语音唤醒
定义
语音唤醒在学术上被称为keyword spotting(简称KWS),给它做了一个定义:在连续语流中实时检测出说话人特定片段。
这里要注意,检测的“实时性”是一个关键点,语音唤醒的目的就是将设备从休眠状态激活至运行状态,所以唤醒词说出之后,能立刻被检测出来,用户的体验才会更好。
那么,该怎样评价语音唤醒的效果呢?通行的指标有四个方面,即唤醒率、误唤醒、响应时间和功耗水平:
➤唤醒率,指用户交互的成功率,专业术语为召回率,即recall。
➤误唤醒,用户未进行交互而设备被唤醒的概率,一般按天计算,如最多一天一次。
➤响应时间,指从用户说完唤醒词后,到设备给出反馈的时间差。
➤功耗水平,即唤醒系统的耗电情况。很多智能设备是通过电池供电,需要满足长时续航,对功耗水平就比较在意。
语音唤醒的技术路线
经过长时间的发展,语音唤醒的技术路线大致可归纳为三代,特点如下:
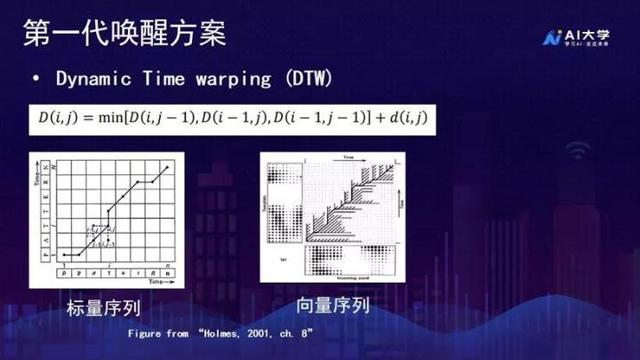
第一代:基于模板匹配的KWS
训练和测试的步骤比较简单,训练就是依据注册语音或者说模板语音进行特征提取,构建模板。测试时,通过特征提取生成特征序列,计算测试的特征序列和模板序列的距离,基于此判断是否唤醒。
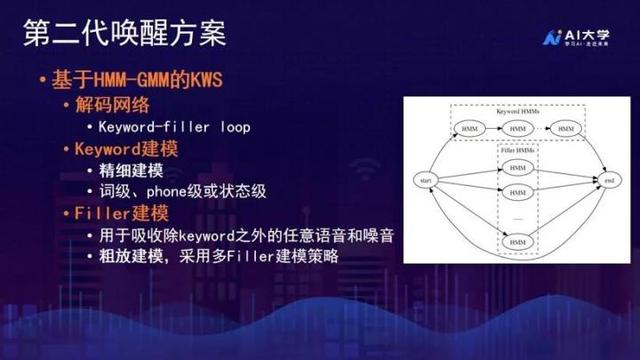
第二代:基于HMM-GMM的KWS
将唤醒任务转换为两类的识别任务,识别结果为keyword和non-keyword。
第三代:基于神经网络的方案
神经网络方案又可细分为几类,第一类是基于HMM的KWS,同第二代唤醒方案不同之处在于,声学模型建模从GMM转换为神经网络模型。 第二类融入神经网络的模板匹配,采用神经网络作为特征提取器。第三类是基于端到端的方案,输入语音,输出为各唤醒的概率,一个模型解决。

语音唤醒的难点
语音唤醒的难点,主要是低功耗要求和高效果需求之间的矛盾。
一方面,目前很多智能设备采用的都是低端芯片,同时采用电池供电,这就要求唤醒所消耗的能源要尽可能的少。
另一方面,用户对体验效果的追求越来越高。目前语音唤醒主要应用于C端,用户群体广泛,且要进行大量远场交互,对唤醒能力提出了很高要求。
要解决两者之间的矛盾,对于低功耗需求,我们采用模型深度压缩策略,减少模型大小并保证效果下降幅度可控;而对于高效果需求,一般是通过模型闭环优化来实现。先提供一个效果可用的启动模型,随着用户的使用,进行闭环迭代更新,整个过程完成自动化,无需人工参与。
语音唤醒的典型应用
语音唤醒的应用领域十分广泛,主要是C端产品,比如机器人、音箱、汽车等。比较有代表性的应用模式有如下几种:
➤传统语音交互:先唤醒设备,等设备反馈后(提示音或亮灯),用户认为设备被唤醒了,再发出语音控制命令,缺点在于交互时间长。
➤One-shot:直接将唤醒词和工作命令一同说出,如“叮咚叮咚,我想听周杰伦的歌”,客户端会在唤醒后直接启动识别以及语义理解等服务,缩短交互时间。
➤Zero-shot:将常用用户指定设置为唤醒词,达到用户无感知唤醒,例如直接对车机说“导航到科大讯飞”,这里将一些高频前缀的说法设置成唤醒词。