0.前言
写这篇随笔的原因呢,还得感谢此次结对编程与南通大学鞠老师的合作,因时间较短开发出来的小程序在性能上并没有足够多的考虑。其实我一直以来都有一种习惯,就是对于一些细枝末节的程序,并不太愿意花时间去考虑效率。更多地时间愿意花在算法的调优上,而本次的讨论,也确实影响了我,也是促动我这次认真分析一些小地方的效率情况。
github地址 : https://github.com/yuan574954352/WordCountByRegular
1.设计实验
在之前的实现之中的主要逻辑如下,
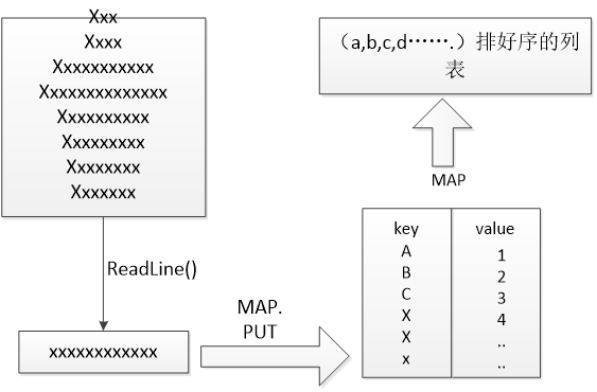
其中讨论的重点是继Readline()、Split()之后,对于单词的匹配处理。因此我对于其他程序依旧不改变,只改变dealline()中的代码,采用典型的控制变量思想。
1.1 控制变量
【原方法】
String subString = line.substring(first, end + 1);
int lengthSub = subString.length()>4? 4:subString.length();
for (int j=0 ;j<lengthSub;j++)
{
if(isNumber(subString.charAt(j))){
isSubHavaNum = true;
}
}
其中SubString是截取的单词,原方法对于单词的判断是基于单词前四个字母中是否含有数字。
【正则表达式方法】
String subString = line.substring(first, end + 1);
boolean idWord = subString.matches(Reg);
if(idWord) {
其中Reg为正则表达式。利用matches方法判断是否继续操作。
2.实验测试
测试文件为一篇英文文献:Tack: Learning Towards Contextual and Ephemeral Indoor Localization With Crowdsourcing
为了尽量避免因偶然误差带来的影响,我对每个方法均使用JProfiler分析3次,得出平均值。
2.1从运算正确结果分析:经测试两种方法得出结果一样,且均为下图:
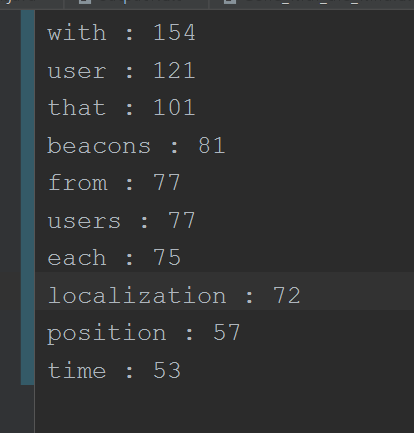
感兴趣读者可自行测试,在此不再赘述。
2.2从性能分析
|
原方法 |
||
|
|
dealline运行总时间 |
程序运行总时间 |
|
第一次 |
40,371 |
64,310 |
|
第二次 |
28,669 |
43,391 |
|
第三次 |
35,067 |
45,114 |
|
正则表达式方法 |
||
|
|
dealline运行总时间 |
程序运行总时间 |
|
第一次 |
54,980 |
68,832 |
|
第二次 |
49,169 |
63,095 |
|
第三次 |
35,058 |
60,150 |
结论一:
我们定义 T(dealline)/T(Main) = 行处理率.
则在原方法中:行处理率1 = 62.77 %,行处理率2 = 66.07%,行处理率3 = 77.72%
均行处理率 = 67%
在正则方法中: 行处理率1 = 79.87 %,行处理率2 =77.93%,行处理率3 = 58.28%
均行处理率 = 72%
从以上分析,我们很明显的看到,正则表达式的方案并不会比我们原来使用的方案提高效率!反而使用正则表达式程序会花费大量时间在 java.lang.String.matches 方法上。
结论二:
事实上,正则表达式方案反而会使方案降低效率,其中平均降低效率为 0.015s/1.4万字母。而这样的效率降低在现实中是完全可以接受的。
换句话说就是 你有一个 100万字母的英文文本,词频统计效率才会下降1s,而且考虑到本人计算机本身计算效率不高,这样的效率改进是没多大意义的!
原因分析:
因为在本次需求中,不超过4个字母以上的单词不计为单词,例如 It Was for you 等等。在原方法中,是先判断长度是否大于3,才继续操作。而在
正则表达式中并没有判断。而是直接匹配。这也是操作效率低下的一个方面。
事实上,正则表达式的可读性和可扩展性更强,也就是说如果下次一个需求变动,这样其他修改者不必花大量时间来思考逻辑,因此我个人偏向正则表达式!
写于 2018/7/13 地大工程研究中心
其他:
本人是一个南方人,从小在湖南南部和广州两地长大,这是我第一次前去北京,感谢北航计算机学院和邹欣老师提供的机会,北京给我感觉简直太完美了,尤其是北京的学术学习氛围,北京的城市规划简直棒棒哒。不过,说实在的北京的伙食,我是真的吃不惯。我已经连续一星期没碰辣椒了~~~