github链接:https://github.com/DM-Levey/WordCount
项目需求:http://www.cnblogs.com/ningjing-zhiyuan/p/8563562.html
一、项目简介:
这门课的课程叫做软件质量与测试,或者像老师说的叫软件测试与质量,很明显这门课的目的是希望我们提高软件的质量,我同意老师说的,不编程,怎么知道自己的编码可能有多少不良习惯?毕竟重点不在代码,所以我觉得编码阶段5个小时不能再多了,但就像之前说的,如果这门课的重点是测试,那么更多的时间应该用来测试,那么大概再花5个小时测试?不过抱歉,我也有我的事情要干,实在不想拿出10个小时,根据这个作业的性质,我不得不头重脚轻了。于是制定了如下的PSP表格:
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
10 | 5 |
|
· Estimate |
· 估计这个任务需要多少时间 |
10 | 5 |
|
Development |
开发 |
325 | 645 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
15 | 35 |
|
· Design Spec |
· 生成设计文档 |
60 | 20 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
20 | 20 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 | 20 |
|
· Design |
· 具体设计 |
60 | 120 |
|
· Coding |
· 具体编码 |
60 | 200 |
|
· Code Review |
· 代码复审 |
30 | 30 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
60 | 200 |
|
Reporting |
报告 |
50 | 40 |
|
· Test Report |
· 测试报告 |
10 | 20 |
|
· Size Measurement |
· 计算工作量 |
10 | 10 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 | 10 |
|
合计 |
385 | 690 |
二、大体思路
首先看到这个项目,我觉得最陌生的一点是用cmd里面的参数来控制文件的操作,像-o -w这些,以前我只是在window自带的shutdown 里面用过这种命令,但写这种命令确实是第一次,这就是我要首先研究清楚的,之后我在百度中找到了关于main函数中参数argc和argv 的使用方法:
argc:命令行总的参数的个数,即argv中元素的格式。
*argv[ ]:字符串数组,用来存放指向你的字符串参数的指针数组,每一个元素指向一个参数。
argv[0]:指向程序的全路径名。
argv[1]:指向在DOS命令行中执行程序名后的第一个字符串。
argv[2]:指向第二个字符串
然后就可以尝试着看一下具体是什么样的情况:
这样就可以通过argv[i]来读取他的命令,结尾是.c的文件则是要读的文件,.txt的文件就是写出的文件。
大致处理了命令行的问题之后就开始看主要算法,基本功能很简单,只是计数而已,因为我们之前C语言学过这个,最基本的就是数分割符的个数,但这样会出现的问题是
我只要中间多输入几个分隔符,那他就会错乱,这个问题也很好处理,只要从外面进入一个单词里面,就单词数+1,之前还在考虑比如adj@@!这种东西不算单词,是不是遇到
除字母以外的符号我应该把这个从单词数里去掉,但后来发现需求上表示这个也算是单词,那就好办多了,就用正常的计数方法计算就结束了,基本功能到此结束。我用了一
个结构体来表示他需要计数的变量:
typedef struct BasicInfo
{
int nc; //字符数
int nw; //单词数
int nl; //行数
int codeline; //代码行
int spaceline; //空行
int commentline;//注释行
}
具体的数单词字符行数的函数参考了机械工业出版社的C程序设计语言中的CWL函数:
接下来要处理代码行空行和注释行根据/*级各种符号
for(i = 0; (c = *buf++) != '�'&&c>=-1&&c<=255; )
{
++info->nc;
if('
' == c)
++info->nl;
if (' ' == c || '
' == c || ' ' == c || ',' == c || ';' == c || ')' == c || '(' == c || '{' == c || '}' == c)
{
state = OUT;
tmp[i] = '�';
compare(word_list, tmp);
i = 0;
}
if(isalpha(c) && OUT == state)
{
state = IN;
info->nw+=1;
}
}
/*最后一行没有'
'*/
++info->nl;
这些不同的组合,列出一些状态
并且用strtok函数将源文件根据
来分成不同的字符数组,然后一行行处理就能得到结果。但最后测试出来是错误的结果,后来经过百度发现strtok这个函数在处理两个连续的‘
’的时候会直接跳过检测,
导致空行减少的情况,因此需要在判断一下是否用有两个连续的‘
’如果出现一次则额外的空行+1,等全部处理完之后再把额外的空行加上去
-s的功能确实一开始不知道怎么处理,但是后来发现*.c这个名称在CMD中能直接解析出来,所以这个功能也算完成了。
三、代码分析
int space_state = FALSE;
while((c = *p1++) != '�')
{
if('
' == c && !extra_state)
{
extra_state =TRUE;
continue;
}
if('
' == c && extra_state)
{
extra_space ++;
}
if(c != '
')
extra_state = FALSE;
}
在判断额外的空行的时候也使用了有限状态机,和判断注释行的时候一样,不过注释行情况太多,而且时间关系我没有去优化他们的结构,只是把一个个条件堆起来,所以在这里,就拿这个举例子,一开始
默认没有到extra的情况,当遇到一个换行符的时候就进入第二种状态,即extra_state为真时,如果直接遇到第二个换行符,额外的空行就会再加1,当他遇到不是换行符的字符时,extra_state回到最初
的状态。
四、测试用例
在这个模块里,根据统计单词数和停用词表,行数和特殊行的关系,是否搜索,是否输出 做出了以下10个测试用例
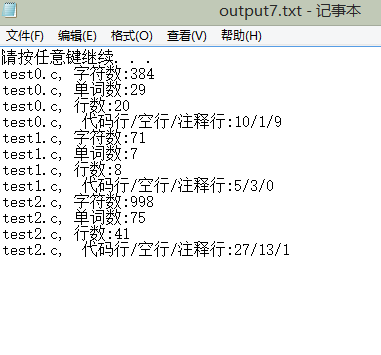
start wc.exe wc.exe -w test0.c -o output0.txt start wc.exe wc.exe -l test0.c -o output1.txt start wc.exe wc.exe -l -a test0.c -o output2.txt start wc.exe wc.exe -c test0.c -o output3.txt start wc.exe wc.exe -w -c test0.c -o output4.txt start wc.exe wc.exe -w -c -l test0.c -o output5.txt start wc.exe wc.exe -w -c -l -a test0.c -o output6.txt start wc.exe wc.exe -s -w -o -c -l -a *.c -o output7.txt start wc.exe wc.exe -w -c -l -a test0.c -e stop.txt start wc.exe wc.exe -w test0.c -e stop.txt
这是测试脚本中的用例,只要打开测试脚本的批处理程序就会执行者10条代码。
这里放出output7.txt 的结果
五、总结
这次的作业让我更加深入的了解了cmd和函数之间的关系,但是花的时间太长了,给的时间又太短了,所以很多细节都没有处理好。