2.3.1测试
20191331 lyx
测试要求
0 推荐在OpenEuler系统中实现
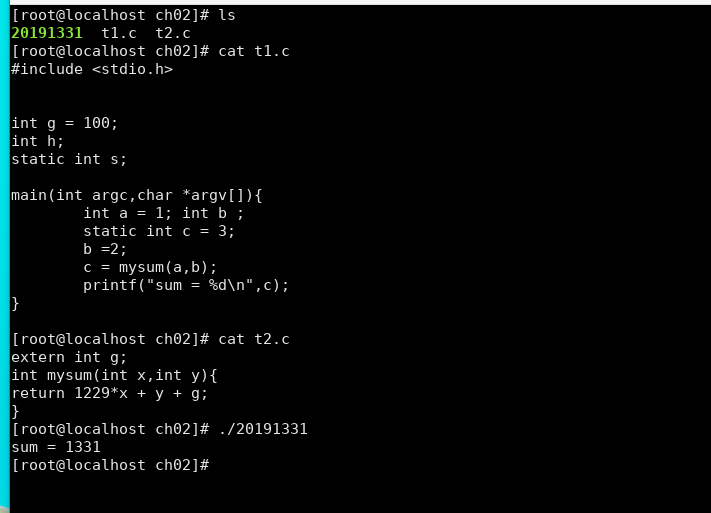
1 编辑并运行2.3.1中的代码,要求在不修改t2.c 和 t1.c中main函数中的代码的情况下,程序运行结果是你的后四位学号。提交代码和运行结果截图。
2 网上学习objdump命令,提交不少于5篇博客链接和微信读书上的图书链接,并给出你认为最好的讲解资源的链接或图书名及章节
3 用objdump分析第1步中的可执行文件和目标文件,提交你的分析截图以及如何和教材讲解内容对应的,比如obj文件的文件头,代码段,数据段等,可执行文件如何链接mysum的。
0.实验准备
- 实验环境
本次实验使用 OpenEuler 20.03LTS操作系统。
1.编辑并运行
- 实验代码
********************t1.c*******************
#include <stdio.h>
int g = 100;
int h;
static int s;
main(int argc,char *argv[]){
int a = 1; int b ;
static int c = 3;
b =2;
c = mysum(a,b);
printf("sum = %d
",c);
}
********************t2.c*******************
extern int g;
int mysum(int x,int y){
return 1229*x + y + g;
}
实验截图:
2.objdump学习
objdump命令是用查看目标文件或者可执行的目标文件的构成的gcc工具。
--archive-headers
-a
显示档案库的成员信息,类似ls -l将lib*.a的信息列出。
-b bfdname
--target=bfdname
指定目标码格式。这不是必须的,objdump能自动识别许多格式,比如:
objdump -b oasys -m vax -h fu.o
显示fu.o的头部摘要信息,明确指出该文件是Vax系统下用Oasys编译器生成的目标文件。objdump -i将给出这里可以指定的目标码格式列表。
-C
--demangle
将底层的符号名解码成用户级名字,除了去掉所开头的下划线之外,还使得C++函数名以可理解的方式显示出来。
--debugging
-g
显示调试信息。企图解析保存在文件中的调试信息并以C语言的语法显示出来。仅仅支持某些类型的调试信息。有些其他的格式被readelf -w支持。
-e
--debugging-tags
类似-g选项,但是生成的信息是和ctags工具相兼容的格式。
--disassemble
-d
从objfile中反汇编那些特定指令机器码的section。
-D
--disassemble-all
与 -d 类似,但反汇编所有section.
--prefix-addresses
反汇编的时候,显示每一行的完整地址。这是一种比较老的反汇编格式。
-EB
-EL
--endian={big|little}
指定目标文件的小端。这个项将影响反汇编出来的指令。在反汇编的文件没描述小端信息的时候用。例如S-records.
-f
--file-headers
显示objfile中每个文件的整体头部摘要信息。
-h
--section-headers
--headers
显示目标文件各个section的头部摘要信息。
-H
--help
简短的帮助信息。
-i
--info
显示对于 -b 或者 -m 选项可用的架构和目标格式列表。
-j name
--section=name
仅仅显示指定名称为name的section的信息
-l
--line-numbers
用文件名和行号标注相应的目标代码,仅仅和-d、-D或者-r一起使用使用-ld和使用-d的区别不是很大,在源码级调试的时候有用,要求编译时使用了-g之类的调试编译选项。
-m machine
--architecture=machine
指定反汇编目标文件时使用的架构,当待反汇编文件本身没描述架构信息的时候(比如S-records),这个选项很有用。可以用-i选项列出这里能够指定的架构.
--reloc
-r
显示文件的重定位入口。如果和-d或者-D一起使用,重定位部分以反汇编后的格式显示出来。
--dynamic-reloc
-R
显示文件的动态重定位入口,仅仅对于动态目标文件意义,比如某些共享库。
-s
--full-contents
显示指定section的完整内容。默认所有的非空section都会被显示。
-S
--source
尽可能反汇编出源代码,尤其当编译的时候指定了-g这种调试参数时,效果比较明显。隐含了-d参数。
--show-raw-insn
反汇编的时候,显示每条汇编指令对应的机器码,如不指定--prefix-addresses,这将是缺省选项。
--no-show-raw-insn
反汇编时,不显示汇编指令的机器码,如不指定--prefix-addresses,这将是缺省选项。
--start-address=address
从指定地址开始显示数据,该选项影响-d、-r和-s选项的输出。
--stop-address=address
显示数据直到指定地址为止,该项影响-d、-r和-s选项的输出。
-t
--syms
显示文件的符号表入口。类似于nm -s提供的信息
-T
--dynamic-syms
显示文件的动态符号表入口,仅仅对动态目标文件意义,比如某些共享库。它显示的信息类似于 nm -D|--dynamic 显示的信息。
-V
--version
版本信息
--all-headers
-x
显示所可用的头信息,包括符号表、重定位入口。-x 等价于-a -f -h -r -t 同时指定。
-z
--disassemble-zeroes
一般反汇编输出将省略大块的零,该选项使得这些零块也被反汇编。
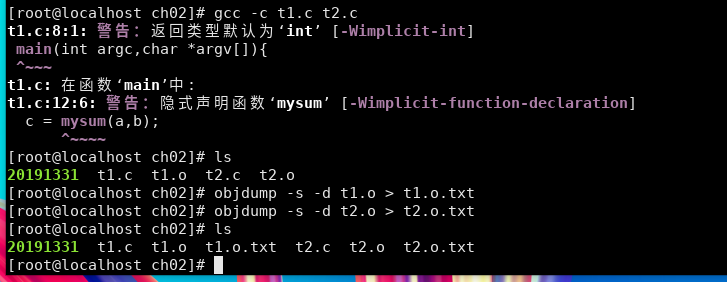
对目标文件.o的反汇编:
gcc -c -o main.o main.c
objdump -s -d main.o > main.o.txt
对可执行文件.exe或.elf的反汇编:
gcc -o main main.c
objdump -s -d main > main.txt
我认为学习objdump最好的两篇博客:
- Linux下C程序的反汇编【转】 https://www.cnblogs.com/sky-heaven/p/8547950.html
- objdump反汇编代码阅读 http://cxd2014.github.io/2019/12/12/objdump/
知识补充
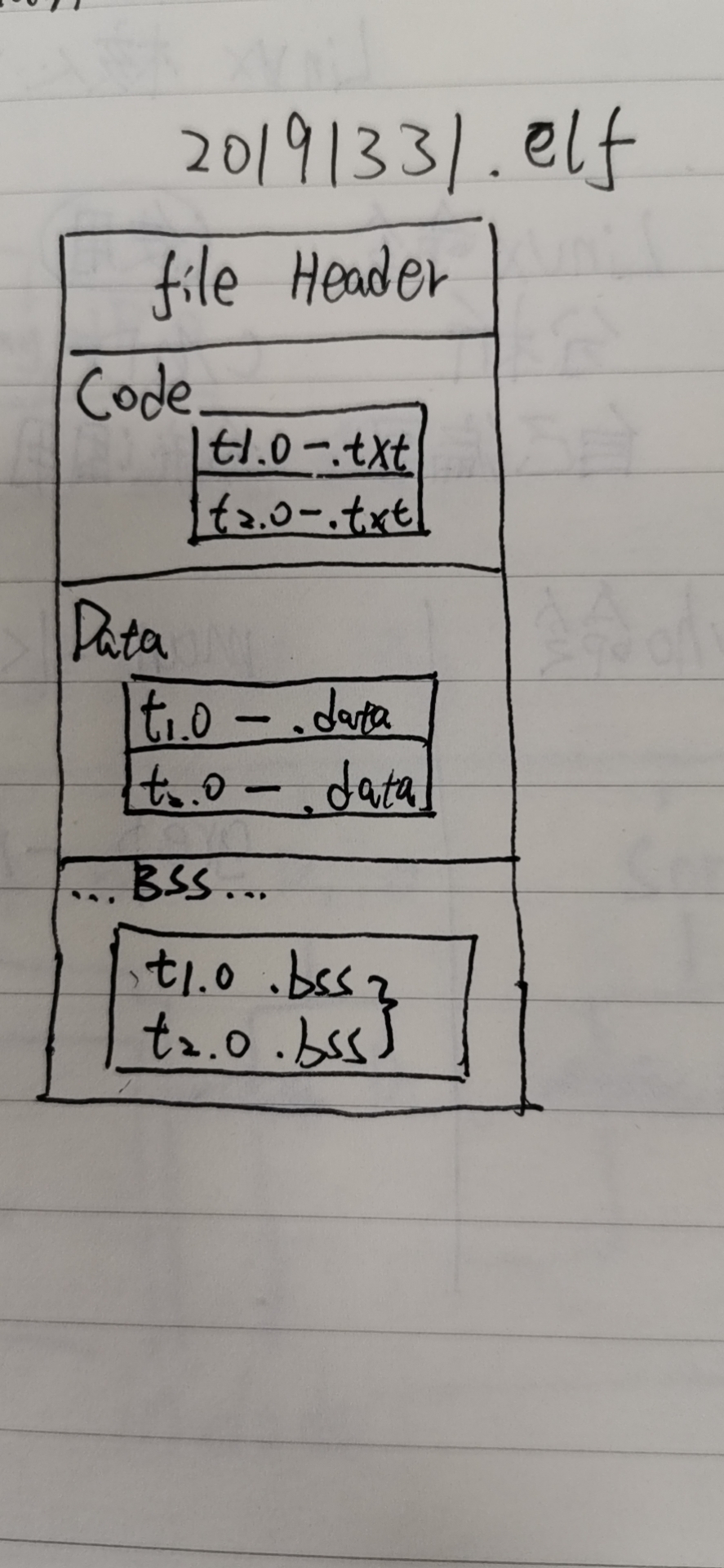
每个.0文件都包含:
- 一个文件头,包含代码段、数据段和BSS段的大小
- 一个代码段,包含机器指令
- 一个数据段,包含初始化全局变量和初始化静态局部变量
- 一个BSS段,包含未初始化全局变量和未初始化静态局部变量
- 代码中的指针以及数据和BSS中的偏移量的重定位信息
- 一个符号表,包含非静态全局变量、函数名称及其属性
可执行文件包含以下部分:
- 文件头:文件头包含可执行文件的加载信息和大小,其中
- tsize=代码段大小
- dsize=包含初始化全局变量和初始化静态局部变量的数据段大小
- bsize=包含未初始化全局变量和未初始化静态局部变量的bss段大小
- total_size=加载的可执行文件的总大小
- 代码段:也称为正文段,其包含程序的可执行代码。代码段从标准C启动代码zrt0.o开始,该代码调用main()函数。
- 数据段:数据段包含初始化全局变量和初始化静态数据
- 符号表:可选,仅位运行调试所需。
参考资料:
- 怎么将二进制代码转换为中间代码(IR) https://www.zhihu.com/question/36734147/answer/80345324
- 为何.o文件Objdump反汇编看不到函数名,二进制反汇编能看到? https://bbs.csdn.net/topics/392027741
- objdump反汇编代码阅读 http://cxd2014.github.io/2019/12/12/objdump/
- Linux下C程序的反汇编【转】 https://www.cnblogs.com/sky-heaven/p/8547950.html
- 反汇编工具 objdump的使用简介 https://www.cnblogs.com/yygsj/p/5023789.html
- objdump命令 https://man.linuxde.net/objdump
- objdump命令的使用 https://blog.csdn.net/beyondioi/article/details/7796414
- objdump(Linux)反汇编命令使用指南 https://zhuanlan.zhihu.com/p/335550245
3.使用objdump分析可执行文件和目标文件
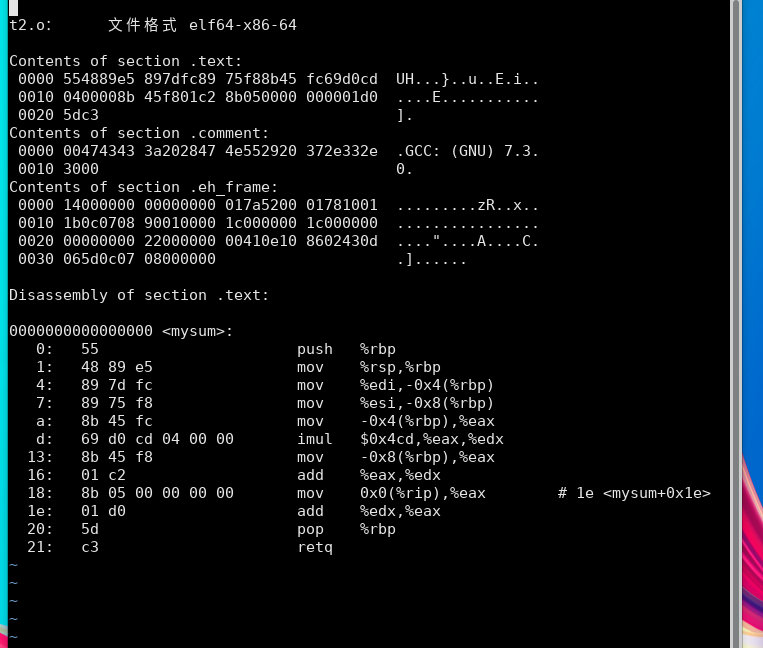
使用objdump分析目标文件:
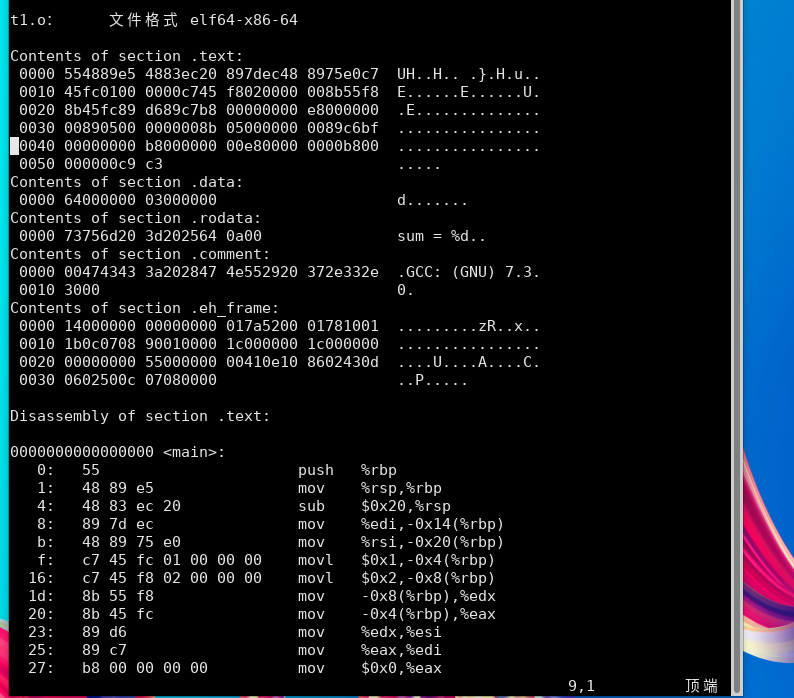
使用objdump分析可执行文件:
由于我在t1.c中引用了stdio.h标准库 这就导致我的可执行程序反汇编后会包含所调用的stdio.h库中的内容,使反编译文件分析难度加大。
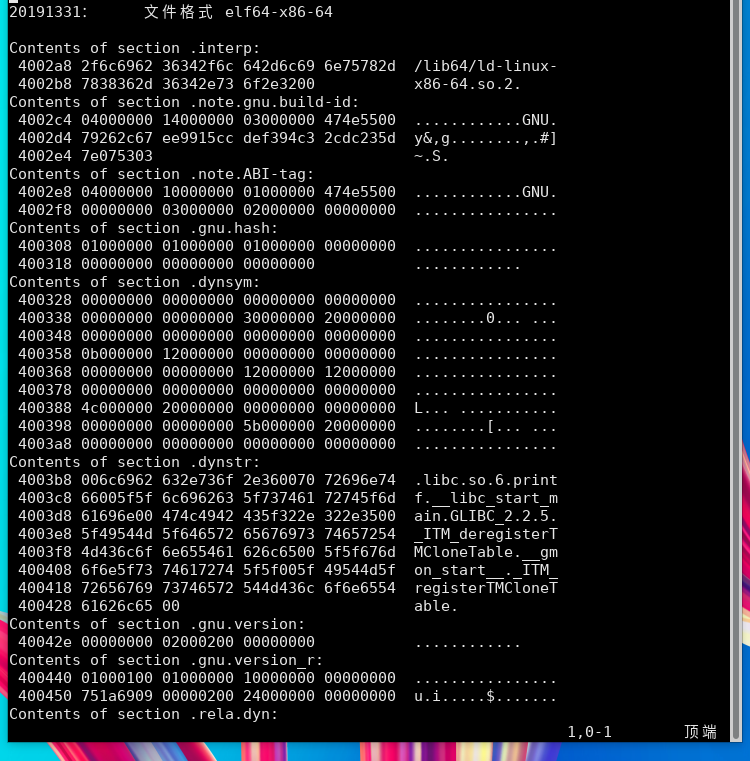
数据段:初始化的全局变量和初始化的静态局部变量
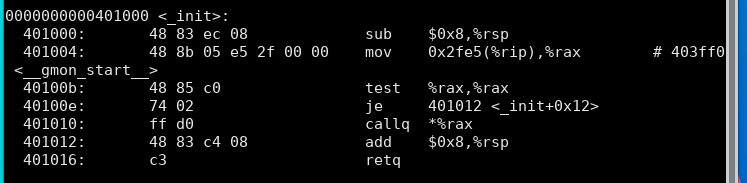
main函数:
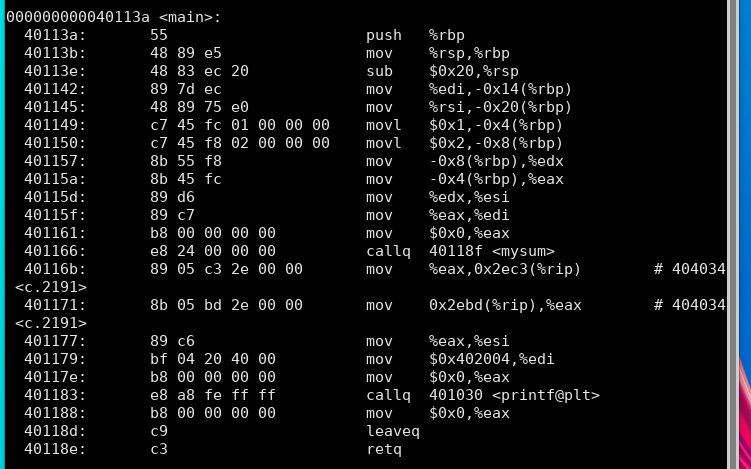
mysum函数引用:
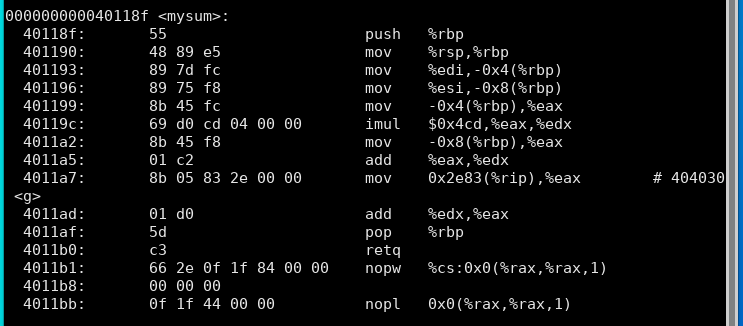
显示所可用的头信息,包括符号表、重定位入口:
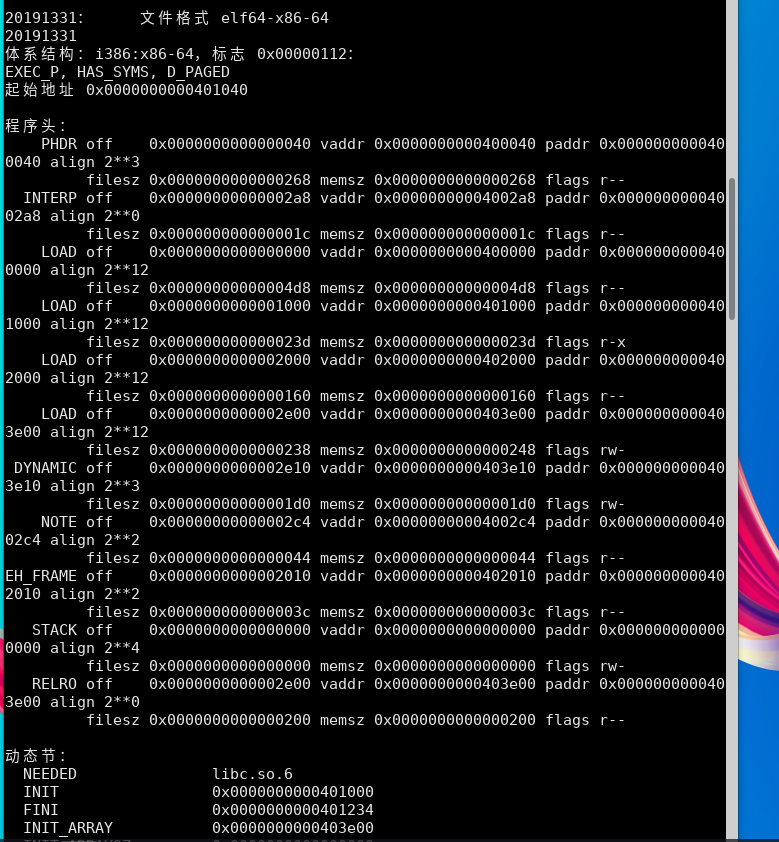
可执行程序和目标文件的联系: