1.Objection localization
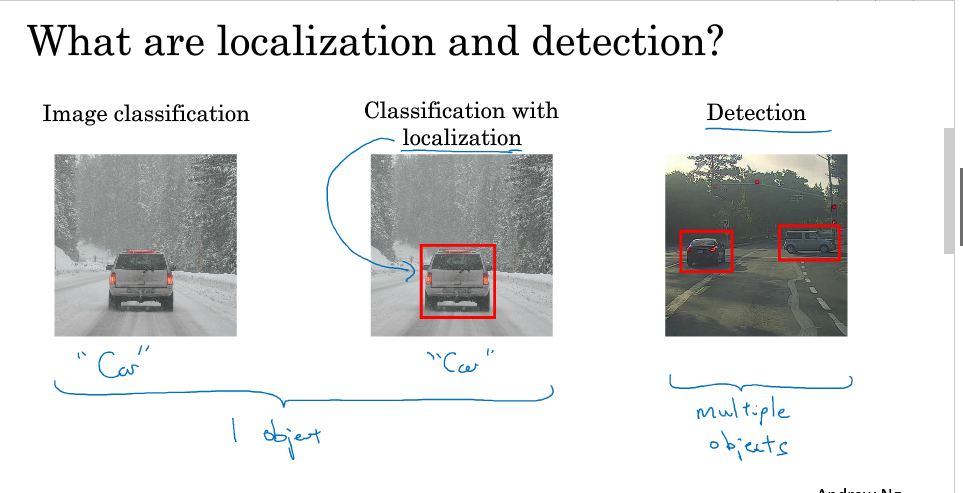
图片检测问题分为:
1.图片分类:是否为汽车(结果只为单个对象)
2.分类与定位:是否为汽车 ,汽车位置(结果只为单个对象)
3.目标检测: 检测不同物体 并定位(结果可能含多个对象)
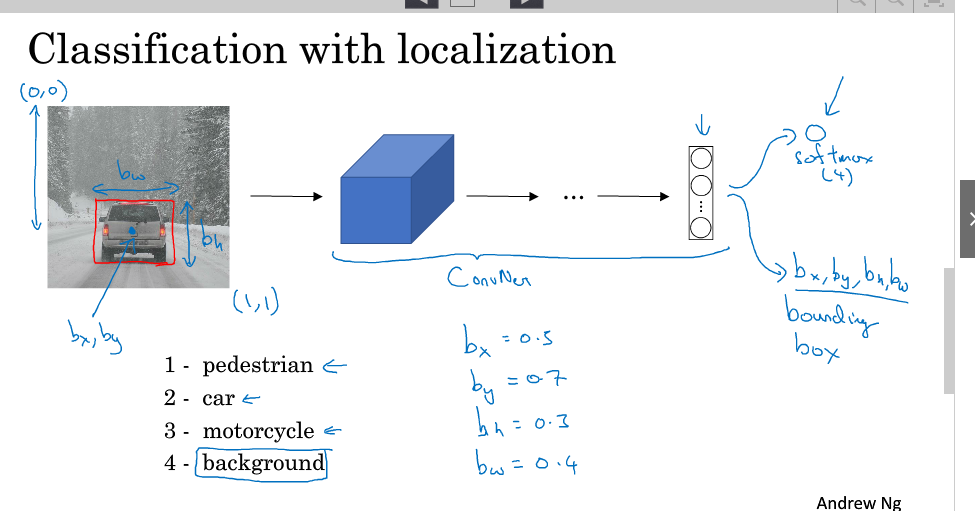
分类与定位的表示:
分类与定位的输出层可用如下表示:
1.Pc 是否存在
2.bx 目标中心的坐标 x
3.by 目标中心的坐标 y
4.bH 目标高度
5.bW 目标宽度
6.C1 是否为分类1
7.C2 是否为分类2
8.C3 是否为分类3

模型训练时,bx、by、bh、bw都由人为确定其数值。
损失函数:
- Pc=1,即y1=y^1=1:
L(y^,y)=(y^1−y1)2+(y^2−y2)2+⋯+(y^8−y8)2L(y^,y)=(y^1−y1)2+(y^2−y2)2+⋯+(y^8−y8)2
- Pc=0,即y1=0y1=0
L(y^1,y)=(y^1-y1)2
当然在实际的目标定位应用中,我们可以使用更好的方式是:
- 对 c1、c2、c3 通过 softmax 输出;
- 对边界框的四个值应用平方误差或者类似的方法;
- 对 Pc 应用 logistic regression 损失函数,或者平方预测误差。
比较而言,平方误差已经能够取得比较好的效果。

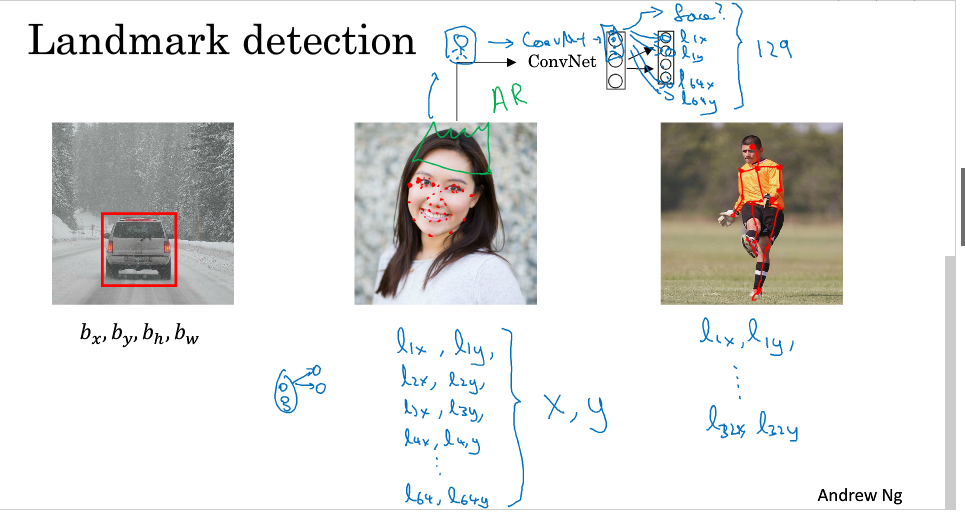
2.Landmark detection
除上述的矩形检测外,还可以对目标的关键点特征进行一个检测
其输出为:
1.Pc
2.l1_x,l1_y (记录关键点点特征的位置)
3.l2_x,l2_y
..........
我们通过标定训练数据集中特征点的位置信息,来对人脸进行不同位置不同特征的定位和标记。AR的应用就是基于人脸表情识别来设计的,如脸部扭曲、增加头部配饰等。
在人体姿态检测中,同样可以通过对人体不同的特征位置关键点的标注,来记录人体的姿态。
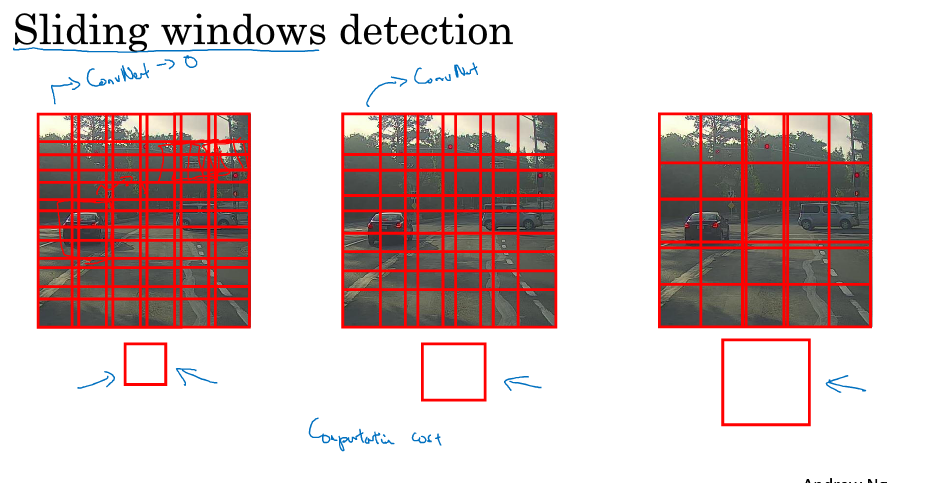
3.Objection detection
目标检测的一种简单算法是滑动窗口检测
首先:搜集一些目标图片和非目标图片作为训练集的样本进行训练得到一个CNN模型 如下图:
注意:训练集图片尺寸较小,尽量仅包含相应目标

然后从测试图片选择合适的窗口,进行从左到右,从上到下的滑动,对每一个窗口使用已经训练好的CNN模型,观察是否有该目标.
若判断有目标,则此窗口即为目标区域;若判断没有目标,则此窗口为非目标区域。
优点:原理简单,且不需要人为选定目标区域(检测出目标的滑动窗即为目标区域)。
缺点:滑动窗口的大小,步长过大选取都会影响到目标检测到的成功率. 由于会对每个选取的窗口进行CNN网络计算,如果步长小,则会造成计算量大,性能低下.
总而言之,滑动窗口算法不够快,不够灵活
4.Convolutional implentation of sliding windows
卷积实现滑动窗口
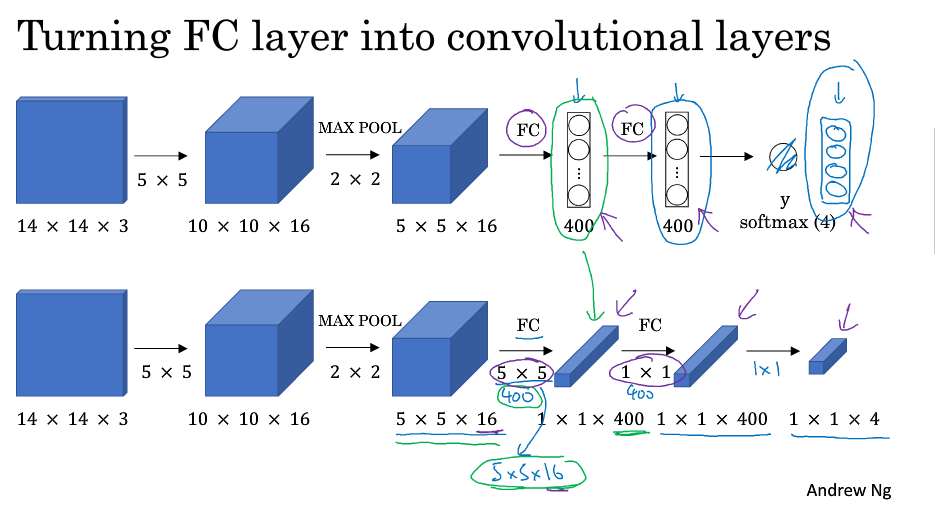
将全连接层转为卷积层:
在上一周课程中,Ng讲授过 1×1 的卷积核相当于在一个三维图像的切片上应用了一个全连接的神经网络。同样,全连接层也可以由 1×1 大小卷积核的卷积层来替代。需注意卷积核的个数与隐层神经元个数相同(即保证输出具有相同的channel)。
最终得到的输出层维度是1 x 1 x 4,代表4类输出值。
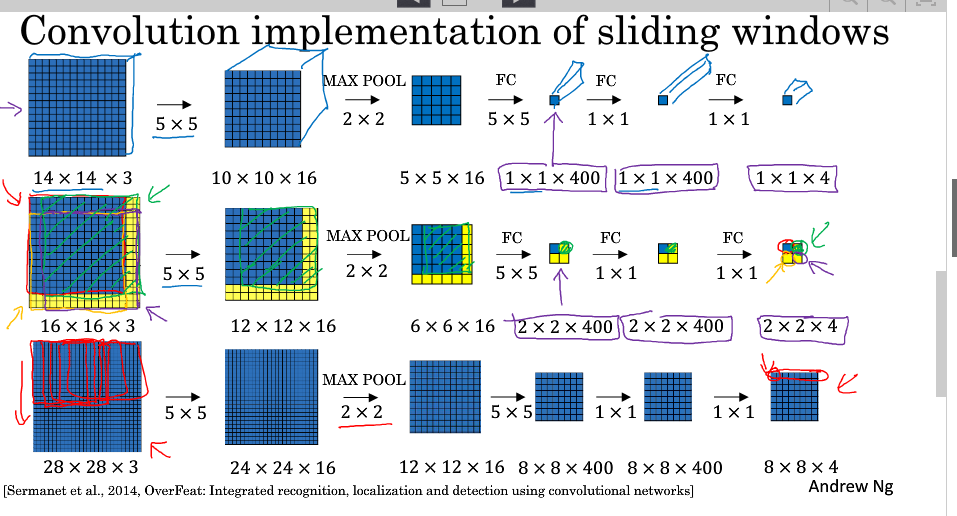
我们以训练好的模型,输入一个16x16x3大小的整幅图片,图中蓝色部分代表滑动窗口的大小。我们以2为大小的步幅滑动窗口,分别与卷积核进行卷积运算,最后得到4幅10×10×16大小的特征图,然而因为在滑动窗口的操作时,输入部分有大量的重叠,也就是有很多重复的运算,导致在下一层中的特征图值也存在大量的重叠,所以最后得到的第二层激活值(特征图)构成一副12×12×16大小的特征图。对于后面的池化层和全连接层也是同样的过程。
那么由此可知,滑动窗口在整幅图片上进行滑动卷积的操作过程,就等同于在该图片上直接进行卷积运算的过程。所以卷积层实现滑动窗口的这个过程,我们不需要把输入图片分割成四个子集分别执行前向传播,而是把他们作为一张图片输入到卷积神经网络中进行计算,其中的重叠部分(公共区域)可以共享大量的计算.
值得一提的是,窗口步进长度与选择的MAX POOL大小有关。如果需要步进长度为4,只需设置MAX POOL为4 x 4即可。
依据上面的方法,我们将整张图片输入到训练好的卷积神经网络中。无需再利用滑动窗口分割图片,只需一次前向传播,我们就可以同时得到所有图片子集的预测值。
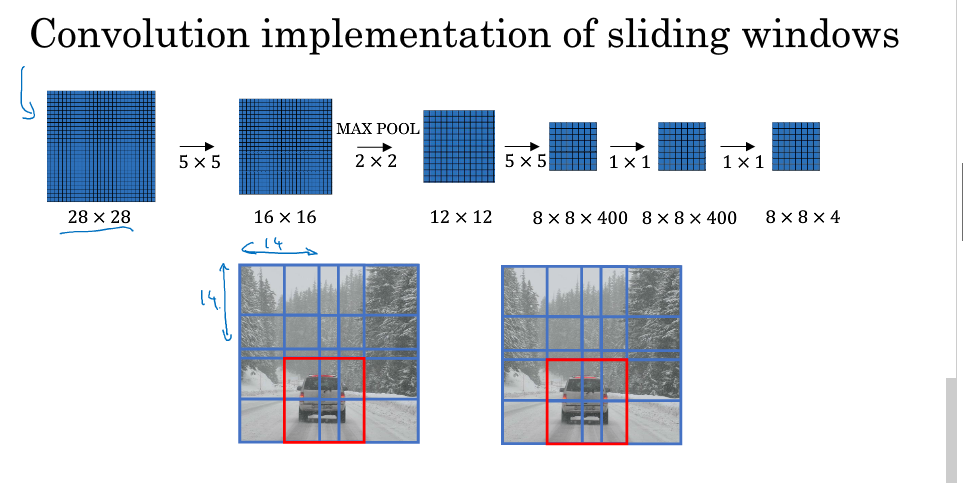
5.Bounding Box Prodiction
滑动窗口算法所存在的问题,可能无法精准的输出边界框

为解决这个问题,我们可以采用YOLO(You Only Look Once)算法
YOLO算法:将目标图片划分为N X N个区域,为了简便,接下来的都划分为 3 X3,
然后对每一个小区域都采用目标检测与定位的算法,每一个小区域的输出和之前所讲的分类与定位的输出是一致的

其中当前区域的Pc=0时,即是检测到的目标中心不再此区域中,反之,则在此区域 (这里不明白它是怎么判断目标中心在此区域的,如果在某个区域内检测到目标的部分,就可以判断其中心是否在此区域吗,它又如何判断它的完整边界).
YOLO是一次卷积实现,并不是在 n×n 网格上进行n^2运算,而是单次卷积实现,算法实现效率高,运行速度快,可以实现实时识别。
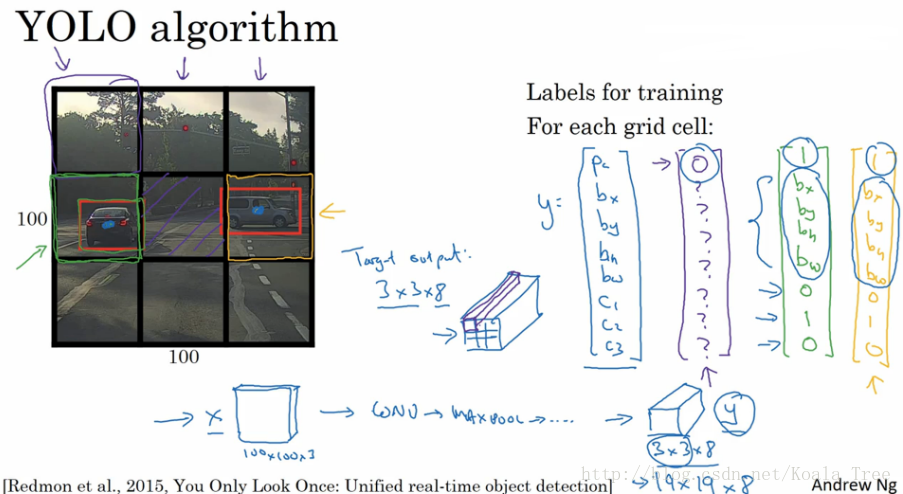
bounding boxes 细节:
利用YOLO算法实现目标探测的时候,对于存在目标对象的网格中,定义训练标签Y的时候,边界框的指定参数的不同对其预测精度有很大的影响。这里给出一个较为合理的约定:(其他定值方式可阅读论文)
- 对于每个网格,以左上角为(0,0),以右下角为(1,1);
- 中点bx、by表示坐标值,在0~1之间;
- 宽高bh、bw表示比例值,存在>1的情况。 (不理解如何判断其完整bounding boxes)
6.Intersection-Over-Union
Intersection-Over-Union是用来评估其Bounding boxes检测是否准确的,计算公式为:
IoU=I/U
一般在目标检测任务中,约定如果 IoU⩾0.5 ,那么就说明检测正确。当然标准越大,则对目标检测算法越严格。得到的IoU值越大越好。:

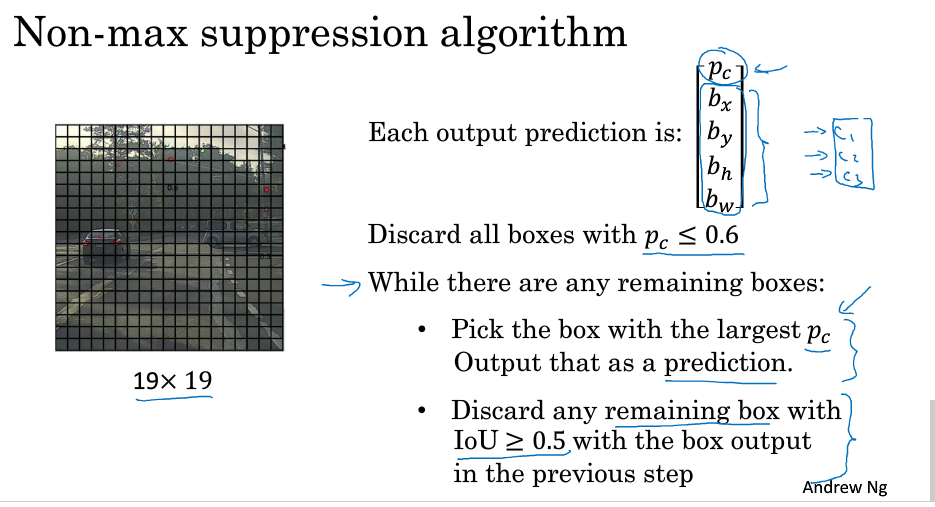
7.Non-max suppression
YOLO算法中,若是邻近的区域都被判断有同一个目标时,该如何选择,如下:

non-max suppression(非极大值抑制):
1.去掉 Pc<阈值的所有网格
2.对于剩下的,先选取其中Pc最大的,在利用IoU,屏蔽与其交叠较大的网格,重复这个过程,直到结束
8.Anchor boxes
之前介绍的都是一个网格只存在一个object的情况,对于一个grid cell存在多个object的情况该如何处理?
引入Anchor boxes
只是在输出中加了个与Anchor box相对应的分量
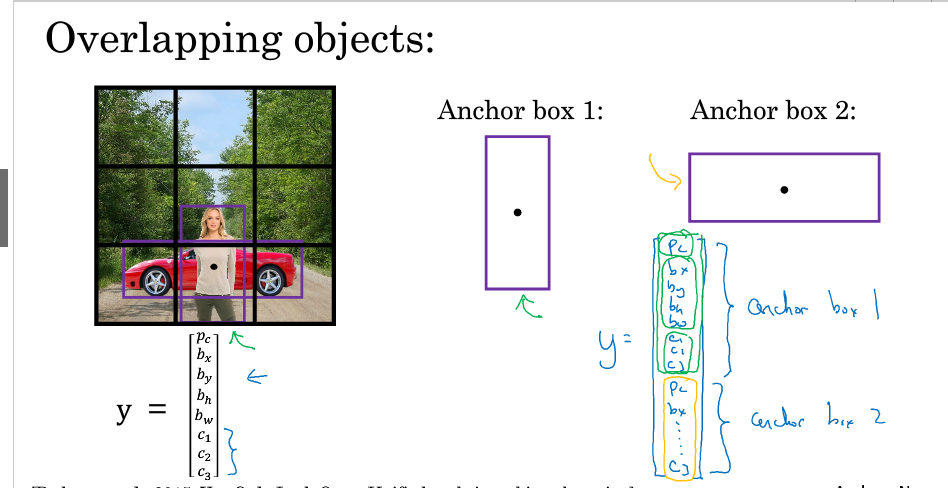
在进行YOLO算法时,其选取方法与上节的非极大值抑制一样,只是分别对每一个Anchor box 进行 NMS.
难点问题:
-
如果我们使用了两个Anchor box,但是同一个格子中却有三个对象的情况,此时只能用一些额外的手段来处理;
-
同一个格子中存在两个对象,但它们的Anchor box 形状相同,此时也需要引入一些专门处理该情况的手段。
但是以上的两种问题出现的可能性不会很大,对目标检测算法不会带来很大的影响。
Anchor box 的选择:
-
一般人工指定Anchor box 的形状,选择5~10个以覆盖到多种不同的形状,可以涵盖我们想要检测的对象的形状;
-
高级方法:K-means 算法:将不同对象形状进行聚类,用聚类后的结果来选择一组最具代表性的Anchor box,以此来代表我们想要检测对象的形状。

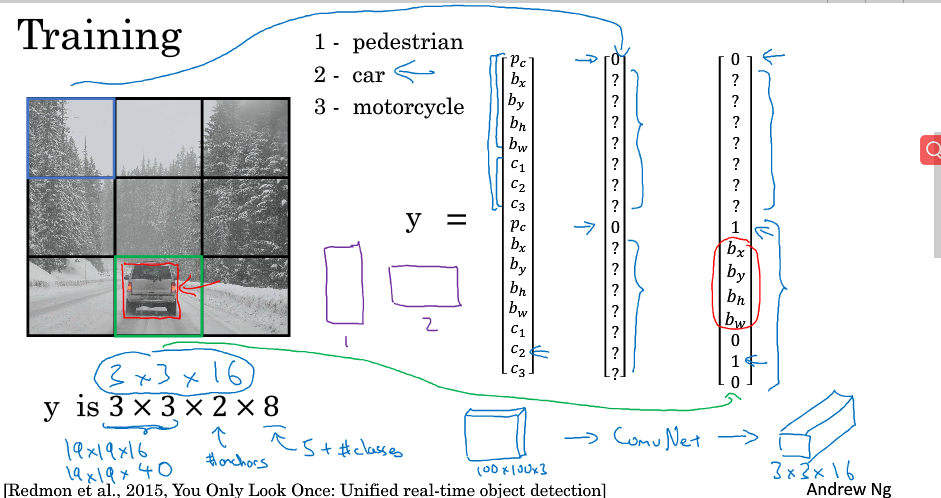
9.Putting it togerther YOLO agorithm
此节即是对之前的进行总结,内容如下:

10.Region Proposal (Optional)
R-CNN:
R-CNN(Regions with convolutional networks),会在我们的图片中选出一些目标的候选区域,从而避免了传统滑动窗口在大量无对象区域的无用运算。
所以在使用了R-CNN后,我们不会再针对每个滑动窗口运算检测算法,而是只选择一些候选区域的窗口,在少数的窗口上运行卷积网络。
具体实现:运用图像分割算法,将图片分割成许多不同颜色的色块,然后在这些色块上放置窗口,将窗口中的内容输入网络,从而减小需要处理的窗口数量。

Region Proposals共有三种方法:
-
R-CNN: 滑动窗的形式,一次只对单个区域块进行目标检测,运算速度慢。
-
Fast R-CNN: 利用卷积实现滑动窗算法,类似第4节做法。
-
Faster R-CNN: 利用卷积对图片进行分割,进一步提高运行速度。
比较而言,Faster R-CNN的运行速度还是比YOLO慢一些。
补充:参考自https://blog.csdn.net/red_stone1/article/details/79028058
https://blog.csdn.net/Dby_freedom/article/details/79865515