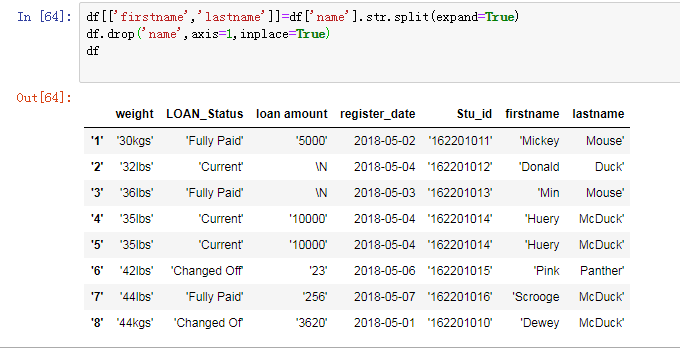
首先,我们先要读入数据:
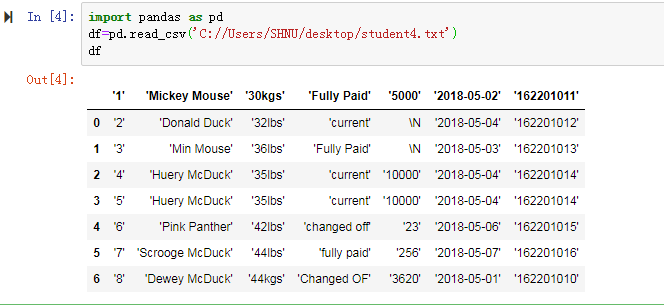
然后检查数据出现的问题:
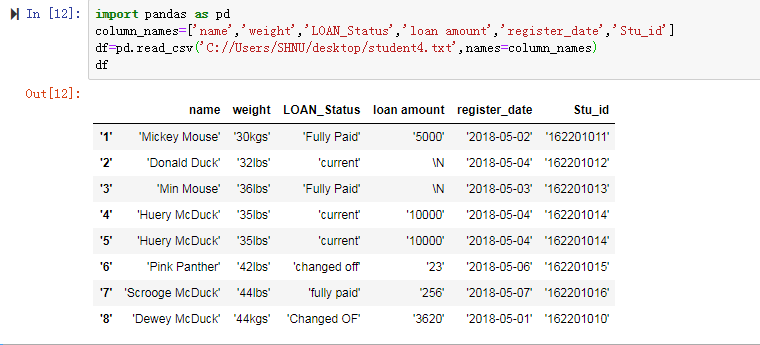
1.没有表头,增加表头
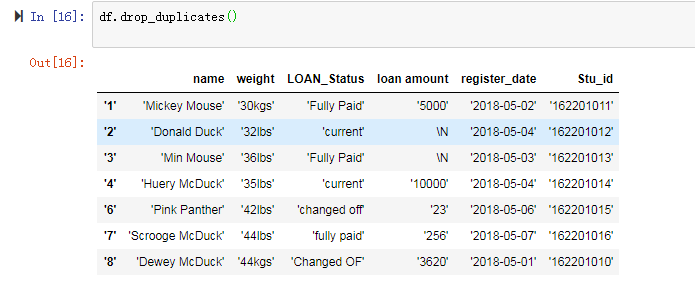
2.去除重复值:
df.duplicate()使用布尔数据查看数据表中是否有重复值,df.drop_duplicates(),删去重复的值
这里有两点需要说明:第一,数据表中两个条目间所有列的内容都相等时duplicated才会判断为重复值。(Duplicated也可以单独对某一列进行重复值判断)。第二,duplicated支持从前向后(first),
和从后向前(last)两种重复值查找模式。默认是从前向后进行重复值的查找和判断。换句话说就是将后出现的相同条件判断为重复值。

df.drop_duplicates(),删去重复的值
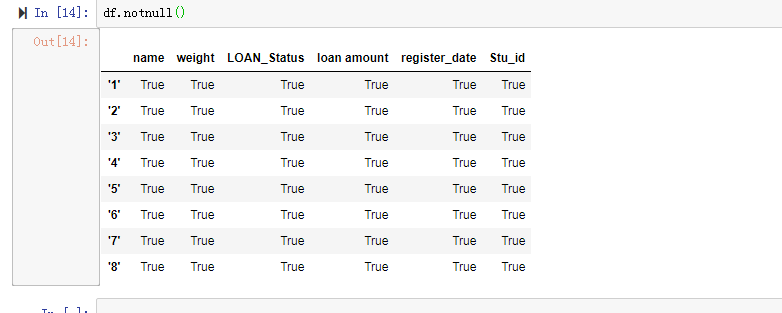
Pandas中查找数据表中空值的函数有两个,一个是函数isnull,如果是空值就显示True。另一个函数notnull正好相反,如果是空值就显示False。
以下两个函数的使用方法以及通过isnull函数获得的空值数量。

对于空值有两种处理的方法,第一种是使用fillna函数对空值进行填充,可以选择填充0值或者其他任意值。第二种方法是使用dropna函数直接将包含空值的数据删除。
df.fillna(0), df.dropna()
还有一种经常的用法是使用平均值代替,比如假设loan amount列中与空值,我们可以采用平均值代表空值
df['loan amount']=df['loan amount'].fillna(df['loan amount'].mean())
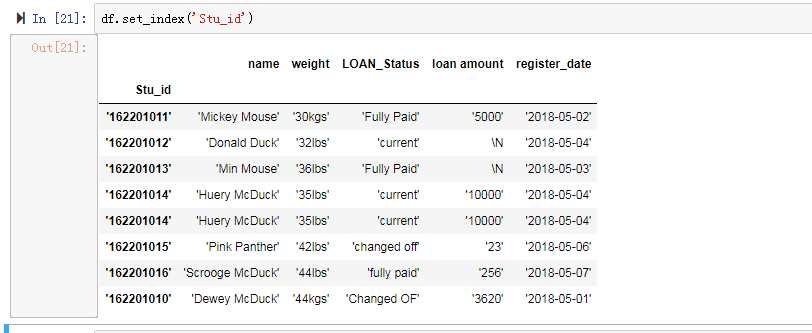
接下来换索引:
用法是df.set_index('column')
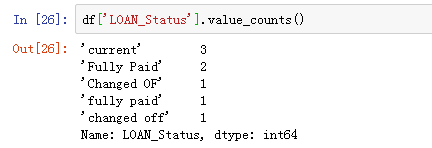
数据间的空格:
空格会影响我们后续会数据的统计和计算。从下面的结果中就可以看出空格对于常规的数据统计造成的影响。
df['LOAN_Status'].value_counts()
Python中去除空格的方法有三种,第一种是去除数据两边的空格,第二种是单独去除左边的空格,第三种是单独去除右边的空格。
df['LOAN_Status']=df['LOAN_Status'].map(str.strip)#删除左右俩边的空格
df['LOAN_Status']=df['LOAN_Status'].map(str.lstrip)#删除左边空格
df['LOAN_Status']=df['LOAN_Status'].map(str.rstrip)#删除右边空格
大小写转换
大小写转换的方法也有三种可以选择,分别为全部转换为大写,全部转换为小写,和转换为首字母大写。
df['LOAN_Status']=df['LOAN_Status'].map(str.upper)#全部大写
df['LOAN_Status']=df['LOAN_Status'].map(str.lower)#全部小写
df['LOAN_Status']=df['LOAN_Status'].map(str.title)#首字母写
最后我们还需要对数据表中关键字段的内容进行检查,确保关键字段中内容的统一。主要包括数据是否全部为字符,字母或数字。
df['weight'].apply(lambda x:
x.isalpha())#检查该列是否全部为字符
df['weight'].apply(lambda x:
x.isalnum())#检查该列是否全部为数字
df['weight'].apply(lambda x:
x.isalpha())#检查该列是否全部为字母
第一步是更改和规范数据格式,所使用的函数是astype。下面是更改数据格式的代码:
df['loan amount']=df['loan amount'].astype(np.int64)#数据格式处理
df['register_date']=pd.to_datetime(df['register_date'])#日期格式的数据需要使用to_datatime函数进行处理
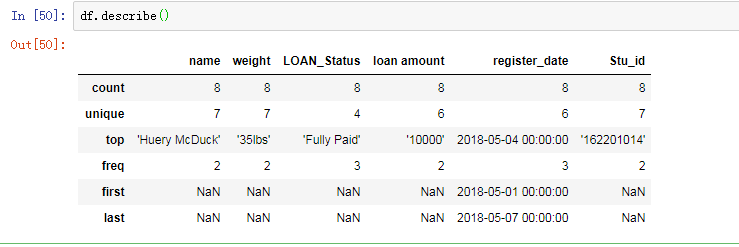
数据中的异常和极端值
用describe函数可以生成描述统计结果。其中我们主要关注最大值(max)和最小值(min)情况。
使用平均值代替,公式:
df.replace([23],df['loan amount'].mean())
数据分组
把weight数据进行分组
bins=[30,35,40,45]
group_names=['A','B','C','D']
df['categories']= pd.cut(df['weight'],bins, labels=group_names)
数据分列