Zookeeper
简介
根据Zookeeper官方介绍
ZooKeeper is a high-performance coordination service for distributed applications. It exposes common services - such as naming, configuration management, synchronization, and group services - in a simple interface so you don't have to write them from scratch. You can use it off-the-shelf to implement consensus, group management, leader election, and presence protocols. And you can build on it for your own, specific needs.
ZooKeeper是一种用于分布式应用程序的高性能协调服务。 它在一个简单的界面中提供了常用服务 - 例如命名,配置管理,同步和组服务 - 因此您不必从头开始编写它们。 您可以使用现成的方法来实现共识,组管理,领导者选举和在线协议。 您可以根据自己的特定需求进行构建。
众所周知,协调服务很难做到。他们特别容易出现竞争条件和死锁等错误。ZooKeeper背后的动机是减轻分布式应用程序从头开始实施协调服务的责任。
主要提供了以下服务
- Naming Service;
- 配置管理;
- Leader Election;
- 服务发现;
- 同步;
- Group Service;
- Barrier;
- 分布式队列;
- 两阶段提交
设计目标
- 简单
ZooKeeper允许分布式进程通过共享的分层命名空间相互协调,该命名空间的组织方式与标准文件系统类似。namespace由数据寄存器组成 - 在ZooKeeper用语中称为znodes - 这些与文件和目录类似。与专为存储而设计的典型文件系统不同,ZooKeeper数据保存在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟数量。
- 自我复制
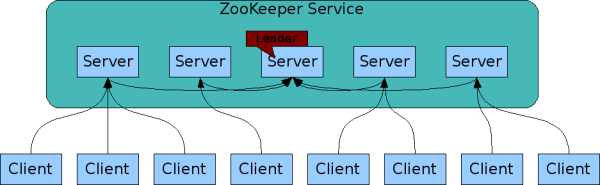
与它协调的分布式进程一样,ZooKeeper本身也可以在称为集合的一组主机上进行复制。
组成ZooKeeper服务的服务器必须彼此了解。它们维护内存中的状态图像,以及持久性存储中的事务日志和快照。只要大多数服务器可用,ZooKeeper服务就可用。
客户端连接到单个ZooKeeper服务器。客户端维护TCP连接,通过该连接发送请求,获取响应,获取监视事件以及发送心跳。如果与服务器的TCP连接中断,则客户端将连接到其他服务器。
- 有序
ZooKeeper使用反映所有ZooKeeper事务顺序的数字标记每个更新。后续操作可以使用该顺序来实现更高级别的抽象,例如同步原语。
- 快
它在“读取主导”(read-dominan)工作负载中特别快。ZooKeeper应用程序在数千台计算机上运行,并且在读取比写入更常见的情况下表现最佳,比率大约为10:1。
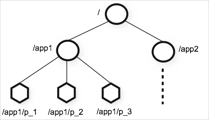
数据模型和分层命名空间
ZooKeeper提供的namespace非常类似于标准文件系统。名称是由斜杠(/)分隔的路径元素序列。ZooKeeper namespace中的每个节点都由路径标识。
Zookeeper为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,这种特性使得Zookeeper不能用于存放大量的数据,每个节点的存放数据上限为1M
(存放数据上限应该是可以配置的吧)。
节点和临时节点
与文件系统不同的是,一个znode可以有数据也能有子节点,就像同时是文件和目录
ZooKeeper旨在存储协调数据:状态信息,配置,位置信息等,因此存储在每个节点的数据通常很小,在字节到千字节范围内。
Znodes维护一个stat结构,其中包括数据更改,ACL更改和时间戳的版本号,以允许缓存验证和协调更新。每次znode的数据更改时,版本号都会增加。例如,每当客户端检索数据时,它也接收数据的版本。
存储在命名空间中每个znode的数据以原子方式读取和写入。读取获取与znode关联的所有数据字节,写入替换所有数据。每个节点都有一个访问控制列表(ACL),限制谁可以做什么。
ZooKeeper也有短暂节点的概念。只要创建znode的会话处于活动状态,就会存在这些znode。会话结束时,znode将被删除。当您想要实现[tbd]时,短暂节点很有用。
四种类型的znode
1、PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
2、PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
条件更新和监视器-》zookeeper的通知机制
ZooKeeper支持监视器(watch)的概念。客户端可以在znode上设置监视器。当znode更改时,将触发并删除监视器。触发监视器时,客户端会收到一个数据包,指出znode已更改。如果客户端与其中一个ZooKeeper服务器之间的连接中断,则客户端将收到本地通知。这些可以用于[tbd]的实现。
保证
zk提供一系列保证
- 顺序一致性 - 客户端的更新将按发送顺序应用。分布式锁
- 原子性 - 更新成功或失败。没有部分结果。
- 单系统映像 - 无论服务器连接到哪个服务器,客户端都将看到相同的服务视图。
- 可靠性 - 一旦应用了更新,它将从那时起持续到客户端覆盖更新。
- 及时性 - 系统的客户视图保证在特定时间范围内是最新的。
分布式锁
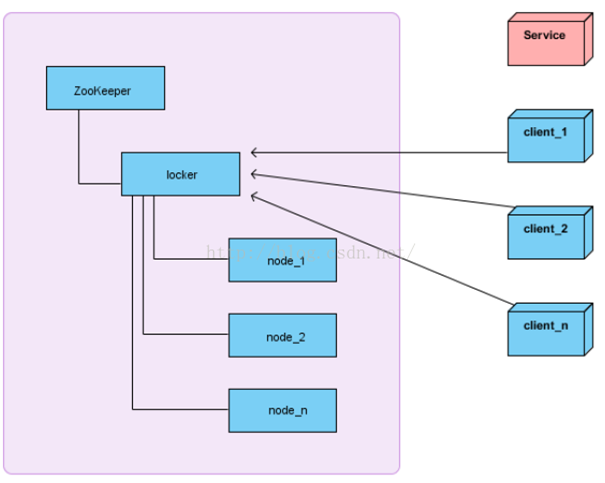
client在获取分布式锁的时候在locker节点下创建临时顺序节点,释放锁的时候删除该临时节点。客户端调用createNode方法在locker下创建临时顺序节点,然后调用getChildren(“locker”)来获取locker下面的所有子节点,注意此时不用设置任何Watcher。客户端获取到所有的子节点path之后,如果发现自己创建的节点在所有创建的子节点序号最小,那么就认为该客户端获取到了锁。如果发现自己创建的节点并非locker所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,然后对其调用exist()方法,同时对其注册事件监听器。之后,让这个被关注的节点删除,则客户端的Watcher会收到相应通知,此时再次判断自己创建的节点是否是locker子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。当前这个过程中还需要许多的逻辑判断。
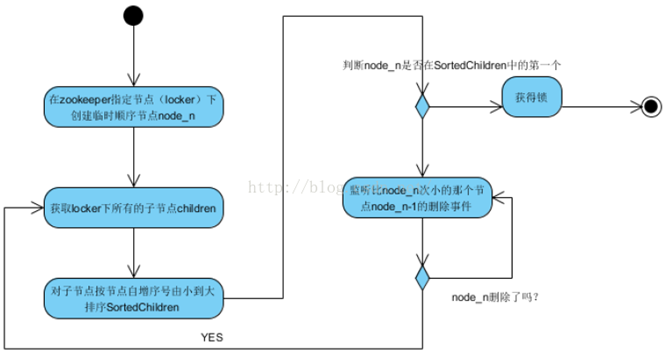
Zookeeper队列管理(文件系统、通知机制)
两种类型的队列:
1、同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
2、队列按照 FIFO 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。在特定的目录下创建PERSISTENT_SEQUENTIAL节点,创建成功时Watcher通知等待的队列,队列删除序列号最小的节点用以消费。此场景下Zookeeper的znode用于消息存储,znode存储的数据就是消息队列中的消息内容,SEQUENTIAL序列号就是消息的编号,按序取出即可。由于创建的节点是持久化的,所以不必担心队列消息的丢失问题。
文件复制
Zookeeper作为一个集群提供一致的数据服务,自然,它要在所有机器间做数据复制。数据复制的好处:
1、容错:一个节点出错,不致于让整个系统停止工作,别的节点可以接管它的工作;
2、提高系统的扩展能力 :把负载分布到多个节点上,或者增加节点来提高系统的负载能力;
3、提高性能:让客户端本地访问就近的节点,提高用户访问速度。
对zookeeper来说,它采用的方式是写任意(对数据的修改可提交给任意的节点)。
存疑:zk可以读任意节点,写必须通过leader才对
通过增加机器,它的读吞吐能力和响应能力扩展性非常好,而写,随着机器的增多吞吐能力肯定下降(这也是它建立observer的原因),而响应能力则取决于具体实现方式,是延迟复制保持最终一致性,还是立即复制快速响应。
Zookeeper工作原理
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
Client与Server是通过NIO方式通信的。
消息是FIFO方式执行的(顺序的,先进先出)。
读消息可以通过zookeeper的leader和所有的follower。
写消息必须通过leader。
广播模式
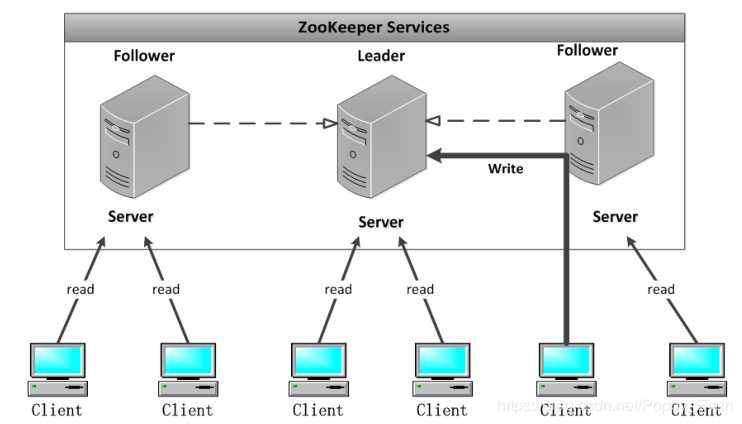
(1)Client通过某个follower请求写操作时,该follower会把这个请求发给leader;(2)leader再将这个更新(proposal),顺序发送给follower;(3)follower收到leader更新时,follower会将数据持久化到磁盘;(4)当follower写到磁盘后,就会向leader发送ACK;(5)当leader收到半数以上的follower向它发送ACK后,就向全部的follower发送commit;(6)leader并在本地commit消息(commit的意思是就是这个消息可对外读了);(7)当follower收到leader发送的commit后,就会将磁盘里的数据写进内存数据库,同时commit(每个follower都有内存数据库,Client去向follower请求数据时,都是通过内存数据库读取的)。同时每条消息,都有一个递增的id。
恢复模式
1、进入恢复模式
当leader宕机或者丢失大多数follower后,即进入恢复模式。
2、结束恢复模式
新leader被选举起来后,且大多数的follower完成与leader的状态同步后,恢复模式即结束,进入广播模式。
3、恢复模式的意义
每个消息的id(zxid)是64位,前面32位称为epoch,后面32位称为counter。
(1)发现集群中被commit的proposal的最大的zxid,之后的leader不会commit比这zxid小的proposal,也就是说leader只能commit比这大的proposal。
(2)建立新的epoch,从而保证之前的leader不能再commit新的proposal(每选举出一个新的leader,epoch都会改变,且比之前的大,且保证一个leader的任期内,epoch不会被改变)。
(3)集群中大部分节点都commit过前一个leader commit过的消息,而新的leader是被大部分节点锁支持的(会选举出于前leader保持最为紧密的follower作为leader),所以被之前leader commit过的proposal不会丢失,至少被一个节点所保存。
(4)新的leader会与所有follower通信,从而保证大部分节点都拥有最新的数据。
如何选举leader
当leader崩溃或者leader失去大多数的follower,这时zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。
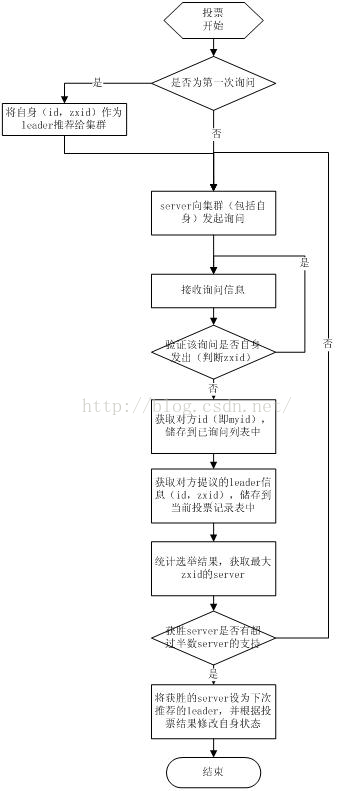
basic paxos
(1)选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
(2)选举线程首先向所有Server发起一次询问(包括自己);
(3)选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
(4)收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
(5)线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数,设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。 通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数必须是奇数2n+1,且存活的Server的数目不得少于n+1. 每个Server启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的server还会从磁盘快照中恢复数据和会话信息,zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。
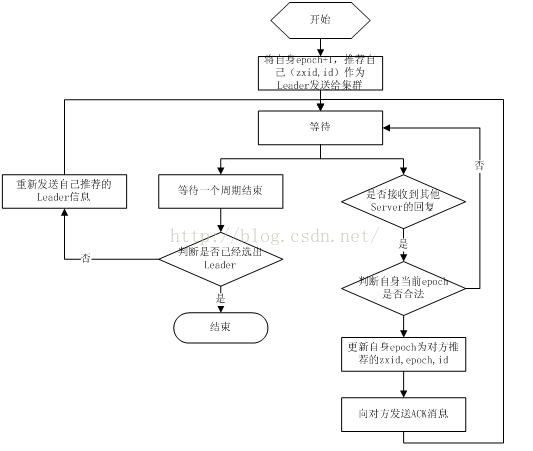
fast paxos
fast paxos流程是在选举过程中,某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和 zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。
Zookeeper同步流程
选完Leader以后,zk就进入状态同步过程。
1、Leader等待server连接;
2、Follower连接leader,将最大的zxid发送给leader;
3、Leader根据follower的zxid确定同步点;
4、完成同步后通知follower 已经成为uptodate状态;
5、Follower收到uptodate消息后,又可以重新接受client的请求进行服务了。

zookeeper负载均衡和nginx负载均衡区别
zk的负载均衡是可以调控,nginx只是能调权重,其他需要可控的都需要自己写插件;但是nginx的吞吐量比zk大很多,应该说按业务选择用哪种方式。
zookeeper watch机制
Watch机制官方声明:一个Watch事件是一个一次性的触发器,当被设置了Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了Watch的客户端,以便通知它们。
Zookeeper机制的特点:
1、一次性触发数据发生改变时,一个watcher event会被发送到client,但是client只会收到一次这样的信息。
2、watcher event异步发送watcher的通知事件从server发送到client是异步的,这就存在一个问题,不同的客户端和服务器之间通过socket进行通信,由于网络延迟或其他因素导致客户端在不通的时刻监听到事件,由于Zookeeper本身提供了ordering guarantee,即客户端监听事件后,才会感知它所监视znode发生了变化。所以我们使用Zookeeper不能期望能够监控到节点每次的变化。Zookeeper只能保证最终的一致性,而无法保证强一致性。
3、数据监视Zookeeper有数据监视和子数据监视getdata() and exists()设置数据监视,getchildren()设置了子节点监视。
4、注册watcher getData、exists、getChildren
5、触发watcher create、delete、setData
6、setData()会触发znode上设置的data watch(如果set成功的话)。一个成功的create() 操作会触发被创建的znode上的数据watch,以及其父节点上的child watch。而一个成功的delete()操作将会同时触发一个znode的data watch和child watch(因为这样就没有子节点了),同时也会触发其父节点的child watch。
7、当一个客户端连接到一个新的服务器上时,watch将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到watch的。而当client重新连接时,如果需要的话,所有先前注册过的watch,都会被重新注册。通常这是完全透明的。只有在一个特殊情况下,watch可能会丢失:对于一个未创建的znode的exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个watch事件可能会被丢失。
8、Watch是轻量级的,其实就是本地JVM的Callback,服务器端只是存了是否有设置了Watcher的布尔类型
名词解释
原语
是执行过程中不可被打断的基本操作,你可以理解为一段代码,这段代码在执行过程中不能被打断(在多道程序设计里进程间相互切换,还可能有中断发生,经常会被打断)。像原子一样具有不可分割的特性, 所以叫原语, 像原子一样的语句
znode
Zookeeper的一个命名空间,也是zk的一个节点。由数据寄存器组成