什么是Elasticsearch?
Elasticsearch is a real-time, distributed storage, search, and analytics engine
Elasticsearch 是一个实时的分布式存储、搜索、分析的引擎。
介绍那儿有几个关键字:
实时、分布式、搜索、分析
于是我们就得知道Elasticsearch是怎么做到实时的,Elasticsearch的架构是怎么样的(分布式)。存储、搜索和分析(得知道Elasticsearch是怎么存储、搜索和分析的)
为什么要用Elasticsearch
在学习一项技术之前,必须先要了解为什么要使用这项技术。所以,为什么要使用Elasticsearch呢?我们在日常开发中,数据库也能做到(实时、存储、搜索、分析)。
相对于数据库,Elasticsearch的强大之处就是可以模糊查询。
有的同学可能就会说:我数据库怎么就不能模糊查询了??我反手就给你写一个SQL:
select * from user where name like '%公众号Java%'
这不就可以把公众号Java相关的内容搜索出来了吗?
的确,这样做的确可以。但是要明白的是:name like %Java%这类的查询是不走索引的,不走索引意味着:只要你的数据库的量很大(1亿条),你的查询肯定会是秒级别的
而且,即便给你从数据库根据模糊匹配查出相应的记录了,那往往会返回大量的数据给你,往往你需要的数据量并没有这么多,可能50条记录就足够了。
还有一个就是:用户输入的内容往往并没有这么的精确,比如我从Google输入ElastcSeach(打错字),但是Google还是能估算我想输入的是Elasticsearch
而Elasticsearch是专门做搜索的,就是为了解决上面所讲的问题而生的,换句话说:
Elasticsearch对模糊搜索非常擅长(搜索速度很快)
从Elasticsearch搜索到的数据可以根据评分过滤掉大部分的,只要返回评分高的给用户就好了(原生就支持排序)
没有那么准确的关键字也能搜出相关的结果(能匹配有相关性的记录)
下面我们就来学学为什么Elasticsearch可以做到上面的几点。
Elasticsearch的数据结构
众所周知,你要在查询的时候花得更少的时间,你就需要知道他的底层数据结构是怎么样的;举个例子:
树型的查找时间复杂度一般是O(logn)
链表的查找时间复杂度一般是O(n)
哈希表的查找时间复杂度一般是O(1)
….不同的数据结构所花的时间往往不一样,你想要查找的时候要快,就需要有底层的数据结构支持
从上面说Elasticsearch的模糊查询速度很快,那Elasticsearch的底层数据结构是什么呢?我们来看看。
我们根据“完整的条件”查找一条记录叫做正向索引;我们一本书的章节目录就是正向索引,通过章节名称就找到对应的页码。

http://img.blog.itpub.net/blog/2020/01/15/ec0abd31539b7b77.jpeg?x-oss-process=style/bb
分词
首先我们得知道为什么Elasticsearch为什么可以实现快速的“模糊匹配”/“相关性查询”,实际上是你写入数据到Elasticsearch的时候会进行分词。
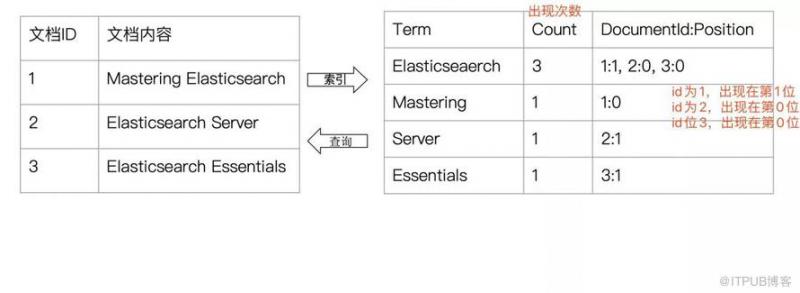
还是以上图为例,上图出现了4次“算法”这个词,我们能不能根据这次词为它找他对应的目录?Elasticsearch正是这样干的,如果我们根据上图来做这个事,会得到类似这样的结果:
算法 ->2,13,42,56
这代表着“算法”这个词肯定是在第二页、第十三页、第四十二页、第五十六页出现过。这种根据某个词(不完整的条件)再查找对应记录,叫做倒排索引。
再看下面的图,好好体会一下:
http://img.blog.itpub.net/blog/2020/01/15/49ac85e92050ae30.jpeg?x-oss-process=style/bb
分词器
众所周知,世界上有这么多的语言,那Elasticsearch怎么切分这些词呢?,Elasticsearch内置了一些分词器
Standard Analyzer 。按词切分,将词小写
Simple Analyzer。按非字母过滤(符号被过滤掉),将词小写
WhitespaceAnalyzer。按照空格切分,不转小写
….等等等
Elasticsearch分词器主要由三部分组成:
Character Filters(文本过滤器,去除HTML)
Tokenizer(按照规则切分,比如空格)
TokenFilter(将切分后的词进行处理,比如转成小写)
显然,Elasticsearch是老外写的,内置的分词器都是英文类的,而我们用户搜索的时候往往搜的是中文,现在中文分词器用得最多的就是IK。
分词后的数据结构
http://img.blog.itpub.net/blog/2020/01/15/e476671247601eb8.jpeg?x-oss-process=style/bb
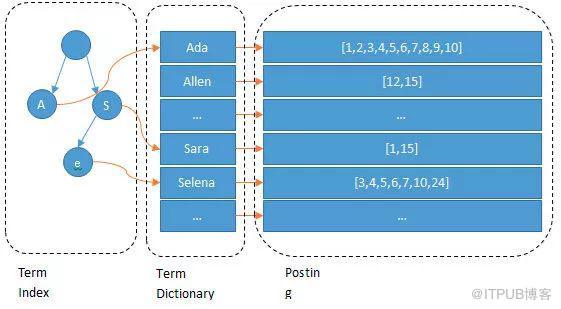
我们输入一段文字,Elasticsearch会根据分词器对我们的那段文字进行分词(也就是图上所看到的Ada/Allen/Sara..),这些分词汇总起来我们叫做Term Dictionary,而我们需要通过分词找到对应的记录,这些文档ID保存在PostingList
在Term Dictionary中的词由于是非常非常多的,所以我们会为其进行排序,等要查找的时候就可以通过二分来查,不需要遍历整个Term Dictionary
由于Term Dictionary的词实在太多了,不可能把Term Dictionary所有的词都放在内存中,于是Elasticsearch还抽了一层叫做Term Index,这层只存储 部分 词的前缀,Term Index会存在内存中(检索会特别快)
Term Index在内存中是以FST(Finite State Transducers)的形式保存的,其特点是非常节省内存。FST有两个优点:
1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
2)查询速度快。O(len(str))的查询时间复杂度。
前面讲到了Term Index是存储在内存中的,且Elasticsearch用FST(Finite State Transducers)的形式保存(节省内存空间)。Term Dictionary在Elasticsearch也是为他进行排序(查找的时候方便),其实PostingList也有对应的优化。
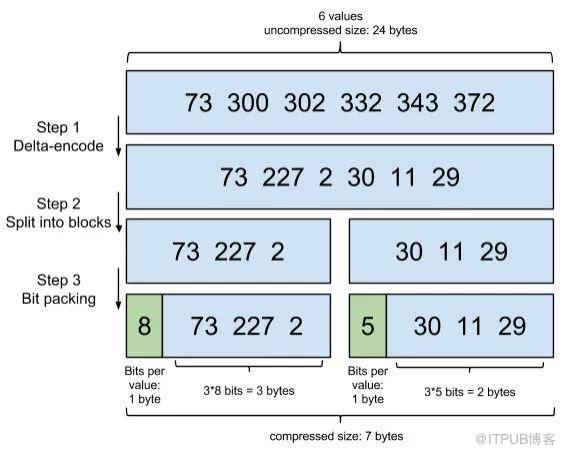
PostingList会使用Frame Of Reference(FOR)编码技术对里边的数据进行压缩,节约磁盘空间。
http://img.blog.itpub.net/blog/2020/01/15/0a79629a90e32902.jpeg?x-oss-process=style/bb
PostingList里边存的是文档ID,我们查的时候往往需要对这些文档ID做交集和并集的操作(比如在多条件查询时),PostingList使用Roaring Bitmaps来对文档ID进行交并集操作。
使用Roaring Bitmaps的好处就是可以节省空间和快速得出交并集的结果。

http://img.blog.itpub.net/blog/2020/01/15/2f498bfcad6bf161.jpeg?x-oss-process=style/bb
所以到这里我们总结一下Elasticsearch的数据结构有什么特点:

https://mmbiz.qpic.cn/sz_mmbiz_jpg/2BGWl1qPxib0bRFtypiaZQYvF8c6jrGaXAStRPlG9EdiafSyJeib83230WTOHk1jj3OojmFaU6ra6elEedLIgmibcWg/640?wx_fmt=jpeg&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1
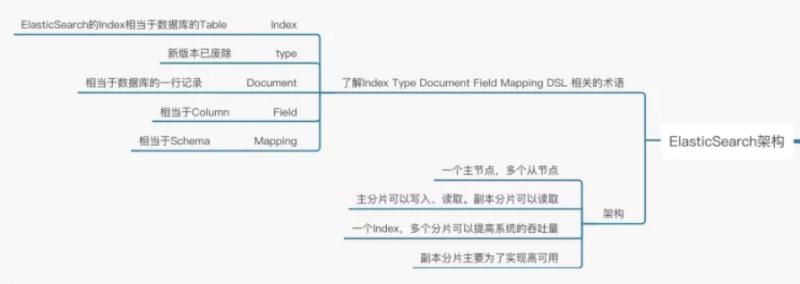
Elasticsearch的术语和架构
在讲解Elasticsearch的架构之前,首先我们得了解一下Elasticsearch的一些常见术语。
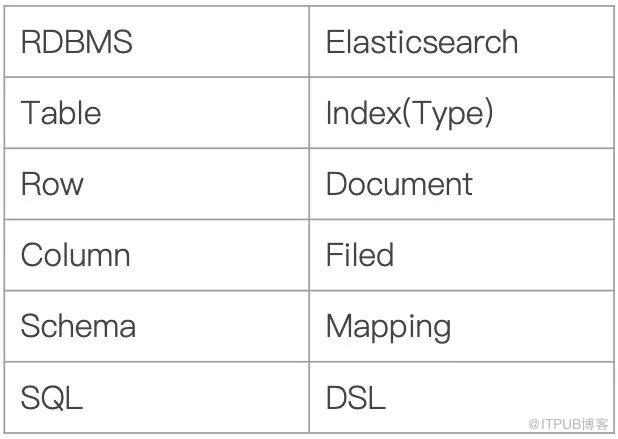
Index:Elasticsearch的Index相当于数据库的Table
Type:这个在新的Elasticsearch版本已经废除(在以前的Elasticsearch版本,一个Index下支持多个Type--有点类似于消息队列一个topic下多个group的概念)
Document:Document相当于数据库的一行记录
Field:相当于数据库的Column的概念
Mapping:相当于数据库的Schema的概念
DSL:相当于数据库的SQL(给我们读取Elasticsearch数据的API)
http://img.blog.itpub.net/blog/2020/01/15/4c87fb1488ae694d.jpeg?x-oss-process=style/bb
相信大家看完上面的对比图,对Elasticsearch的一些术语就不难理解了。那Elasticsearch的架构是怎么样的呢?下面我们来看看:
一个Elasticsearch集群会有多个Elasticsearch节点,所谓节点实际上就是运行着Elasticsearch进程的机器。
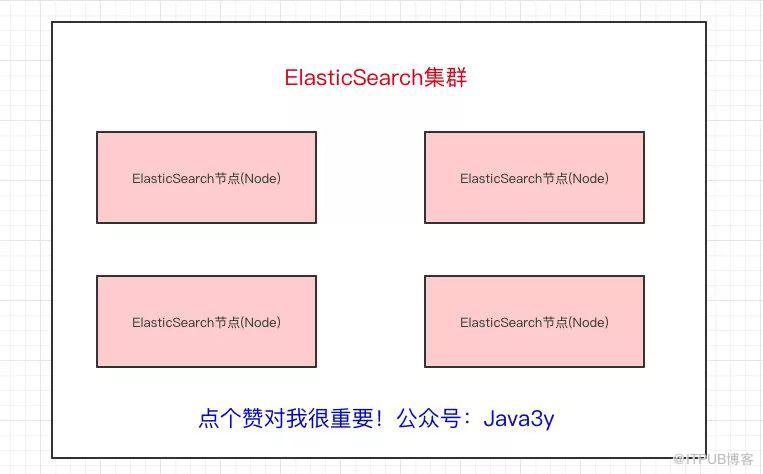
http://img.blog.itpub.net/blog/2020/01/15/3c5431e7e272353e.jpeg?x-oss-process=style/bb
在众多的节点中,其中会有一个Master Node,它主要负责维护索引元数据、负责切换主分片和副本分片身份等工作(后面会讲到分片的概念),如果主节点挂了,会选举出一个新的主节点。
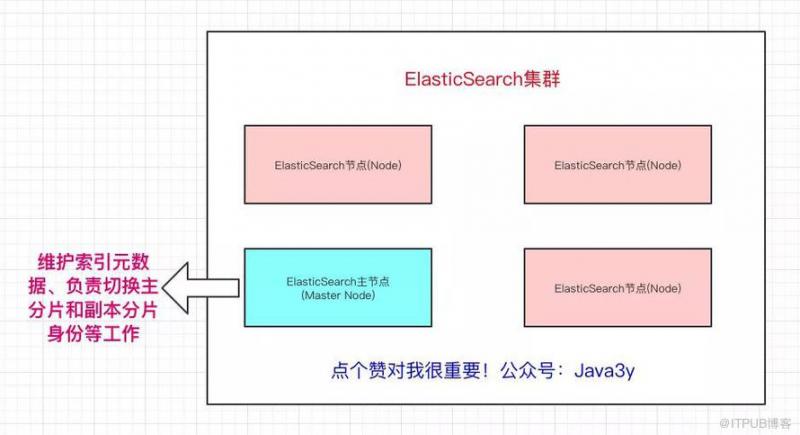
http://img.blog.itpub.net/blog/2020/01/15/a27f04b40d53acb4.jpeg?x-oss-process=style/bb
从上面我们也已经得知,Elasticsearch最外层的是Index(相当于数据库 表的概念);一个Index的数据我们可以分发到不同的Node上进行存储,这个操作就叫做分片。
比如现在我集群里边有4个节点,我现在有一个Index,想将这个Index在4个节点上存储,那我们可以设置为4个分片。这4个分片的数据合起来就是Index的数据
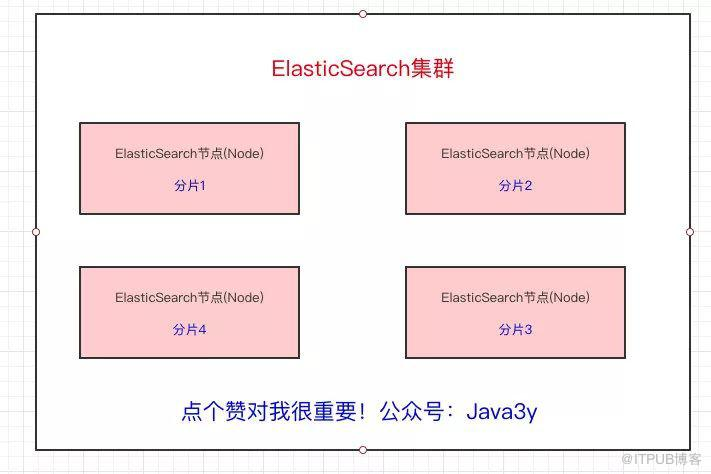
http://img.blog.itpub.net/blog/2020/01/15/a7d730c3413c4d97.jpeg?x-oss-process=style/bb
为什么要分片?原因也很简单:
如果一个Index的数据量太大,只有一个分片,那只会在一个节点上存储,随着数据量的增长,一个节点未必能把一个Index存储下来。
多个分片,在写入或查询的时候就可以并行操作(从各个节点中读写数据,提高吞吐量)
现在问题来了,如果某个节点挂了,那部分数据就丢了吗?显然Elasticsearch也会想到这个问题,所以分片会有主分片和副本分片之分(为了实现高可用)
数据写入的时候是写到主分片,副本分片会复制主分片的数据,读取的时候主分片和副本分片都可以读。
Index需要分为多少个主分片和副本分片都是可以通过配置设置的
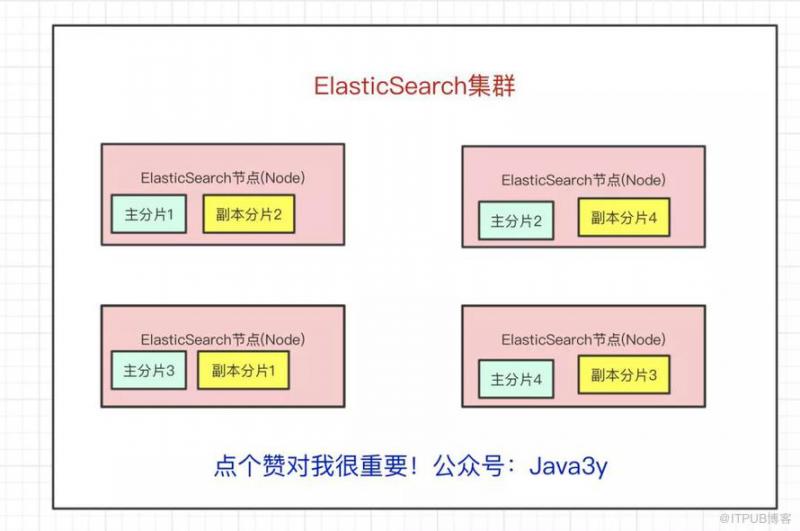
http://img.blog.itpub.net/blog/2020/01/15/f2d0ec61b5e4b7c3.jpeg?x-oss-process=style/bb
如果某个节点挂了,前面所提高的Master Node就会把对应的副本分片提拔为主分片,这样即便节点挂了,数据就不会丢。
到这里我们可以简单总结一下Elasticsearch的架构了:
http://img.blog.itpub.net/blog/2020/01/15/aea5ad333db601f0.jpeg?x-oss-process=style/bb
Elasticsearch 写入的流程
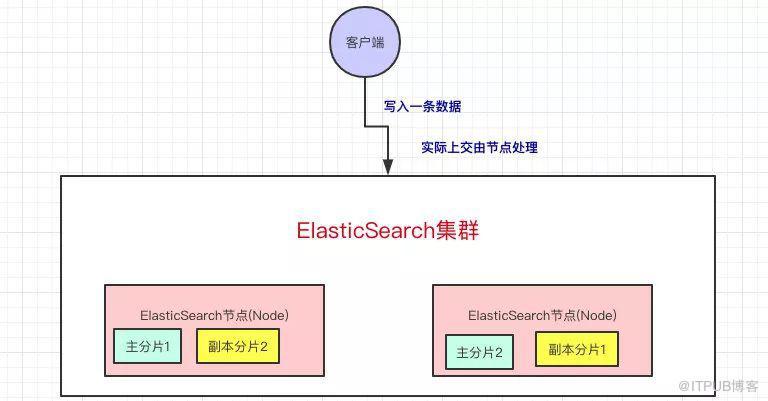
上面我们已经知道当我们向Elasticsearch写入数据的时候,是写到主分片上的,我们可以了解更多的细节。
客户端写入一条数据,到Elasticsearch集群里边就是由节点来处理这次请求:
http://img.blog.itpub.net/blog/2020/01/15/ec4b71bc1213e12b.jpeg?x-oss-process=style/bb
集群上的每个节点都是coordinating node(协调节点),协调节点表明这个节点可以做路由。比如节点1接收到了请求,但发现这个请求的数据应该是由节点2处理(因为主分片在节点2上),所以会把请求转发到节点2上。
coodinate(协调)节点通过hash算法可以计算出是在哪个主分片上,然后路由到对应的节点
shard = hash(document_id) % (num_of_primary_shards)
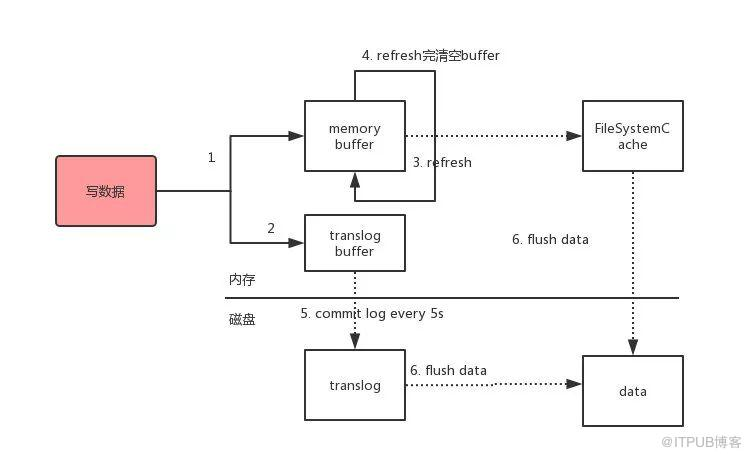
路由到对应的节点以及对应的主分片时,会做以下的事:
1、将数据写到内存缓存区
2、然后将数据写到translog缓存区
3、每隔1s数据从buffer中refresh到FileSystemCache中,生成segment文件,一旦生成segment文件,就能通过索引查询到了
4、refresh完,memory buffer就清空了。
5、每隔5s中,translog 从buffer flush到磁盘中
6、定期/定量从FileSystemCache中,结合translog内容flush index到磁盘中。
http://img.blog.itpub.net/blog/2020/01/15/25213cbe268544ed.jpeg?x-oss-process=style/bb
解释一下:
1、Elasticsearch会把数据先写入内存缓冲区,然后每隔1s刷新到文件系统缓存区(当数据被刷新到文件系统缓冲区以后,数据才可以被检索到)。所以:Elasticsearch写入的数据需要1s才能查询到
2、为了防止节点宕机,内存中的数据丢失,Elasticsearch会另写一份数据到日志文件上,但最开始的还是写到内存缓冲区,每隔5s才会将缓冲区的刷到磁盘中。所以:Elasticsearch某个节点如果挂了,可能会造成有5s的数据丢失。
3、等到磁盘上的translog文件大到一定程度或者超过了30分钟,会触发commit操作,将内存中的segement文件异步刷到磁盘中,完成持久化操作。
说白了就是:写内存缓冲区(定时去生成segement,生成translog),能够让数据能被索引、被持久化。最后通过commit完成一次的持久化。

http://img.blog.itpub.net/blog/2020/01/15/ba437a2f703752ad.jpeg?x-oss-process=style/bb
等主分片写完了以后,会将数据并行发送到副本集节点上,等到所有的节点写入成功就返回ack给协调节点,协调节点返回ack给客户端,完成一次的写入。
Elasticsearch更新和删除
Elasticsearch的更新和删除操作流程:
给对应的doc记录打上.del标识,如果是删除操作就打上delete状态,如果是更新操作就把原来的doc标志为delete,然后重新新写入一条数据
前面提到了,每隔1s会生成一个segement 文件,那segement文件会越来越多越来越多。Elasticsearch会有一个merge任务,会将多个segement文件合并成一个segement文件。
在合并的过程中,会把带有delete状态的doc给物理删除掉。

http://img.blog.itpub.net/blog/2020/01/15/1e88128d2422b165.jpeg?x-oss-process=style/bb
Elasticsearch查询
查询我们最简单的方式可以分为两种:
1、根据ID查询doc
2、根据query(搜索词)去查询匹配的doc
public TopDocs search(Query query, int n);
public Document doc(int docID);
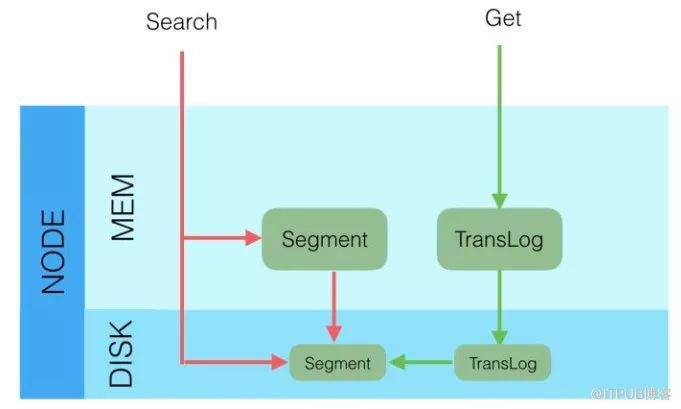
根据ID去查询具体的doc的流程是:
1、检索内存的Translog文件
2、检索硬盘的Translog文件
3、检索硬盘的Segement文件
根据query去匹配doc的流程是:
同时去查询内存和硬盘的Segement文件
http://img.blog.itpub.net/blog/2020/01/15/e28927442f4c96ed.jpeg?x-oss-process=style/bb
从上面所讲的写入流程,我们就可以知道,因为segement文件是每隔一秒才生成一次的,Get(通过ID去查Doc是实时的),Query(通过query去匹配Doc是近实时的)
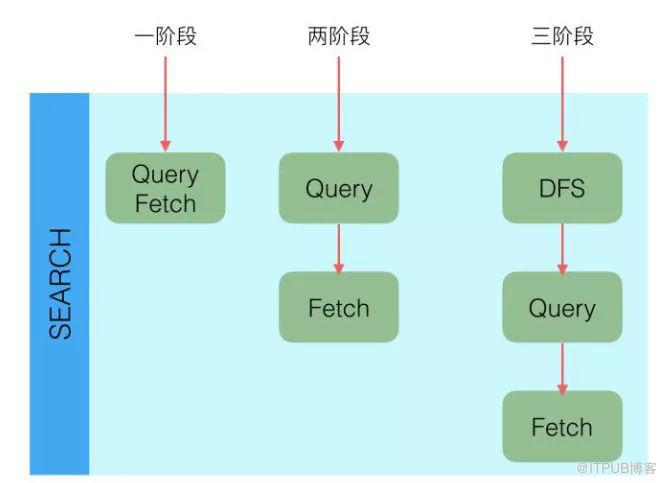
Elasticsearch查询又分可以为三个阶段:
1、QUERY_AND_FETCH(查询完就返回整个Doc内容)
2、QUERY_THEN_FETCH(先查询出对应的Doc id ,然后再根据Doc id 匹配去对应的文档)
3、DFS_QUERY_THEN_FETCH(先算分,再查询)
「这里的分指的是 词频率和文档的频率(Term Frequency、Document Frequency)众所周知,出现频率越高,相关性就更强」
http://img.blog.itpub.net/blog/2020/01/15/695a11190bcea92c.jpeg?x-oss-process=style/bb
一般我们用得最多的就是QUERY_THEN_FETCH,第一种查询完就返回整个Doc内容(QUERY_AND_FETCH)只适合于只需要查一个分片的请求。
QUERY_THEN_FETCH总体的流程流程大概是:
1、客户端请求发送到集群的某个节点上。集群上的每个节点都是coordinate node(协调节点)
2、然后协调节点将搜索的请求转发到所有分片上(主分片和副本分片都行)
3、每个分片将自己搜索出的结果(doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
4、接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端。
Query Phase阶段时节点做的事:
1、协调节点向目标分片发送查询的命令(转发请求到主分片或者副本分片上)
2、数据节点(在每个分片内做过滤、排序等等操作),返回doc id给协调节点
Fetch Phase阶段时节点做的是:
1、协调节点得到数据节点返回的doc id,对这些doc id做聚合,然后将目标数据分片发送抓取命令(希望拿到整个Doc记录)
2、数据节点按协调节点发送的doc id,拉取实际需要的数据返回给协调节点
主流程我相信大家也不会太难理解,说白了就是:由于Elasticsearch是分布式的,所以需要从各个节点都拉取对应的数据,然后最终统一合成给客户端
只是Elasticsearch把这些活都干了,我们在使用的时候无感知而已。

http://img.blog.itpub.net/blog/2020/01/15/1fd511e83098d3be.jpeg?x-oss-process=style/bb
倒排索引
1. 倒排索引是什么?
假设有一个交友网站,信息表如下:
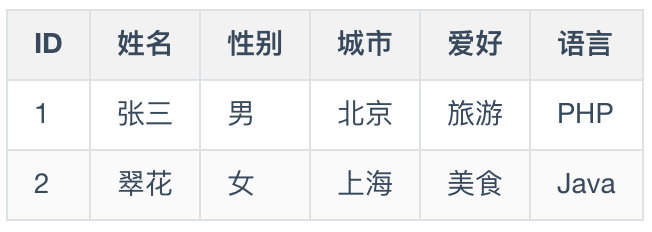
美女1:“我要找在上海做 PHP 的哥哥。”
需要匹配 性别、城市、语言列。
美女2:“我要找北京的爱旅游、爱美食的 JAVA 哥哥。”
更复杂了是吧,实际场景中,会有更复杂的排列组合。
对于这类的搜索,关系型数据库的索引就很难应付了,适合使用全文搜索的倒排索引。
倒排索引是一种数据库的索引形式,存储了 “内容 -> 文档” 映射关系,目的是快速的进行全文搜索。
2. 倒排索引是怎么工作的?
主要包括2个过程:创建倒排索引、倒排索引搜索
2.1 创建倒排索引
举个例子,有2个文档:
Document#1:“Recipe of pasta with sauce pesto”
Document#2:“Recipe of delicious carbonara pasta”
先对文档进行分词,形成一个个的 token,也就是 单词,然后保存这些 token 与文档的对应关系。结果如下:

2.2 倒排索引搜索
搜索示例:搜索 “pasta recipe”
先分词,得到2个 token,( “pasta”、“recipe” )。
然后去倒排索引中进行匹配。

这2个词在2个文档中都匹配,所以2个文档都会返回,而且分数相同。
搜索 “carbonara pasta”

同样,2个文档都匹配,都会返回。
这次 document#2 的分数要比 document#1 高。因为 #2 匹配了2个词(“carbonara”、“pasta”),#1 只匹配了一个(“pasta”)。
2.3 转换
有时我们可以在保存和搜索之前对 token 进行一些转换,最普遍的例如:
1、扔掉停止词
停止词是那些使用量非常大,但又没有什么意义的词。
例如英文中的 “of”, “the”, “for” ……
2、元素化
把单词处理为字典中的标准词,例如:
“running” => “run”
“walks” => “walk”
“thought” =>“think”
3、词干分析
通过切断词尾将一个词转换成词根形式的过程。
不能处理不规则动词的情况,但可以处理字典中没有的词。
最后
这篇文章主要对Elasticsearch简单入了个门,实际使用肯定还会遇到很多坑,但我目前就到这里就结束了。
参考:
https://mp.weixin.qq.com/s/tq3zMbs-ZmSK-trprq82gg
http://blog.itpub.net/69900354/viewspace-2673541/
https://www.cnblogs.com/yogoup/p/12216663.html