继续上一篇:http://www.cnblogs.com/CoolJayson/p/7430654.html
首先需要安装上台虚拟机, 分别为: master, salve1, slave2
1.复制CentOS_6.5, 分别重命名为-slave1和-slave2
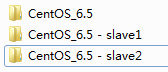
2.用虚拟机打开slave1和slave2, 因为我们使用的是NAT模式, 此时三台虚拟机的ip是相同的需要进行修改.(关于如何修改请参考上一篇)
修改完成后重启网络服务, 查看ip和网卡(HWaddr)是否有相同的, 如果网卡相同的话, 进入到虚拟机设置, 移除原来的网络适配器,再重新添加一个网络适配器, 网卡就改变了.
完成后通过SecureCRT连接三台虚拟机, 测试是否能够连接网络.



3. 安装jdk
在虚拟机中设置共享文件夹(目录为jdk所在的目录)
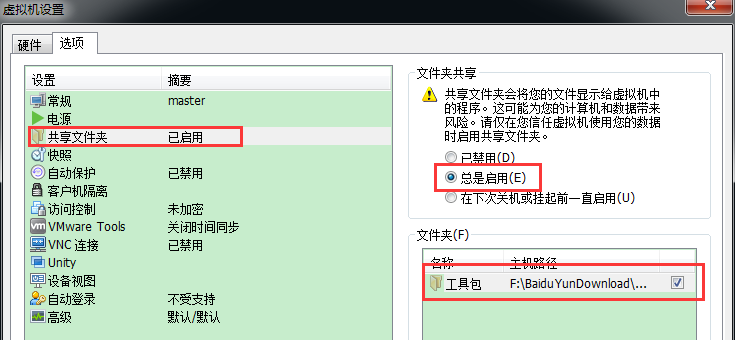
查看是否共享成功, 使用命令 cd /mnt/hgfs/ 下查看是否有共享的文件夹

共享成功后将jdk拷贝到 /usr/local/src/目录下

开始安装jdk

安装完成后添加环境变量: 编辑根目录下的.bashrc文件

添加完环境变量后按ESC, 使用命令 :wq 保存退出, 使用source ~/.bashrc是配置的环境变量生效(或者用命令bash)


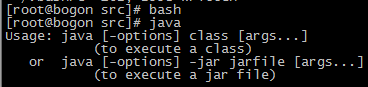
执行以下命令, 将jdk从master拷贝到salve2(拷贝到salve1也是相同操作), 然后重复上述操作在slave1和salve2中安装jdk并且配置环境变量.

>>>>>>>>>>>>>开始安装hadoop集群>>>>>>>>>>>>>
1.在共享文件夹中将hadoop压缩包拷贝到/usr/local/src/目录下, 同时进行解压

2.进入到hadoop解压的目录中,创建一个tmp文件夹用来存放临时文件

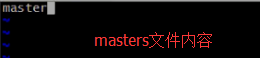
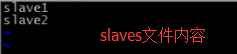
3.进入到conf目录下, 修改masters文件和slaves文件

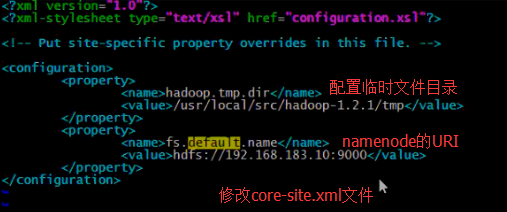
4.修改core-site.xml文件和mapred-site.xml文件

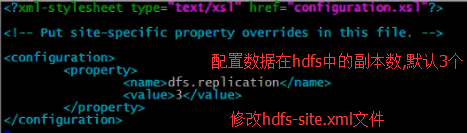
5.修改hdfs-site.xml文件和hadoop-env.sh文件

6.本地网络配置, 修改/etc/hosts文件, 配置后可以直接通过hostname(master/slave1/slave2)来访问虚拟机而不需要通过ip来访问

7.修改虚拟机的hostname, 如果要永久生效需要修改/etc/sysconfig/network文件


目前为止在master节点一共修改了以下8个文件:
hadoop的conf目录下的: masters, slaves, core-site.xml, mapred-site.xml, hdfs-site.xml, hadoop-env.sh
以及 /etc/hosts文件和 /etc/sysconfig/network文件.
8.将hadoop解压文件远程拷贝到slave1和slave2节点. 检查以下拷贝的文件是否有误.


9.修改slave1和slave2节点的/etc/hosts文件和/etc/sysconfig/network文件. slave1和slave2的/etc/hosts文件和master相同.



10.通过 hostname slave1和hostname slave2命令让hostname立即生效. /etc/sysconfig/network文件的修改要重启虚拟机后才能生效


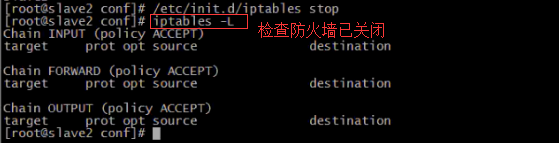
11.系统环境不同, 为了避免网络传输出现问题时难排查, 对防火墙和selinux进行关闭. 每台机器都要关闭防火墙和selinux. 通过iptables -L命令检查防火墙是否已关闭


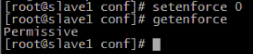
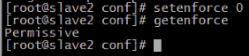
12.建立每台机器之间的互信机制(在远程访问每台机器的ip或hostname时不用再输入密码)
在master节点通过ssh-keygen生成密钥文件

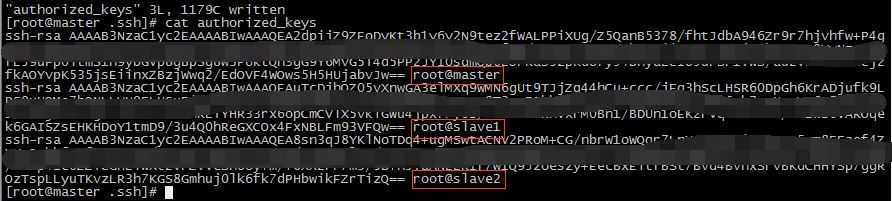
进入~/.ssh/隐藏目录, 将id_rsa.pub公钥文件拷贝到authorized_keys文件, 并检查两个文件内容是否相同.

在slave1和slave2节点也通过ssh-keygen命令生成密钥, 并把它们的公钥拷贝到master节点的authorized_keys文件中
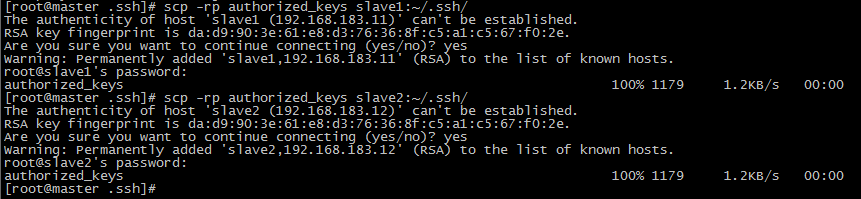
将authorized_keys文件拷贝到slave1和slave2节点中.
此时在master节点可以直接通过ssh slave1来访问slave1节点而不需要密码, 在slave1节点也可以通过ssh master直接访问master.

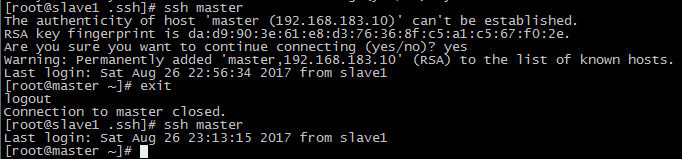
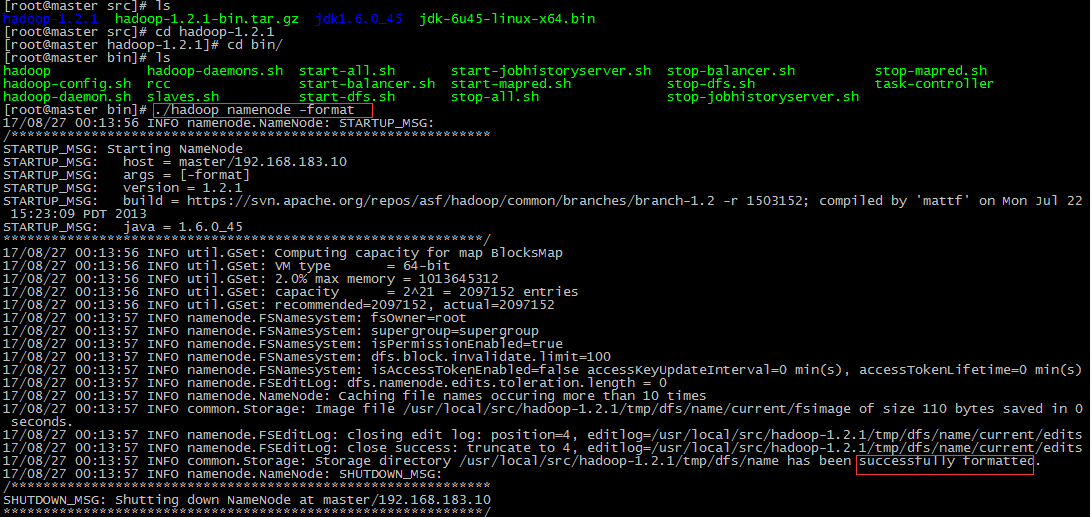
13.进入到hadoop目录下的bin目录, 先进行格式化
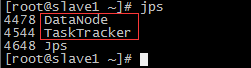
14.通过 ./start-all.sh 命令把整个集群启动起来, 通过jps查看每个节点的进程.


15.通过 ./hadoop fs -ls / 命令查看hdfs文件系统
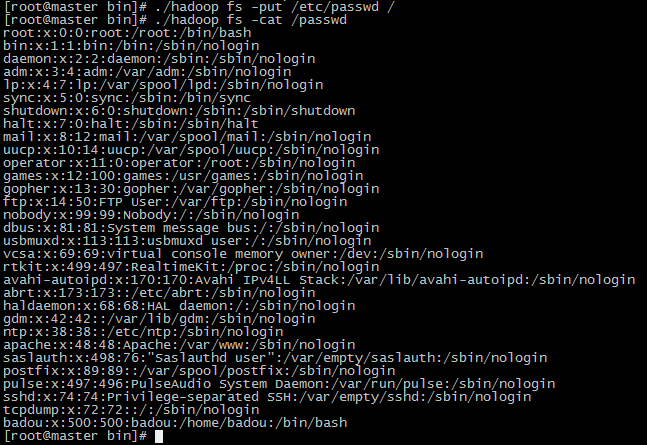
16.通过 ./hadoop fs -put /etc/passwd / 命令将passwd文件拷贝到hdfs文件系统中, 如果没有报错就说明成功了.

17.通过 ./hadoop fs -cat /passwd 命令来读取passwd文件.
---------------- 到这里hadoop集群就配置成功了!!!------------------