String类构造方法的部分源码
package java.lang; import java.io.ObjectStreamField; import java.io.UnsupportedEncodingException; import java.util.ArrayList; import java.util.Arrays; import java.util.Formatter; import java.util.Locale; import java.util.Objects; import java.util.StringJoiner; import java.util.regex.Matcher; import java.util.regex.Pattern; import java.util.regex.PatternSyntaxException; /** * {@code String} 类表示字符串。所有java程序中的字符串,如{@code "abc"},是作为该类的实例实现。 * <p>字符串是常量,它们的值在它们之后不能改变。创建。字符串缓冲区支持可变字符串。因为字符串对象是不可变的,所以它们可以被共享。例如: * <blockquote><pre> * String str = "abc"; * </pre></blockquote><p> * 相当于: * <blockquote><pre> * char data[] = {'a', 'b', 'c'}; * String str = new String(data); * </pre></blockquote><p> * 下面是一些字符串如何使用的例子: * <blockquote><pre> * System.out.println("abc"); * String cde = "cde"; * System.out.println("abc" + cde); * String c = "abc".substring(2,3); * String d = cde.substring(1, 2); * </pre></blockquote> * <p> * String 类包括的方法可用于检查序列的单个字符、比较字符串、搜索字符串、提取子字符串、创建字符串副本并将所有字符全部转换为大写或小写。 * 大小写映射基于 Character 类指定的 Unicode 标准版。 * <p> * Java 语言提供对字符串串联符号("+")以及将其他对象转换为字符串的特殊支持。字符串串联是通过 StringBuilder(或 StringBuffer)类及其 append 方法实现的。 * 字符串转换是通过 toString 方法实现的,该方法由 Object 类定义,并可被 Java 中的所有类继承。有关字符串串联和转换的更多信息,请参阅 Gosling、Joy和 * Steele合著的 The Java Language Specification。 * <i>java语言规范</i>. * * <p> 除非另行说明,否则将 null 参数传递给此类中的构造方法或方法将抛出 NullPointerException。 * * <p>String 表示一个 UTF-16 格式的字符串,其中的增补字符 由代理项对 表示(有关详细信息,请参阅 Character 类中的 Unicode 字符表示形式)。 * 索引值是指 char 代码单元,因此增补字符在 String 中占用两个位置。 * <p>String 类提供处理 Unicode 代码点(即字符)和 Unicode 代码单元(即 char 值)的方法。 * * @author Lee Boynton * @author Arthur van Hoff * @author Martin Buchholz * @author Ulf Zibis * @see java.lang.Object#toString() * @see java.lang.StringBuffer * @see java.lang.StringBuilder * @see java.nio.charset.Charset * @since JDK1.0 */ public final class String implements java.io.Serializable, Comparable<String>, CharSequence { /** 该值用于字符存储。 */ private final char value[]; /** 字符串缓存的哈希代码 */ private int hash; // Default to 0 private static final long serialVersionUID = -6849794470754667710L; private static final ObjectStreamField[] serialPersistentFields = new ObjectStreamField[0]; /** * 初始化一个新创建的 String 对象,使其表示一个与参数相同的字符序列;换句话说,新创建的字符串是该参数字符串的副本。由于 String 是不可变的, * 所以无需使用此构造方法,除非需要 original 的显式副本。 * * @param original 一个 String。 */ public String(String original) { this.value = original.value; this.hash = original.hash; } /** * 分配一个新的 String,使其表示字符数组参数中当前包含的字符序列。该字符数组的内容已被复制;后续对字符数组的修改不会影响新创建的字符串。 * @param value 字符串的初始值 */ public String(char value[]) { this.value = Arrays.copyOf(value, value.length); } /** * 分配一个新的 String,它包含取自字符数组参数一个子数组的字符。 offset 参数是子数组第一个字符的索引, count 参数指定子数组的长度。该子数组的内容已 * 被复制;后续对字符数组的修改不会影响新创建的字符串。 * * @param value 作为字符源的数组。 * * @param offset 初始偏移量。 * * @param count 长度。 * * @throws IndexOutOfBoundsException 如果 offset 和 count 参数索引字符超出 value 数组的范围。 */ public String(char value[], int offset, int count) { if (offset < 0) { throw new StringIndexOutOfBoundsException(offset); } if (count <= 0) { if (count < 0) { throw new StringIndexOutOfBoundsException(count); } if (offset <= value.length) { this.value = "".value; return; } } // offset 或 count 也许 -1>>>1. if (offset > value.length - count) { throw new StringIndexOutOfBoundsException(offset + count); } this.value = Arrays.copyOfRange(value, offset, offset+count); } private static void checkBounds(byte[] bytes, int offset, int length) { if (length < 0) throw new StringIndexOutOfBoundsException(length); if (offset < 0) throw new StringIndexOutOfBoundsException(offset); if (offset > bytes.length - length) throw new StringIndexOutOfBoundsException(offset + length); } /** * 通过使用指定的字符集解码指定的 byte 子数组,构造一个新的 String。新 String 的长度是一个字符集函数,因此可能不等于子数组的长度。 * * * <p> 当给定 byte 在给定字符集中无效的情况下,此构造方法的行为没有指定。如果需要对解码过程进行更多控制,则应该使用 CharsetDecoder 类。 * * @param bytes 要解码为字符的 byte * * @param offset 要解码的第一个 byte 的索引 * * @param length 要解码的 byte 数 * @param charsetName 受支持 charset 的名称 * * @throws 如果指定的字符集不受支持 * * @throws IndexOutOfBoundsException 如果 offset 和 length 参数索引字符超出 bytes 数组的范围 * * @since JDK1.1 */ public String(byte bytes[], int offset, int length, String charsetName) throws UnsupportedEncodingException { if (charsetName == null) throw new NullPointerException("charsetName"); checkBounds(bytes, offset, length); this.value = StringCoding.decode(charsetName, bytes, offset, length); } /** * 通过使用指定的 charset 解码指定的 byte 数组,构造一个新的 String。新 String 的长度是字符集的函数,因此可能不等于 byte 数组的长度。 * * <p>当给定 byte 在给定字符集中无效的情况下,此构造方法的行为没有指定。如果需要对解码过程进行更多控制,则应该使用 CharsetDecoder 类。 * * @param bytes 要解码为字符的 byte * * @param charsetName 受支持的 charset 的名称 * * @throws UnsupportedEncodingException 如果指定字符集不受支持 * * @since JDK1.1 */ public String(byte bytes[], String charsetName) throws UnsupportedEncodingException { this(bytes, 0, bytes.length, charsetName); } /** * 通过使用平台的默认字符集解码指定的 byte 子数组,构造一个新的 String。新 String 的长度是字符集的函数,因此可能不等于该子数组的长度。 * * <p>当给定 byte 在给定字符集中无效的情况下,此构造方法的行为没有指定。如果需要对解码过程进行更多控制,则应该使用 CharsetDecoder 类。 * * @param bytes 要解码为字符的 byte * * @param offset 要解码的第一个 byte 的索引 * * @param length 要解码的 byte 数 * * @throws IndexOutOfBoundsException 如果 offset 和 length 参数索引字符超出 bytes 数组的范围 * * @since JDK1.1 */ public String(byte bytes[], int offset, int length) { checkBounds(bytes, offset, length); this.value = StringCoding.decode(bytes, offset, length); } /** * 通过使用平台的默认字符集解码指定的 byte 数组,构造一个新的 String。新 String 的长度是字符集的函数,因此可能不等于 byte 数组的长度。 * * <p> 当给定 byte 在给定字符集中无效的情况下,此构造方法的行为没有指定。如果需要对解码过程进行更多控制,则应该使用 CharsetDecoder 类。 * * @param bytes 要解码为字符的 byte * * @since JDK1.1 */ public String(byte bytes[]) { this(bytes, 0, bytes.length); } /** * 分配一个新的字符串,它包含字符串缓冲区参数中当前包含的字符序列。该字符串缓冲区的内容已被复制,后续对它的修改不会影响新创建的字符串。 * * @param buffer 一个 StringBuffer */ public String(StringBuffer buffer) { synchronized(buffer) { this.value = Arrays.copyOf(buffer.getValue(), buffer.length()); } } /** * 分配一个新的字符串,它包含字符串生成器参数中当前包含的字符序列。该字符串生成器的内容已被复制,后续对它的修改不会影响新创建的字符串。 * * <p>提供此构造方法是为了简化到 StringBuilder 的迁移。通过 toString 方法从字符串生成器中获取字符串可能运行的更快,因此通常作为首选。 * * @param builder 一个 StringBuilder * * @since 1.5 */ public String(StringBuilder builder) { this.value = Arrays.copyOf(builder.getValue(), builder.length()); } }
源码理解
String类位于java.lang包下实现了Comparable和Serializable接口,因此可以序列化,可以进行比较,并且String类是被final修饰,因此不能被继承,并且该类中的成员默认final方法。String类中包含一个不可变的char数组用来存放字符串,一个int型的变量hash用来存放计算后的哈希值,因此String类本质是char数组。使用 byte[] 构造 String时可以指定解码使用的字符集,默认是ISO-8859-1 编码格式进行编码操作。
字符集测试案例
package ecut.strings; import java.nio.charset.Charset; import java.util.Iterator; import java.util.Map; import java.util.Set; /** * Java支持的字符集。 * 常用字符编码: * UTF-8 ( Unicode 的子集 ) * GBK ( GB2312 / GB18030 ) 中国大陆采用的简体汉字编码 * Big5 繁体中文 (正体中文) * ISO-8859-1 */ public class CharsetTest { public static void main(String[] args) { //构造从规范 charset 名称到 charset 对象的有序映射。 Map<String,Charset> map = Charset.availableCharsets(); // 迭代 map 返回此映射中包含的键的 Set 视图。 Set<String> keys = map.keySet(); // foreach 循环中 可以处理的 对象有 数组 或 java.lang.Iterable 接口的实现类 for( String key : keys ) { //返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。 Charset value = map.get( key ); System.out.println( key + " : " + value ); } //返回在此 set 中的元素上进行迭代的迭代器。 Iterator<String> it = keys.iterator(); while( it.hasNext() ) { String key = it.next(); Charset value = map.get( key ); // 根据 key 取出 value System.out.println( key + " : " + value ); } } }
运行结果如下:
Big5 : Big5 Big5-HKSCS : Big5-HKSCS CESU-8 : CESU-8
......
x-windows-949 : x-windows-949 x-windows-950 : x-windows-950 x-windows-iso2022jp : x-windows-iso2022jp
String类创建方式
1、双引号型
2、new型
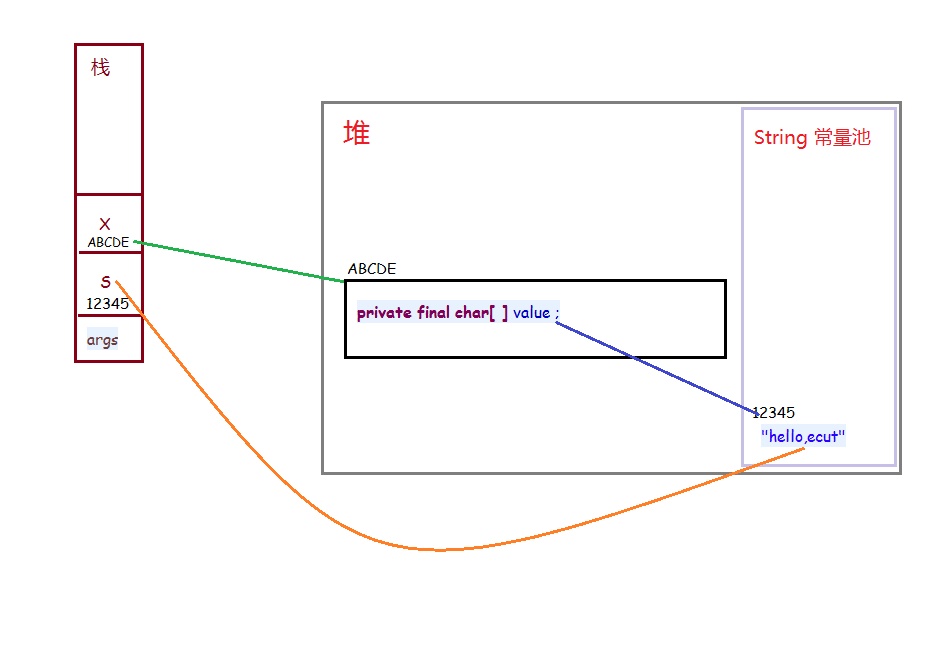
package ecut.strings; public class StringTest1 { public static void main(String[] args) { // 所有的 "" 包起来的 字符串 字面值一律放在 字符串常量池中 //去字符串常量池池寻找相同内容的字符串,如果存在就直接拿出来应用,如果不存在则创建一个新的字符串放在常量池中。 String s = "hello,ecut" ; System.out.println( System.identityHashCode( s ) ); //通过 new关键字创建 String 对象,每次调用都会创建一个新的对象。 String x = new String( "hello,ecut" ); System.out.println( System.identityHashCode( x ) ); System.out.println( s == x ); // 返回字符串对象的规范化表示形式 // 如果池已经包含一个等于此 String 对象的字符串(用 equals(Object) 方法确定),则返回池中的字符串。 // 否则,将此 String 对象添加到池中,并返回此 String 对象的引用(加入到池中以后的那个串的地址) String str = x.intern(); System.out.println( System.identityHashCode( str ) ); System.out.println( str == s ); } }
运行结果如下:
366712642 1829164700 false 366712642 true
从结果可以看出s和x的地址是不相等的,是因为String s = "hello,ecut", 首先在常量池中查找是否存在内容为"hello,ecut"字符串对象,如果不存在则在常量池中创建"hello,ecut",并让s引用该对象(12345),如果存在则直接让s引用该对象,而new String( "hello,ecut" )时会在堆中创建一个对象ABCDE,并由栈中x引用堆中的ABCDE对象,然后在在字符串常量池中查看,是否存在内容为"hello,ecut"字符串对象,若存在,则将new出来的字符串对象与字符串常量池中的对象(12345)联系起来若不存在,则在字符串常量池中创建一个内容为"hello,ecut"的字符串对象,并将堆中的对象与之联系起来。x.intern()方法则是如果池已经包含一个等于此 对象的字符串(用 equals(Object) 方法确定),则返回池中的字符串,否则,将此 String 对象添加到池中,并返回此 String 对象的引用(加入到池中以后的那个串的地址)。因此str和s地址相同。
==比较的是2个对象的地址,而equals比较的是2个对象的内容。
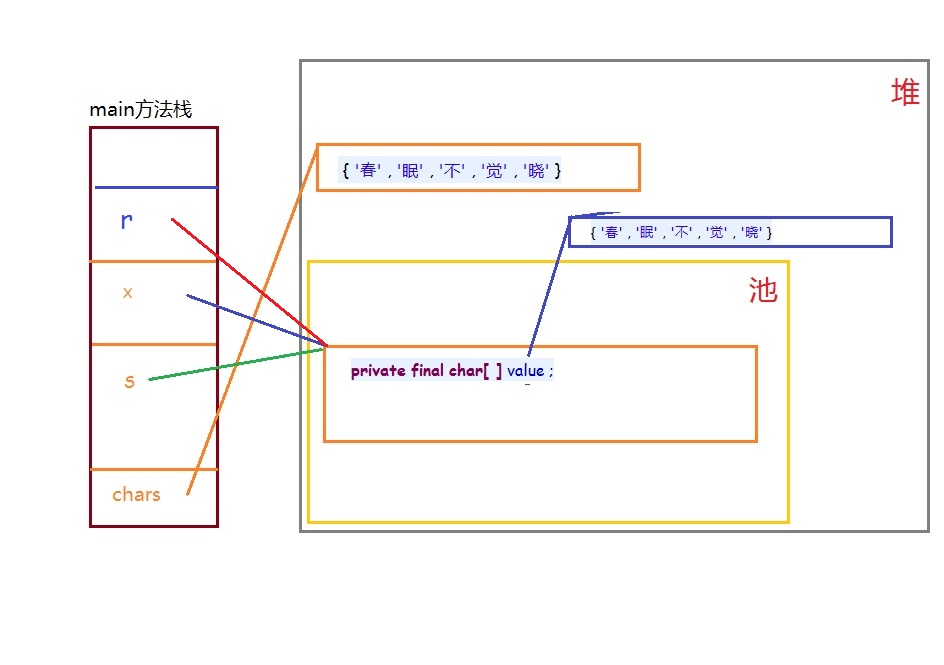
package ecut.strings; public class StringTest2 { public static void main(String[] args) { final char[] chars = { '春' , '眠' , '不' , '觉' , '晓' }; System.out.println( "chars: " + System.identityHashCode( chars ) ); String s = new String( chars ); System.out.println( "s : " + System.identityHashCode( s ) ); System.out.println( s ); String x = s.intern(); // 返回规范化表示形式 System.out.println( "s.intern : " + System.identityHashCode( x ) ); System.out.println( s == x ); // true String r = "春眠不觉晓"; System.out.println( s == r ); } }
运行结果如下:
chars: 366712642 s : 1829164700 春眠不觉晓 s.intern : 1829164700 true true
从结果可以看出s和r的地址是相等的,r调用的是String类的无参构造函数,根据源码this.value = "".value;其中value定义private final char[]创建一个空串并将它的值放在数组value中,s调用的构造方法是使用字符数组的有参构造,根据源码this.value = Arrays.copyOf(value,value.length)是将传入的字符数组拷贝到数组value中。因此String r = "春眠不觉晓";和 final char[] chars = { '春' , '眠' , '不' , '觉' , '晓' }; String s = new String( chars );是等价的。
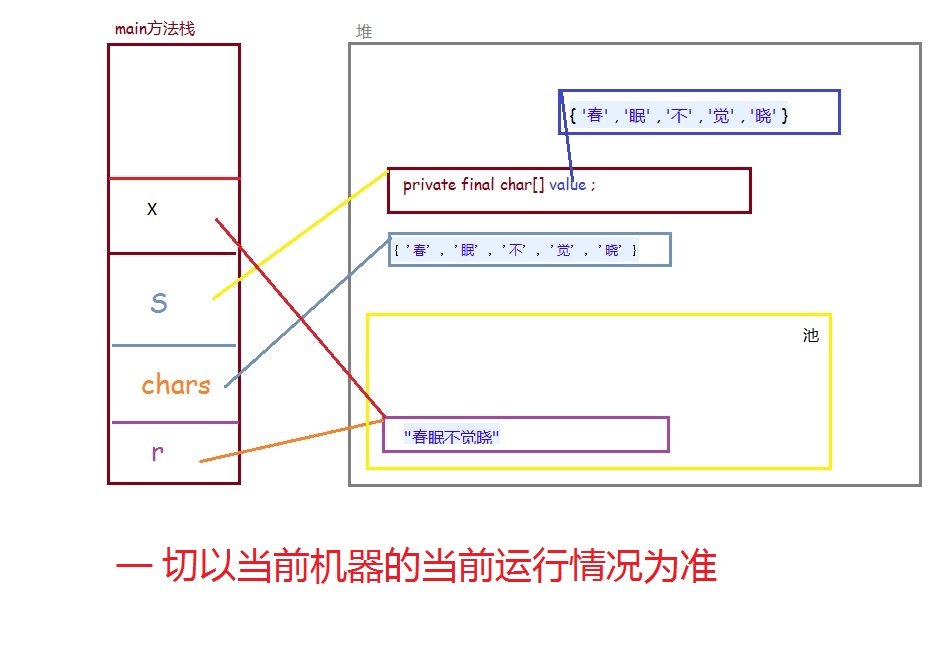
package ecut.strings; public class StringTest3 { public static void main(String[] args) { String r = "春眠不觉晓"; System.out.println( "r : " + System.identityHashCode( r ) ); final char[] chars = { '春' , '眠' , '不' , '觉' , '晓' }; String s = new String( chars ); System.out.println( "s : " + System.identityHashCode( s ) ); String x = s.intern(); System.out.println( "x : " + System.identityHashCode( x ) ); } }
运行结果如下:
r : 366712642 s : 1829164700 x : 366712642
栈:运行时的单位,存放基本类型的变量数据和对象的引用,栈解决程序的运行问题,即程序如何执行,或者说如何处理数据。
堆:存储的单位,用于存放所以的JAVA对象,堆解决的是数据存储的问题,即数据怎么放、放在哪儿。
常量池:存放字符串常量和基本类型常量(public static final)
使用字节数组构造String测试案例:
package ecut.strings; import java.util.Arrays; // 对于中文来说 UTF-8 编码可以是 2~3 个字节 (大部分都是3个字节) public class StringTest4 { public static void main(String[] args) throws Exception { String s = "今天天气孬abc" ; System.out.println( s.length() ); // byte[] bytes = s.getBytes(); // 采用默认编码 byte[] bytes = s.getBytes( "UTF-8" ); System.out.println( Arrays.toString( bytes ) ); System.out.println( bytes.length ); // String x = new String( bytes ); String x = new String( bytes , "UTF-8"); System.out.println( x ); } }
运行结果如下:
8 [-28, -69, -118, -27, -92, -87, -27, -92, -87, -26, -80, -108, -27, -83, -84, 97, 98, 99] 18 今天天气孬abc
字符串联的方式
测试案例:
package ecut.strings; /** * 当 字符串 变量 参与 串联 操作时 * 是通过 StringBuilder ( 或 StringBuffer ) 类及其 append 方法实现的 */ public class StringTest5 { public static void main(String[] args) { String a = "abc" ; String b = "xyz"; String d = "abcxyz" ; // 两个字符串字面值 通过 + 串联,直接在 池中完成 String c = "abc" + "xyz" ; // + 是 "串联" 作用 System.out.println( c == d ); System.out.println( "~~~~~~~~~~~~~~" ); // 字符串串联是通过 StringBuilder ( 或 StringBuffer ) 类及其 append 方法实现的 // 1、StringBuilder sb = new StringBuilder( a ); // 2、sb.append( b ) ; // 3、sb.toString() ---> new String( chars ) String e = a + b ; System.out.println( e == c ); System.out.println( e == d ); String f = e.intern(); System.out.println( f == d ); //JAVA编译器对string + 基本类型/常量 是当成常量表达式直接求值来优化的。 运行期的两个string相加,会产生新的对象的,存储在堆(heap)中 String g = a + "xyz" ;//a为变量,在运行期才会被解析。 System.out.println( g == c ); final String h = "abc" ; String i = h + "xyz" ; System.out.println( i == c );//h为常量,编译期会被优化 } }
运行结果如下:
true ~~~~~~~~~~~~~~ false false true false true
String常用方法
测试案例:
package ecut.strings; import java.nio.charset.Charset; import java.util.Arrays; /** */ public class StringTest6 { public static void main(String[] args) { String s = "How old are you ? " ; System.out.println("1、求字符串长度"); int len = s.length(); System.out.println("字符串的长度"+len); System.out.println("2、求字符串某一位置字符"); char ch = s.charAt(2);//索引范围为从 0 到 length() - 1。 System.out.println("字符串第2+1个字符是"+ch); System.out.println("3、提取子串"); String s1 = s.substring(2, 5);//beginIndex - 起始索引(包括) endIndex - 结束索引(不包括)。 String s2 = s.substring(18);//beginIndex 大于0小于等于String对象的长度,等于时返回空串。 System.out.println("子串s1为:"+s1); System.out.println("子串s2为"+s2); System.out.println("4、字符串比较"); String str1 = new String("abc"); String str2 = new String("ABC"); int a = str1.compareTo(str2);//若当前对象比参数大则返回正整数,反之返回负整数,相等返回0。 int b = str1.compareToIgnoreCase(str2);//忽略大小写 System.out.println("若当前对象比参数大则返回正整数,反之返回负整数,相等返回0"); boolean c = str1.equals(str2);//c=false boolean d = str1.equalsIgnoreCase(str2);//d=true System.out.println("比较当前字符串和参数字符串,在两个字符串相等的时候返回true,否则返回false。"); System.out.println("5、字符串中单个字符查找"); int in = s.indexOf('y'); System.out.println("字符串中y的位置"+in); System.out.println("6、字符串中字符的大小写转换"); String str3 = s.toLowerCase(); String str4 = s.toUpperCase(); System.out.println("转换为小写为"+str3); System.out.println("转换为大写为"+str4); System.out.println("7、字符串中字符的替换"); String str5 = s.replace('o', 'a'); System.out.println("a替换o后为"+str5); System.out.println("8、字符串连接"); String str6 = s.concat(str1); System.out.println("str1和s连接后为"+str6); System.out.println("9、截去字符串两端的空格"); String str7 = s.trim(); System.out.println("s截去字符串两端的空格,但对于中间的空格不处理后为"+str7); System.out.println("10、比较起始字符或结尾字符是否一致"); s.startsWith("a"); System.out.println("用来比较当前字符串的起始字符或子字符串prefix和终止字符或子字符串suffix是否和当前字符串相同,重载方法中同时还可以指定比较的开
始位置offset。"); System.out.println("11、作为分隔符进行字符串分解"); String[] str8 = s.split(" "); for( String str : str8 ) { System.out.println(str); } System.out.println("12、判断是否包含字符串"); s.contains("ow"); System.out.println("判断参数是否被包含在字符串中,并返回一个布尔类型的值。"); System.out.println("13、字符串转换为基本类型"); int e = Integer.parseInt("12"); float f = Float.parseFloat("12.34"); double g = Double.parseDouble("1.124"); System.out.println("e="+e+",f="+f+",g="+g); System.out.println("14、基本类型转换为字符串"); String str9 = String.valueOf(12); System.out.println("str9为"+str9); System.out.println("15、将字符从此字符串复制到目标字符数组。 "); char[] chars = new char[ 10 ]; System.out.println( chars[ 0 ] == 'u0000' ); // 将字符串中的 [ 4 , 7 )之间的字符 复制到 chars 数组的下标是5的位置开始 s.getChars( 4 , 7 , chars , 5 );// getChars()方法,不是返回一个数组,而是复制数组
System.out.println("将字符串中的 [ 4 , 7 )之间的字符 复制到 chars 数组的下标是5的位置开始 "); System.out.println( Arrays.toString( chars ) ); } }
运行结果如下:
1、求字符串长度 字符串的长度18 2、求字符串某一位置字符 字符串第2+1个字符是w 3、提取子串 子串s1为:w o 子串s2为 4、字符串比较 若当前对象比参数大则返回正整数,反之返回负整数,相等返回0 比较当前字符串和参数字符串,在两个字符串相等的时候返回true,否则返回false。 5、字符串中单个字符查找 字符串中y的位置12 6、字符串中字符的大小写转换 转换为小写为how old are you ? 转换为大写为HOW OLD ARE YOU ? 7、字符串中字符的替换 a替换o后为Haw ald are yau ? 8、字符串连接 str1和s连接后为How old are you ? abc 9、截去字符串两端的空格 s截去字符串两端的空格,但对于中间的空格不处理后为How old are you ? 10、比较起始字符或结尾字符是否一致 用来比较当前字符串的起始字符或子字符串prefix和终止字符或子字符串suffix是否和当前字符串相同,重载方法中同时还可以指定比较的开始位置offset。 11、作为分隔符进行字符串分解 How old are you ? 12、判断是否包含字符串 判断参数是否被包含在字符串中,并返回一个布尔类型的值。 13、字符串转换为基本类型 e=12,f=12.34,g=1.124 14、基本类型转换为字符串 str9为12 15、将字符从此字符串复制到目标字符数组。 true 将字符串中的 [ 4 , 7 )之间的字符 复制到 chars 数组的下标是5的位置开始 [
StringBuffer和StringBuilder
1、StringBuffer
package ecut.strings; public class StringBufferTest { public static void main(String[] args) { // s.value ==> "abc".value ; // String s = "abcxyz"; // char[] value = new char[ 3 + 16 ]; // value[ 0 ] = 'a' ; value[ 1 ] = 'b' ; value[ 2 ] = 'c' ; StringBuffer sb = new StringBuffer( "abc" ); // value[ 3 ] = 'x' ; value[ 4 ] = 'y' ; value[ 5 ] = 'z' ; sb.append( "xyz" ); String x = sb.toString() ; System.out.println( x ); //返回字符串对象的规范化表示形式。 String y = x.intern(); System.out.println( x == y ); System.out.println( "~~~~~~~~~~~~~~~~~~~~~~~~" ); // 池中有几个串 // "a" // "ab" // "abc" // "abcd" // "abcde" String str = "a" + "b" + "c" + "d" + "e" ; System.out.println( str ); StringBuffer buffer = new StringBuffer(); buffer.append( "a" ); buffer.append( "b" ); buffer.append( "c" ); buffer.append( "d" ); buffer.append( "e" ); String r = buffer.toString(); System.out.println( r ); } }
运行结果如下:
abcxyz true ~~~~~~~~~~~~~~~~~~~~~~~~ abcde abcde
2、StringBuilder
package ecut.strings; public class StringBuilderTest { public static void main(String[] args) { StringBuilder builder = new StringBuilder(); builder.append( "a" ); builder.append( "b" ); builder.append( "c" ); builder.append( "d" ); builder.append( "e" ); System.out.println( builder ); String r = builder.toString(); System.out.println( r ); //将此字符序列用其反转形式取代 builder.reverse(); System.out.println( builder ); } }
运行结果如下:
abcde
abcde
edcba
String、StringBuffer和StringBuilder区别
String 是被 final 修饰的,他的长度是不可变的,就算调用 String 的concat 方法,那也是把字符串拼接起来并重新创建一个对象,把拼接后的 String 的值赋给新创建的对象,而 StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象,调用StringBuffer 的 append 方法,来改变 StringBuffer 的长度,并且,相比较于 StringBuffer,String 一旦发生长度变化,是非常耗费内存的!StringBuilder 类在 Java 5 中被提出,它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问)。由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。 append方法与直接使用+串联相比,减少常量池的浪费。
待解决问题
两幅图结果为什么不一样
参考博客链接
http://blog.csdn.net/ithomer/article/details/9936743
https://www.cnblogs.com/ITtangtang/p/3976820.html
转载请于明显处标明出处