HTTP keep-alive和TCP keepalive
TCP Keepalive的起源
TCP协议中有长连接和短连接之分。短连接环境下,数据交互完毕后,主动释放连接;
长连接的环境下,进行一次数据交互后,很长一段时间内无数据交互时,客户端可能意外断电、死机、崩溃、重启,还是中间路由网络无故断开,这些TCP连接并未来得及正常释放,那么,连接的另一方并不知道对端的情况,它会一直维护这个连接,长时间的积累会导致非常多的半打开连接,造成端系统资源的消耗和浪费,且有可能导致在一个无效的数据链路层面发送业务数据,结果就是发送失败。所以服务器端要做到快速感知失败,减少无效链接操作,这就有了TCP的Keepalive(保活探测)机制。
TCP Keepalive工作原理
当一个 TCP 连接建立之后,启用 TCP Keepalive 的一端便会启动一个计时器,当这个计时器数值到达 0 之后(也就是经过tcp_keep-alive_time时间后,这个参数之后会讲到),一个 TCP 探测包便会被发出。这个 TCP 探测包是一个纯 ACK 包(规范建议,不应该包含任何数据,但也可以包含1个无意义的字节,比如0x0。),其 Seq号 与上一个包是重复的,所以其实探测保活报文不在窗口控制范围内。
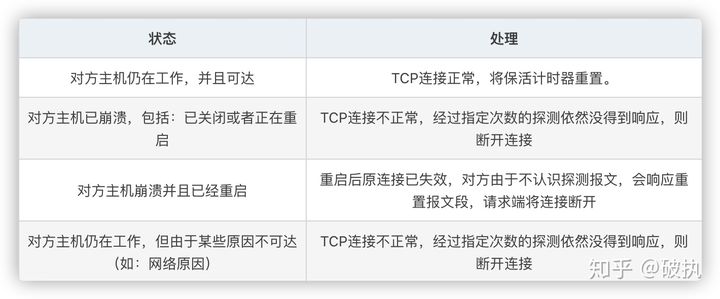
如果一个给定的连接在两小时内(默认时长)没有任何的动作,则服务器就向客户发一个探测报文段,客户主机必须处于以下4个状态之一:
-
客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方是正常的,服务器在两小时后将保活定时器复位。
-
客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的TCP都没有响应。服务端将不能收到对探测的响应,并在75秒后超时。服务器总共发送10个这样的探测 ,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。
-
客户主机崩溃并已经重新启动。服务器将收到一个对其保活探测的响应,这个响应是一个复位,使得服务器终止这个连接。
-
客户机正常运行,但是服务器不可达,这种情况与2类似,TCP能发现的就是没有收到探测的响应。
对于linux内核来说,应用程序若想使用TCP Keepalive,需要设置SO_KEEPALIVE套接字选项才能生效。
有三个重要的参数:
-
tcp_keepalive_time,在TCP保活打开的情况下,最后一次数据交换到TCP发送第一个保活探测包的间隔,即允许的持续空闲时长,或者说每次正常发送心跳的周期,默认值为7200s(2h)。 -
tcp_keepalive_probes 在tcp_keepalive_time之后,没有接收到对方确认,继续发送保活探测包次数,默认值为9(次) -
tcp_keepalive_intvl,在tcp_keepalive_time之后,没有接收到对方确认,继续发送保活探测包的发送频率,默认值为75s。
其他编程语言有相应的设置方法,这里只谈linux内核参数的配置。例如C语言中的setsockopt()函数,java的Netty服务器框架中也提供了相关接口。
TCP Keepalive作用
-
探测连接的对端是否存活
在应用交互的过程中,可能存在以下几种情况:
(1)客户端或服务器意外断电,死机,崩溃,重启。
(2)中间网络已经中断,而客户端与服务器并不知道。
利用保活探测功能,可以探知这种对端的意外情况,从而保证在意外发生时,可以释放半打开的TCP连接。
-
防止中间设备因超时删除连接相关的连接表
中间设备如防火墙等,会为经过它的数据报文建立相关的连接信息表,并为其设置一个超时时间的定时器,如果超出预定时间,某连接无任何报文交互的话,
中间设备会将该连接信息从表中删除,在删除后,再有应用报文过来时,中间设备将丢弃该报文,从而导致应用出现异常。
此段参考:https://www.cnblogs.com/hukey/p/5481173.html
TCP Keepalive可能导致的问题
Keepalive 技术只是 TCP 技术中的一个可选项。因为不当的配置可能会引起一些问题,所以默认是关闭的。
可能导致下列问题:
-
在短暂的故障期间,Keepalive设置不合理时可能会因为短暂的网络波动而断开健康的TCP连接 -
需要消耗额外的宽带和流量 -
在以流量计费的互联网环境中增加了费用开销
实验
这里,强烈推荐《TCP/IP详解 卷1:协议》的第二版(这里一定是第二版), 第17章:TCP保活机制。这里建议17章都看,17.1和17.2小节就涵盖了我上面介绍的内容。
17.2.1 小节中还通过实验的方式详细验证了“对端主机会处于以下四种状态”以及对于这四种状态TCP都是如何去处理。
这本书中的实验已经比较通俗易懂了,我暂且没有亲自动手去模拟实践,后续时间充足,会亲自动手进行实验。
扩展
上面提到了三个参数保活时间:tcp_keepalive_time、探测时间间隔:tcp_keepalive_intvl、探测循环次数:tcp_keepalive_probes。
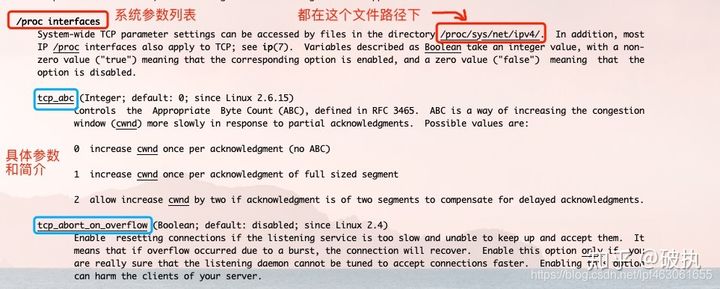
这三个参数,在linux上可以在/proc/sys/net/ipv4/路径下找到,或者通过sysctl -a | grep keepalive命令查看当前内核运行参数。
[root@vm01 ~]# cd /proc/sys/net/ipv4
[root@vm01 ipv4]# pwd
/proc/sys/net/ipv4
[root@vm01 ipv4]# cat /proc/sys/net/ipv4/tcp_keepalive_time
7200
[root@vm01 ipv4]# cat /proc/sys/net/ipv4/tcp_keepalive_probes
9
[root@vm01 ipv4]# cat /proc/sys/net/ipv4/tcp_keepalive_intvl
75
[root@vm01 ipv4]# sysctl -a | grep keepalive
net.ipv4.tcp_keepalive_time = 7200
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_intvl = 75
- 保活时间(tcp_keepalive_time)默认:7200秒
- 保活时间间隔(tcp_keepalive_intvl)默认:75秒
- 探测循环次数(tcp_keepalive_probes)默认:9次
也就是默认情况下一条TCP连接在2小时(7200秒)都没有报文交换后,会开始进行保活探测,若再经过9*75秒=11分钟15秒的循环探测都未收到探测响应,即共计:2小时11分钟15秒后会自动断开TCP连接。
别走开,还有一个骚操作
Linux平台下我们还可以借助man命令查看TCP协议的一些描述和参数定义。下面两个命令的效果相同:
- 命令一:
man tcp - 命令二:
man 7 tcp
数字7的含义是:man命令使用手册共9章,TCP的帮助手册位于第7章。不知道在第几章也无所谓,使用man tcp也可,弹出的手册左上角也有写第几章。(man ls等同于man 1 ls、man ip等同于man 8 ip,可以自己尝试使用 )。
下面我们看下man tcp下的和我们本文有关的几个点:

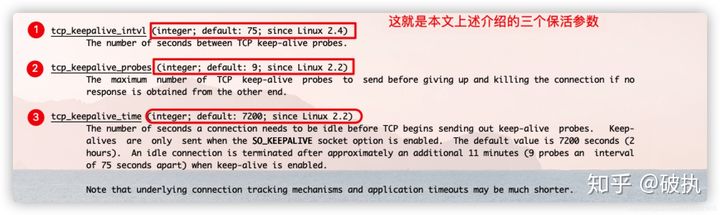
上面介绍的三个参数tcp_keepalive_time、tcp_keepalive_intvl、tcp_keepalive_probes都是系统级别的,针对整个系统生效。下面介绍针对单条Socket连接细粒度设置的三个选项参数:保活时间:TCP_KEEPIDLE、保活探测时间间隔:TCP_KEEPINTVL、探测循环次数:TCP_KEEPCNT


在我们的Netty的框架中可以看到针对Socket选项的配置,如使用epoll的IO模型中EpollSocketChannelConfig类中的配置:
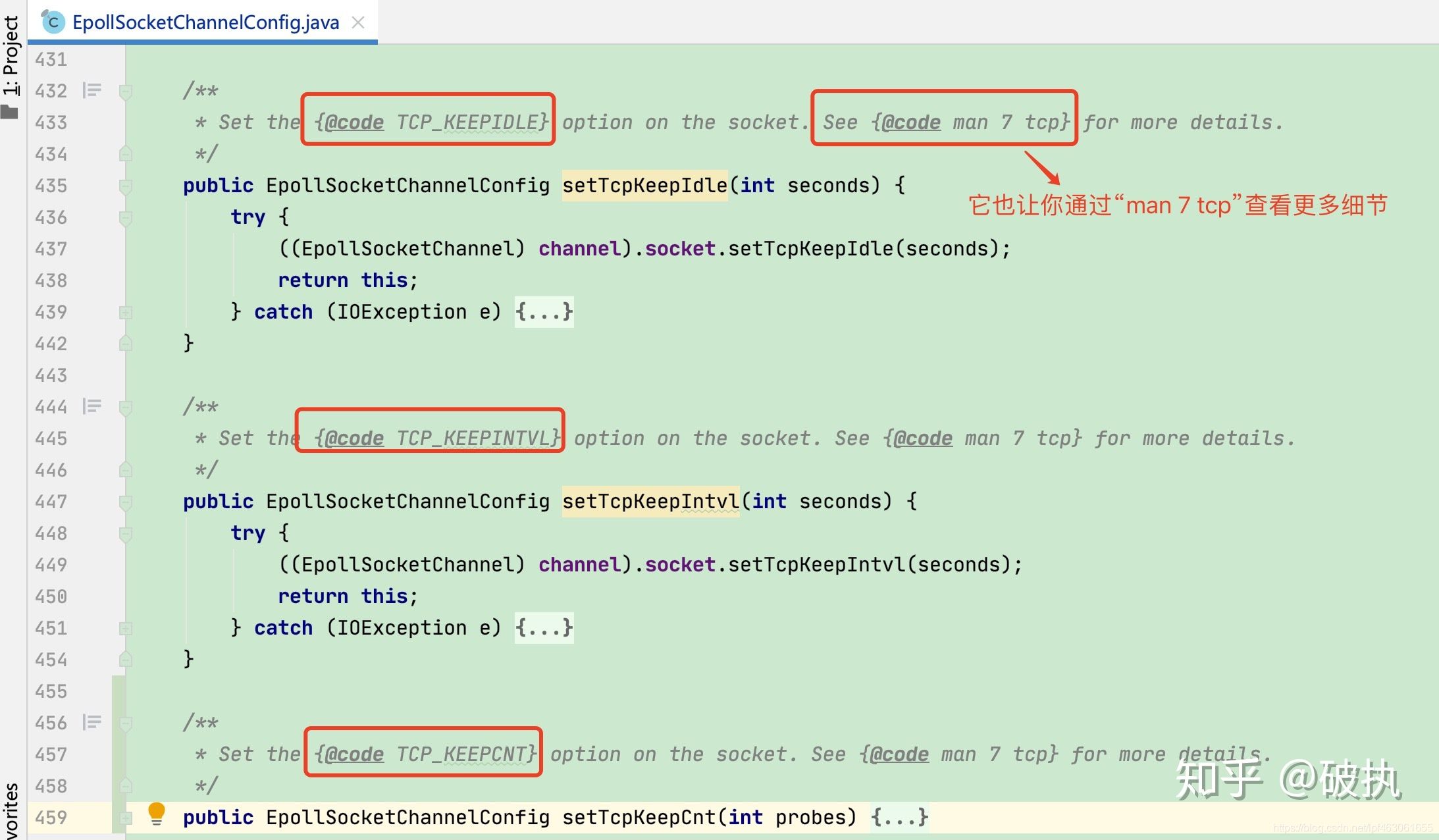
更多细节,等你挖掘。
HTTP keep-alive
在早期的http1.0中,默认就是上述介绍的这种“请求-应答”模式。这种方式频繁的创建连接和销毁连接无疑是有一定性能损耗的。
所以引入了keep-alive机制。http1.0默认是关闭的,通过http请求头设置“connection: keep-alive”进行开启;http1.1中默认开启,通过http请求头设置“connection: close”关闭。
keep-alive机制:若开启后,在一次http请求中,服务器进行响应后,不再直接断开TCP连接,而是将TCP连接维持一段时间。在这段时间内,如果同一客户端再次向服务端发起http请求,便可以复用此TCP连接,向服务端发起请求,并重置timeout时间计数器,在接下来一段时间内还可以继续复用。这样无疑省略了反复创建和销毁TCP连接的损耗。
实验
下面用两组实验证明HTTP keep-alive的存在。
实验工具:Wireshark
客户端IP:..3.52
服务端IP:..17.254
实验一:禁用keep-alive的http请求
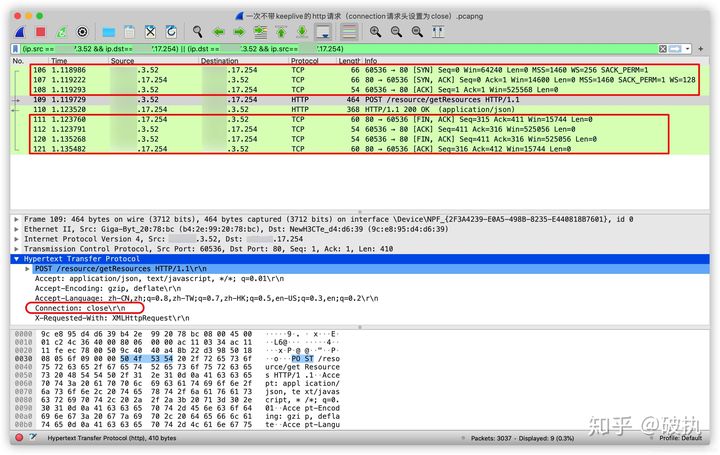
从上图请求列表区中,我们可以发现:
- 106、107、108三个请求是TCP建立连接三次握手的请求
- 109、110两个请求分别是:http的请求报文和http的响应报文
- 111、112、120、121这四个请求是TCP断开连接四次挥手的请求
(由于一台机器上网络请求较多,我加了筛选条件,仅显示客户端和服务端通信的网络请求,所以请求的序号是不连续的)
从上图中间的请求数据解析区,可以确定:此次http请求的请求头中有“Connection: close”,即keep-alive是关闭的。
结论:禁用keep-alive的http请求时,会先建立TCP连接,然后发送报文、响应报文、最后断开TCP连接。
实验二:启用keep-alive的http请求
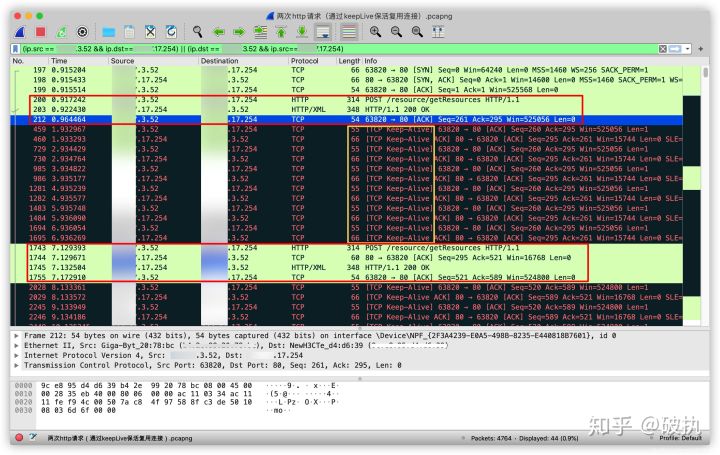
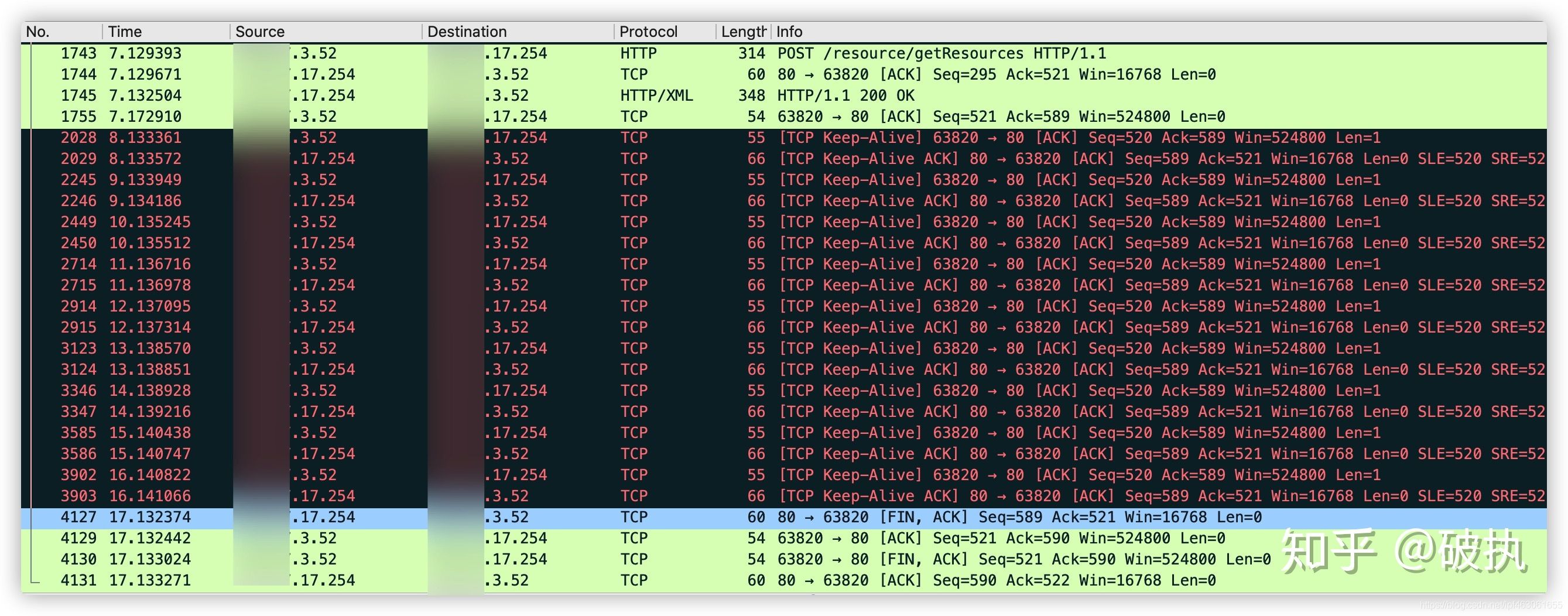
这次实验请求较多,一张图放不下,两张图是连续的,图1的第二块绿色区域和图2的第一块绿色区域是重叠的(注意看第一列的No.编号)
先说下我的操作:
- 开启keep-alive前提下发起第一次http请求
- 7秒左右时,同样的机器同样的http请求,再重新调用一次
我们根据图中抓包,分析下网络请求:
- 197、198、199请求:三次握手建立TCP建立连接
- 200、203请求:http的请求报文和http的响应报文
- 212请求:可以通过Protocol列看到它是一条TCP报文。我的理解是:在keep-alive这种机制下,客户端收到服务端响应报文后,需要告知服务端“已收到”。由于要复用TCP连接,所以会多一层保障机制,类似TCP的握手和挥手
- 459-1965请求(图1中的第一块黑色区域中):6秒内(第二列代表Time),每隔1秒,发生一对TCP请求的来回,用来维护TCP连接的可用性。保证和等待该TCP连接被复用
- 1743、1744、1745、1755请求:其中的1743和1745是我第二次发起http请求的请求报文和响应报文。1744请求是:客户端发起请求时,服务端先回复客户端“已收到,马上处理”。紧接着1745将结果响应给客户端。1755则是客户端收到响应后,回复服务端“已收到响应,多谢”。
- 2028-3903请求:10秒内,每隔1秒,发生一对TCP请求的来回,用来维护TCP连接的可用性。保证和等待该TCP连接被复用
- 4127-4131请求:10秒内我没再发起http请求,四次挥手断开TCP连接。长时间没被复用,也没必要一直维持下去,浪费资源,还可能造成网络拥堵。
注意:10秒无请求,TCP连接在断开,10秒也不是默认的,只是环境的配置。是Httpd守护进程,提供的keep-alive timeout时间设置参数。比如nginx的keepalive_timeout,和Apache的KeepAliveTimeout。
扩展
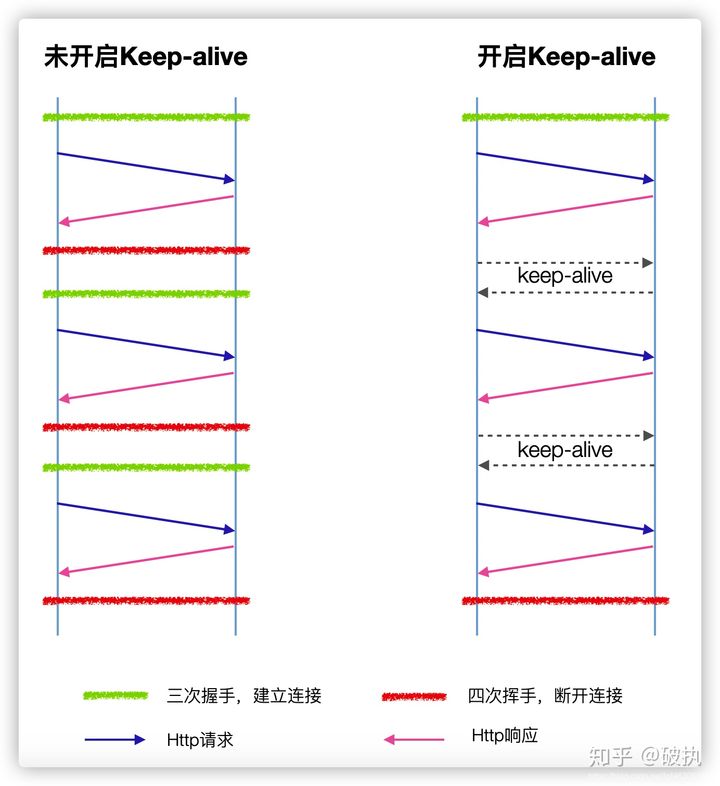
其实对于HTTP keep-alive机制可以总结为上图所示。
启用HTTP keep-Alive的优缺点: 优点:keep-alive机制避免了频繁建立和销毁连接的开销。 同时,减少服务端TIME_WAIT状态的TCP连接的数量(因为由服务端进程主动关闭连接) 缺点:若keep-alive timeout设置的时间较长,长时间的TCP连接维持,会一定程度的浪费系统资源。
总体而言,HTTP keep-Alive的机制还是利大于弊的,只要合理使用、配置合理的timeout参数。
总结
HTTP和TCP的长连接有何区别?HTTP中的keep-alive和TCP中keepalive又有什么区别?
1、TCP连接往往就是我们广义理解上的长连接,因为它具备双端连续收发报文的能力;开启了keep-alive的HTTP连接,也是一种长连接,但是它由于协议本身的限制,服务端无法主动发起应用报文。
2、TCP中的keepalive是用来保鲜、保活的;HTTP中的keep-alive机制主要为了让支撑它的TCP连接活的的更久,所以通常又叫做:HTTP persistent connection(持久连接) 和 HTTP connection reuse(连接重用)。
TCP Keepalive HTTP Keep-Alive 的关系
很多人会把TCP Keepalive 和 HTTP Keep-Alive 这两个概念搞混淆。
这里简单介绍下HTTP Keep-Alive 。
在HTTP/1.0中,默认使用的是短连接。也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。如果客户端浏览器访问的某个HTML或其他类型的 Web页中包含有其他的Web资源,如JavaScript文件、图像文件、CSS文件等;当浏览器每遇到这样一个Web资源,就会建立一个HTTP会话。
但从 HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加上Connection、Keep-Alive字段.如下图所示
HTTP 1.0 和 1.1 在 TCP连接使用方面的差异如下图所示
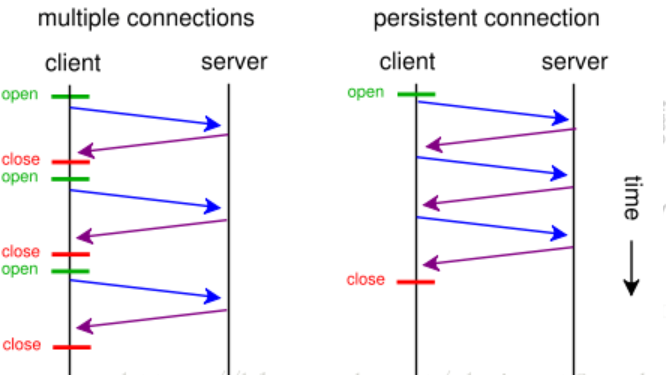
上面说明后,其实就可以知道这两者的区别了。
HTTP协议的Keep-Alive意图在于TCP连接复用,同一个连接上串行方式传递请求-响应数据;TCP的Keepalive机制意图在于探测连接的对端是否存活。
参考资料:
https://blog.csdn.net/chrisnotfound/article/details/80111559
https://zhuanlan.zhihu.com/p/224595048
PS:
HTTP keep-alive章节的实验结果:无论开启keep-alive与否,最终由服务端主动断开TCP连接。
但是我给出问题的答案是:通常由服务端主动关闭连接。没有写“肯定由服务端主动关闭连接”的原因是,我没遇到客户端主动关闭连接的场景,并不代表没有。网络和协议博大精深,等待我们继续去探索。