原理:postgresql数据库的数据复制主要是基于wal日志进行复制的,分2中复制模式,一种是实例级别的物理复制,一种是表级别的逻辑复制。
物理复制:
1.核心原理为主库将预写日志WAL日志流发送给备库,备库接受到日志后进行重做
2.只能针对postgresql数据库实例进行复制
3.主库可读可写,但是备库只允许读
4.能多数据库DDL(主要是 alert create 等针对于表结构变化的语句)操作进行复制
5.要求postgresql大版本必须一致
逻辑复制:
1.核心原理也是基于WAL日志,逻辑复制会根据预先设置好的规则解析WAL日志,将WAL二进制文件解析成一定格式的逻辑变化信息,然后主库将WAL日志信息发送给备库,备库再根据接受的wal日志进行复制
2.可以针对数据库表进行单独的复制
3.不会复制DDL操作
4.备库允许读写
5.不要求postgresql数据库版本一致
进行主备数据库的部署:
1.准备一台物理机和一台虚拟机
2.分别安装postgresql数据库,我这里安装的大版本是11
台式机的IP:192.168.12.50
虚拟机的IP:192.168.12.55
异步流复制 参数配置
主要配置以下参数
postgresql.conf wal_level = replica archive_mode = on archive_command='/bin/date' max_wal_senders=10 wal_keep_segments=512 hot_standby=0n
wal_level 主要有minimal/replica/logical 三种模式,如果需要进行数据备份,至少需要设置到replica 。replica包含minimal中所有的日志,并多了一些wal归档,备份和复制中启用只读查询的一些wal信息
archive_mode 用来控制是否启用归档
archive_command 设置归档目录,可以设置到本机目录有可以设置到远程目录
max_wal_senders 控制主库上wal最大的并发数,不能比max_connections值大,一般一个流复制只需要消耗一个wal发送进程
wal_keep_segments 设置主库pg_wal目录保留的最小wal日志文件数,以便备库落后主库时可以通过主库保留的wal进行追回,这个值设置的越大,理论上备库在异常断开时追平主库的几率就越大
hot_standby 控制数据库恢复过程中是否启用读操作,这参数通常用在流复制的备库,开启此参数后,流复制备库只支持读sql 不支持写操作
建议主库和备库的配置完全一致
配置主库的pg_hba.conf
host replication all 192.168.12.50/32 md5 host replication all 192.168.12.55/32 md5
配置2条备份策略时由于主库和备库的角色不是静止的,他们的角色是客户互换的/。所以建议主库和备库的配置一致
停止备库的pgsql服务,然后备份data文件夹
备份备库的postgresql/11/data文件夹,然后清空data文件夹
然后CMD输入如下命令
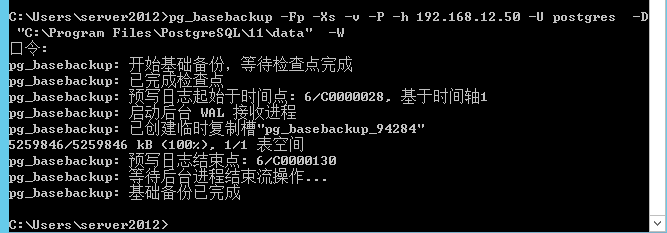
-D 参数表示指定备节点用来接收主库数据的目标路径
-F 指定pg_basebackup 命令生成的备份数据格式 支持2中备份格式,p格式是指生成的备份数据库喝主库上的数据文件布局一样,t格式是指将备份文件打成tar包然后存储在指定的目录中 一般我们采用p模式
-X 参数设置在备份过程中长生的wal日志包含在备份中,有f和s2种方式。f指的是wal日志在基本备份完成后被传送到备份节点wal,s方式下主库上除了启动一个基准备份wal发送进程外还会额外启动一个wal发送进程用于发送主库产生的wal增量日志
-v 表示启用verbose模式, 命令执行过程种打印出各个阶段的执行日志
-P 参数显示数据文件/表空间文件的近似传输比
-h 主库的ip
-U 主库的登录用户名
执行完上面的命令,就会发现备份库的data文件夹中多了很多的文件 如下图
将share文件下的recovery.conf.sample文件复制到data文件下,并修改名字为recovery.conf
去除

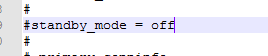

前面的#号
更改后

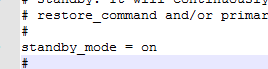

修改postgresql.conf中的配置
hot_standby = on
然后重启备份库即可完成