最近接连听说一台线上服务器总是不响应客户端请求。
登录服务器后查询iis状态,发现应用程序池状态变为已停止。
按经验想,重启后应该就ok,第一次遇到也确实起了作用,当时完全没在意,以为是其他人无意把服务关闭了而已。
但是之后几天几乎每天都出现问题,应用程序池再次成为 已停止 状态。这个情况显然有问题。于是开始排查设置。
线上环境很简单,iis + API应用,数据库在内网上,没有反向代理。
出问题的应用程序池承载了一个基础数据API,查询量极小,数据量也极小,只是因为同事做实现时提过,查询很麻烦,所以我让他同时也检查代码的查询是否过于繁琐产生超出设置上限的资源占用。
但根据同事检查结果,这个情况不存在,数据库查询响应非常快,服务器的资源监控上看相关进程也没有出现明显的资源飙升。因此判断服务端代码应该没有问题。
经验路线在这里就走不通了,只能尝试在设置上找原因。 iis对应用程序池的设置里最可能影响服务的是回收策略的设置。为了避免影响其他服务,部署时设置了这个api的专用内存上限到1GB。当然,既然代码检查没有问题,测试运行也没发现资源飙升的情况,回收的专用内存上限应该不会轻易触发。但是还是检查了设置,毕竟从前有同事设置时把1GB给成了100M,除了登录之外执行不了任何请求。
最终想到用netstat检查端口情况。起初的怀疑是端口被其他进程无意占用导致问题。
启动netstat后,让测试发了几次请求,顺利看到进程出现在列表,且没有端口冲突,对端地址经查证是来自app。当然,也注意到服务器状态是一堆 Close_Wait.
当然我经验少,Close_Wait还真是第一次见。不过既然状态不是Established,这个应该就是问题的原因了。开始查资料,学习Close_Wait状态是什么情况。
对于 服务器的连接状态而言,一般有三种比较常见的: Established、 Time_Wait、Close_Wait。
从别人博客上扒了一张原理图:
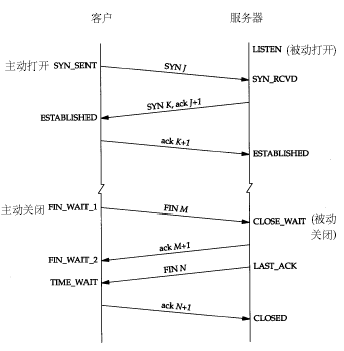
通过原理图,我们知道了CLOSE_WAIT是被动关闭的状态。什么意思呢?比如客户端发了个请求,正常情况下是会收到服务器响应一个状态的,即Response。当客户端读取了这个返回后,会主动告诉服务器收到了,关闭连接。
由于是客户端发起关闭连接的请求,在TCP协议下双方需要通过四个包的互发完成双向确认工作,才能最终关闭这个连接。
客户端要求关闭,此时客户端状态为 FIN_WAIT_1,同时向服务器发送了 FIN 包,服务器状态变更为CLOSE_WAIT;
当然,服务器需要对收到FIN包向客户端确认,于是服务器向客户端发送了 ACK 包,客户端因此变更状态为FIN_WAIT_2;
服务器处理了这个确认后,再次主动向客户端发送FIN包,同时自己状态变更为LAST_ACK,收到来自服务器FIN包的客户端也将自己状态变更为TIME_WAIT;
最后一步,客户端会对来自服务器的FIN包回复确认,服务器收到该ACK包后,将自己状态置为CLOSED,如此,整个关闭过程结束。
简单说就是,客户端 -》 服务器,我要关闭,服务器回复OK,并开始处理后续;服务器后续处理好后,再告诉客户端我可以关闭了,客户端确认,服务端关闭。
所以,出现CLOSE_WAIT状态的原因是,服务器一端因故没有向客户端发出FIN包,即服务端的LAST_ACK -- FIN -->客户端这步没能执行。
因此,看到CLOSE_WAIT状态后,那么可以确定服务器没有执行后续动作,即调用socket.Close()。
举一反三,即谁被动关闭,则谁的连接释放代码有问题。
但是socket.Close()的调用应当是由web服务器自己完成呀,所以问题还没确定。写api的同事轻描淡写提了一下说代码没关闭链接,但越想越不对。到底什么原因导致没有进行socket.Close(),还需要具体从代码入手。
不过,虽然没有真正搞明白我们遇到的原因,但是原理清楚了,排查的时候还顺手看到客户端的代码存在的问题。后续搞清楚了再更。
【1212更新】
终于有空来继续查这个问题了。
前次排查的时候,在没有完全理顺这个原理的情况下认为是客户端(Android)上一段关于登陆请求的超时处理问题。我是被几篇HttpClient的文章干扰了。在那几篇文章里,作者说是因为调用HttpClient组件后,没有对请求资源进行释放(即Response.Body.Dispose()),因此造成了CLOSE_WAIT状态。 但作者没说清楚。就像前文分析的一样,服务端出现CLOSE_WAIT,根本问题一定是服务端的代码有问题。当然,既然排故,就顺便一说。在同事的请求部分代码上,设置了Timeout时间,并且做了不太安全的异常处理:
1 ... 2 Response res = client.newCall(request).execute(); 3 if(res.isSuccessful()){ 4 return res.body().string(); 5 } 6 else{ 7 throw new IOException("Unexpected code" + res); 8 } 9 ...
并且这段代码在一组try catch 内部,且仅catch了IOException 【我没细看OKClient的文档,不清楚是否有其他的Ex可能性】
这段代码的问题在于,一定要使用try catch进行流程控制并不合理。此外,response会带有服务端返回的标准Http 状态,因此此处对非200状态的处理过于粗糙,浪费性能。 所以在服务端出现大量CLOSE_WAIT后,这里应该收到大量的500状态,非200只需要正常输出信息并做相应操作即可。
【像Try catch这样的代码,更好的使用方式是用于做应对不可预料的错误,而不是逻辑分支控制。大多数的错误应当由正常的检验代码进行处理。】
但是这部分代码最多给客户端造成问题,不会导致服务端出错。
因此,我们转回看服务端问题。
因为出问题的只有Login操作,于是在清楚问题的原理后,同事为Login操作加上了超时的判定。所以我的余下分析只能在修改后的代码上进行。
public void TLogin(string username, string pwd,out string resultJson) { using (RtuHmiEntities db = new RtuHmiEntities()) { var user = db.Base_Users.Where(x => x.UserCode == username && x.Password == pwd).ToList(); if (user.Count() == 0) { resultJson = user.ToJSON(); return; } var siteList = db.SiteTable.Select(x => new { ID = x.Id, Name = x.SiteName }).ToList(); var dtuList = db.DtuTable.Where(x => x.SiteId == null).Select(x => new { ID = x.ID, Name = x.DtuName }).ToList(); var regularboxList = db.PressBoxTable.Select(x => new { ID = x.Id, Name = x.BoxName }).ToList(); var valveList = db.ValveChamber.Select(x => new { ID = x.Id, Name = x.Name }).ToList(); var result = new { Stations = siteList, BusinessUsers = dtuList, Regularboxes = regularboxList, Valverooms = valveList }; resultJson = result.ToJSON(); } }
当然,仔细看了登陆操作的业务代码后,我们能发现一些问题。在这个项目上,登陆后需要初始化一些列表类的信息给客户端。这里的操作当然没什么问题。因为同事在参与这个项目时,不止一次向我抱怨数据库设计有问题,查询很繁琐。但是我没有在这个项目上,所以没有具体关注数据库设计的缺陷。
不过从这段代码看,前端需要接受4组信息,分别是 Stations、 BusinessUsers、 RegularBoxes、 Valverooms,数据库给了四张表。这里采用Linq进行查询操作。一般说来,问题不大。实际上,这段代码里查表的部分实际的执行也没有任何明显性能不足的情况。硬挑的话,第一个分支里对空集合转Json反倒会产生不必要的损失。即便如此,在正常情况下,请求执行时间在200ms以内。
既然代码在测试下并没有什么问题,那原因在哪呢?
回想了一下,IIS有一项设置是回收策略的。因为原先遇到过因为回收没有自己定义,几个旧版的很占资源的API还没更新的时候就在回收周期内把服务器资源吃满了,导致其他api无法运行。所以后来会根据测试时的资源情况为线上服务器设置这个回收值。当然,对于一个不怎么复杂的查询类API而言,并不需要多大的资源。于是第一次设置计划给200M的专用内存。不过显然,因为某一两个数据量比较大的API在短时内重复请求,造成了回收,此时登陆测试碰巧遭遇了释放,于是就造成了上述 服务端被动关闭连接,且没有继续向客户端返回FIN包的状态,最终产生了几条CLOSE_WAIT。
回想一下,大家遇到的CLOSE_WAIT基本上都是大量出现,而我们遇到的情况只有少量的几条,远没达到客户端测试的请求数量。排查下来看也确实是调试的时候遇到的小概率问题。不过不清楚原理的话,排查起来还是很没头绪的。论理论的必要性。在大多数时候,不需要那么精通理论能做到80分,但是想做到99分甚至更高,就是拼对理论的理解深度了。
【Finally,解决方案】
实际上我们为这个问题修正了三个地方。
第一是对客户端代码上做了修改,改进非200请求的反馈方式。
第二是将iis的回收策略修改,提高了专用内存的上限,降低回收时间间隔【看来从实际出发,这样做更有效】
第三,依然对服务端代码进行了修改,对部分请求增加了超时的处理,至于发现的不太利于性能的代码,也会在重构时改进。
当然,对这个问题贡献比较大的是前两条。毕竟出现的主要情况还是服务端被动关闭。
这个问题我当然还没研究的太深。如果有错误请务必指出。
相关资料:
http://blog.csdn.net/shootyou/article/details/6622226
http://mp.weixin.qq.com/s?__biz=MzI4MjA4ODU0Ng==&mid=402163560&idx=1&sn=5269044286ce1d142cca1b5fed3efab1&3rd=MzA3MDU4NTYzMw==&scene=6#rd
感谢以上优秀的技术文章。