记录在unbantu14.04, caffe框架下对MobileNet的自有数据集fine tune。
首先git clone一下caffe版本的mobilenet https://github.com/shicai/MobileNet-Caffe.git
然后把deploy.prototxt文件修改一下
Modify deploy.prototxt and save it as your train.prototxt as follows: Remove the first 5 input/input_dim lines, and add Image Data layer in the beginning like this:
layer { name: "data" type: "ImageData" top: "data" top: "label" include { phase: TRAIN } transform_param { scale: 0.017 mirror: true crop_size: 224 mean_value: [103.94, 116.78, 123.68] } image_data_param { source: "your_list_train_txt" batch_size: 32 # your batch size new_height: 256 new_ 256 root_folder: "your_path_to_training_data_folder" } }
Remove the last prob layer, and add Loss and Accuracy layers in the end like this:
layer { name: "loss" type: "SoftmaxWithLoss" bottom: "fc7" bottom: "label" top: "loss" } layer { name: "top1/acc" type: "Accuracy" bottom: "fc7" bottom: "label" top: "top1/acc" include { phase: TEST } } layer { name: "top5/acc" type: "Accuracy" bottom: "fc7" bottom: "label" top: "top5/acc" include { phase: TEST } accuracy_param { top_k: 5 } }
然后包括了train_val.prototxt, deploy.prototxt,
通过createDB.py来生成带label的txt文件:代码如下:
第二个方法为生成LMDB的文件
# -*- coding: UTF-8 -*- import os import re import commands def createFileList(images_path, txt_save_path): fw = open(txt_save_path,"w") images_name = os.listdir(images_path) for eachname in images_name: pattern_cat = r'(^cat.d{0,10}.jpg$)' pattern_dog = r'(^dog.d{0,10}.jpg$)' cat_name = re.search(pattern_cat, eachname) dog_name = re.search(pattern_dog, eachname) if cat_name != None: fw.write(cat_name.group(0) + ' n16000001 ') if dog_name != None: fw.write(dog_name.group(0) + ' n16000002 ') print "done with txt generation!" fw.close() def create_db(caffe_root, images_path, txt_save_path): lmdb_name = 'img_train.lmdb' lmdb_save_path = caffe_root + 'models/MobileNet-Caffe/' + lmdb_name convert_imageset_path = caffe_root + 'build/tools/convert_imageset' cmd = """%s --shuffle --resize_height=256 --resize_width=256 %s %s %s""" status, output = commands.getstatusoutput(cmd % (convert_imageset_path, images_path, txt_save_path, lmdb_save_path)) print output if(status == 0): print "lmbd is done!" if __name__ == '__main__': caffe_root = '/home/wy/ssd-caffe/caffe/' my_caffe_project = caffe_root + 'models/MobileNet-Caffe/' images_path = caffe_root + 'models/MobileNet-Caffe/val/' txt_name = 'label_val.txt' txt_save_path = my_caffe_project + txt_name createFileList(images_path, txt_save_path) #create_db(caffe_root, images_path, txt_save_path)
生成的txt文件如下,带labels: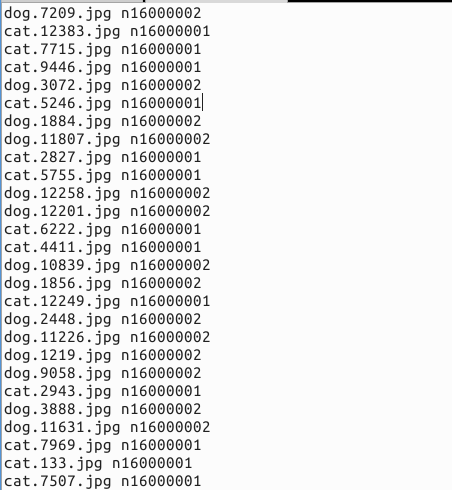
对于自己的solver,由于怀疑测试集是imagenet的分支,所以,把lr调的很低,我的solver文件如下:
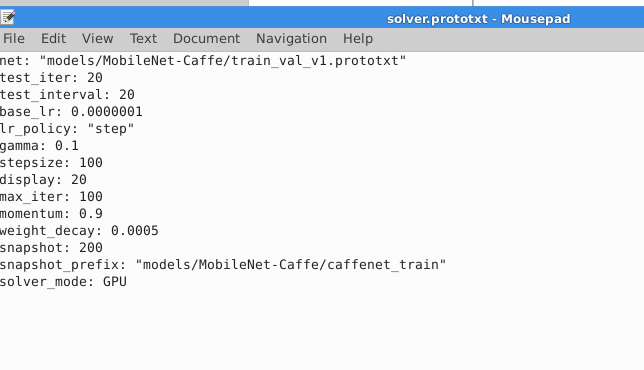
调参的过程很复杂,因为收敛非常快,最后总结出一个办法,要么把lr调低,要么在提前fc一层就开始fine tune。
tips:在fine tune的时候,要改layer中的名字,这样会使得caffemodel的weight参数跳过赋值。
最后训练的结果如下
有时间再把整个过程整理下,今天权当记录一下。
最终accuracy nearly 98.5%