable.on('finish', () => { process.stdout.write('DONE') }) writable.write('a') writable.write('b') writable.write('c') writable.end()
ws._write = function (chunk, enc, next) {
console.dir(chunk);
next();
};
第一个参数,chunk代表写进来的数据。
第二个参数enc代表编码的字符串,但是只有在opts.decodeString为false的时候你才可以写一个字符串。
第三个参数,next(err)是一个回调函数,使用这个回调函数你可以告诉数据消耗者可以写更多的数据。你可以有选择性的传递一个错误对象error,这时会在流实体上触发一个emit事件。
可写流有一个drain事件。
如果调用 stream.write(chunk) 方法返回 false,流将在适当的时机触发 'drain' 事件,这时才可以继续向流中写入数据。(在pipe会详细讲述)
主要相关API:
.cork() // 将强制所有写入数据都存放到内存中的缓冲区里。 直到调 用 stream.uncork() 或 stream.end() 方法时,缓冲区里的数据才会被输出。
.end() // 表明接下来没有数据要被写入 Writable。通过传入可选的 chunk 和 encoding 参数,可以在关闭流之前再写入一段数据。如果传入了可选的 callback 函数,它将作为 'finish' 事件的回调函数。
4. 流模式(objectMode )
所有使用 Node.js API 创建的流对象都只能操作 strings 和 Buffer(或 Uint8Array) 对象。但是,通过一些第三方流的实现,你依然能够处理其它类型的 JavaScript 值 (除了 null,它在流处理中有特殊意义)。 这些流被认为是工作在 “对象模式”(object mode)。
在创建流的实例时,可以通过 objectMode 选项使流的实例切换到对象模式。试图将已经存在的流切换到对象模式是不安全的。
对于可读流来说,push(data)时,data只能是String或Buffer类型,而消耗时data事件输出的数据都是Buffer类型。对于可写流来说,write(data)时,data只能是String或Buffer类型,_write(data)调用时传进来的data都是Buffer类型。
5. 缓冲(highWaterMark)
Writable 和 Readable 流都会将数据存储到内部的缓冲器(buffer)中。这些缓冲器可以 通过相应的 writable._writableState.getBuffer() 或 readable._readableState.buffer 来获取。
缓冲器的大小取决于传递给流构造函数的 highWaterMark 选项。 对于普通的流, highWaterMark 选项指定了总共的字节数。对于工作在对象模式的流, highWaterMark 指定了对象的总数。
当可读流的实现调用 stream.push(chunk) 方法时,数据被放到缓冲器中。如果流的消费者 没有调用 stream.read() 方法, 这些数据会始终存在于内部队列中,直到被消费。
当内部可读缓冲器的大小达到 highWaterMark 指定的阈值时,流会暂停从底层资源读取数据,直到当前 缓冲器的数据被消费 (也就是说, 流会在内部停止调用 readable._read() 来填充可读缓冲器)。
可写流通过反复调用 writable.write(chunk) 方法将数据放到缓冲器。 当内部可写缓冲器的总大小小于 highWaterMark 指定的阈值时, 调用 writable.write() 将返回true。 一旦内部缓冲器的大小达到或超过 highWaterMark,调用 writable.write() 将返回 false 。
6. Duplex 和 Transform(可读写流)、pipe(管道)
Duplex 创建可读可写流。
Duplex实际上就是继承了Readable和Writable的一类流。所以,一个Duplex对象既可当成可读流来使用(需要实现_read方法),也可当成可写流来使用(需要实现_write方法)。
Transform 创建读写过程中可以修改和变换数据的Duplex流
Tranform继承自Duplex,并已经实现了_read和_write方法,同时要求用户实现一个_transform方法。通过该方法对数据进行加工。
读写流主要应用于Pipe管道,也是Stream最强大的功能。即数据加工、功能抽象、背压机制反馈。
可以通过这样的代码来对数据加工read.pipe(red).pipe(bigger).pipe(write),把数据改成红色加大,代码清晰,每一个功能都很形象而且解耦得很好。
var rs = Readable() var c = 1; rs._read = function() { rs.push(String(c++)) if ( c > 100) rs.push(null) } var ts = Transform() ts._transform = function(buf, enc, next) { const res = buf*2 this.push(String(res)) next() console.log('') } rs.pipe(ts).pipe(process.stdout); var http = require('http'); var fs = require('fs'); var server = http.createServer(function (req, res) { let stream = fs.createReadStream('./123456.txt');//创造可读流 stream.pipe(res); // 将可读流写入response }); server.listen(8000);
Pipe背压机制反馈,理想的情况是下游消耗一个数据,上游才生产一个新数据,这样整体的内存使用就能保持在一个水平。(即避免消耗方消耗速度小于生产方生产数据的速度,缓存数据,占用大量内存)(Duplex和 Transform同理)
Pipe的核心实现:
- Readable.pause()
将可读流切到暂停模式,停止自动读取数据,只能通过.read()来读取数据触发data事件。
// pause var rs = Readable() var c = 97; rs._read = function() { rs.push(String(c++)) if ( c > 100) rs.push(null) } rs.pause() rs.on('data', (data)=> { process.stdout.write(' data: ' + data) }) var data = rs.read() while (data !== null) { process.stdout.write(' read: ' + data) data = rs.read() }
- Wrieable.drain事件
writable内部维护了一个写队列缓存,当这个队列长度达到某个阈值(state.highWaterMark)时,执行write()时返回false,否则返回true。 当缓存清空时,就会触发drain事件。
// drain // 向可写流中写入数据一百万次。 // 需要注意背压 (back-pressure)。 function writeOneMillionTimes(writer, data, encoding, callback) { let i = 1000000; write(); function write() { let ok = true; do { i--; if (i === 0) { // 最后 一次 writer.write(data, encoding, callback); } else { // 检查是否可以继续写入。 // 这里不要传递 callback, 因为写入还没有结束! ok = writer.write(data, encoding); } } while (i > 0 && ok); if (i > 0) { // 这里提前停下了, // 'drain' 事件触发后才可以继续写入 writer.once('drain', write); } } }
- Pipe内部实现
当write()返回false时,调用readable.pause()使上游进入暂停模式,不再触发data事件。
但是当writable将缓存清空时,会触发一个drain事件,再调用readable.resume()使上游进入流动模式,继续触发data事件。
// pipe的核心实现 readable.on('data', function (data) { if (false === writable.write(data)) { readable.pause() } }) writable.on('drain', function () { readable.resume() })
参考: https://tech.meituan.com/stream-basics.html