在原版的基础上,添加了进程池,进程锁,以及数据处理分析小实验
原版的链接为:http://www.cnblogs.com/ChrisInsistPy/p/8981820.html
首先分析一下在整个程序的哪个进程中,可以实现多进程提高运行效率,首先爬虫程序会先去拿网站的url,然后对url内的json数据进行处理,之后写入文件
所以在整个过程中,我们可以分别让多个进程去拿url拿response的数据,然后分批处理,写入文件中
这里有个知识点,就是在python中,每个进程都有一个GIL锁,确保同一时间只能有一个线程运行,所以多进程可能会更实用,具体可以google一下
首先找到我们遍历url的方法中,把方法体进一步封装到 scraping_page_data()方法里
并创建线程池:
def dynamtic_scraping_data(page, headers, fileName): pool = multiprocessing.Pool() #进程池 lock = multiprocessing.Manager().Lock() #加一个写锁,确保每页的内容在一起 ''' if code ' lock = multiprocessing.Lock()'报错: RuntimeError: Lock objects should only be shared between processes through inheritance ''' for i in range(page): pool.apply_async(scraping_page_data,(lock, i, headers, fileName)) pool.close() pool.join()
这里有几个知识点,首先,对于进程池,会根据主机的系统资源,去分配到底有多少条进程
其次如果不调用join方法,子进程会在主进程结束后继续执行,因为后面有数据分析的功能所以我们条用了join方法,让主进程去等待其他的进程
在进程池中调用apply方法去实现每个子进程要执行的方法apply(method_name, (parameters....))
由于我们想要确保,每次拿到一条url,希望当前进程写入的数据的时候,不被其他进程打扰,我们给写入操作加上进程锁
在写的过程中,我发现如果按照创建一条进程的方法也创建进程锁,会报错,原因是用了进程池,而进程池中的进程并不是由当前同一个父进程创建的原因。
查了下资料,multiprocessing.Manager()返回的manager对象控制了一个server进程,可用于多进程之间的安全通信。
写入文件加锁:
def write_csv_rows(lock, path, headers, rows): # write one row lock.acquire() with open(path, 'a', encoding='gb18030', newline='') as f: f_csv = csv.DictWriter(f, headers) # 如果写入数据为字典,则写入一行,否则写入多行 if type(rows) == type({}): f_csv.writerow(rows) else: f_csv.writerows(rows) lock.release()
这样我们会发现进程池会调用多个进程资源,并执行写入操作,互不干扰,但是这样就遗留下来了问题,总结会提到

接下来拿到数据后,我们读取cvs中的price,分析价格低于200¥的图书的价位分布,为了生成统计图,我们引入matplotlib包
首先处理脏数据:
这里提到一点在基础版忽视的问题,我们发现在读入的数据中,有一部分的图书名字会加上‘团购:’的无用信息,所以我们要在存入磁盘前删掉它
for data in result['Data']: bookinfo['bookName'] = data['book_name'].replace('团购:','') bookinfo['price'] = data['group_price'] bookinfo['iconLink'] = data['group_image'] write_csv_rows(lock, fileName,headers,bookinfo)
接下来就是处理数据的部分了:先拿到cvs文件中price的值,也就是栏位为1
然后遍历删掉title => price后,我们发现在price 的数据中,有的值为'39.9-159.9'格式,对于这种格式的数据,我们求平均值来计算
最后我们把价格低于200的数据存入数组,用于生成柱状图
#matplotlib views, 统计价格小于200的图书价格分布 prices = [] price = read_csv_column(csv_filename, 1) for i in range(len(price)-1): if(price[i+1].find('-') != -1): splitprice = price[i+1].split('-') average_price = (float(splitprice[0]) + float(splitprice[1]))/ 2 if(average_price < 200): prices.append(average_price) elif(float(price[i+1]) < 200): prices.append(float(price[i+1])) plt.hist(prices, bins=10) print(prices) plt.show()
调用show()方法后生成统计图
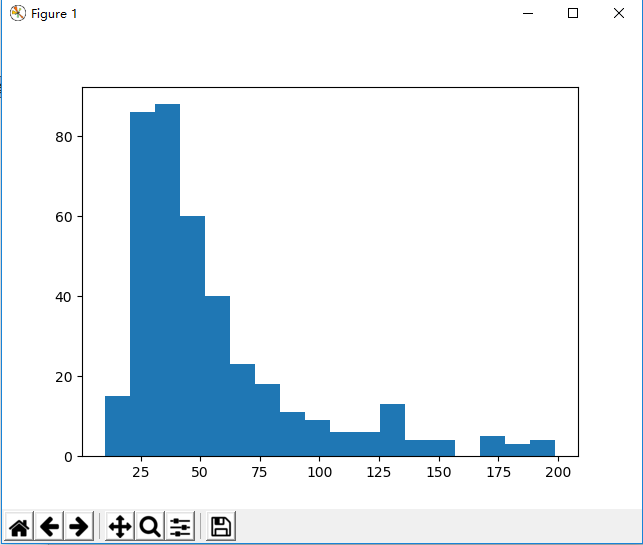
当然matplotlib为我们提供了很多方法去美化,以及生成点状图,线图等等,在这里仅仅是测试功能,自我学习,不多测试了
小实验全部代码:
import requests from bs4 import BeautifulSoup import json import csv import multiprocessing from matplotlib import pyplot as plt def parse_one_page(): header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36', 'Host': 'tuan.bookschina.com', 'Referer': 'http://tuan.bookschina.com/', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9' } url = 'http://tuan.bookschina.com/' response = requests.get(url, headers = header) #模仿浏览器登录 response.encoding = 'utf-8' soup = BeautifulSoup(response.text,'html.parser') for item in soup.select('div .taoListInner ul li'): print(item.select('h2')[0].text) #返回对象为数组 print(item.select('.salePrice')[0].text) print(item.select('img')[0].get('src')) #get方法用来取得tab内部的属性值 def dynamtic_scraping_data(page, headers, fileName): pool = multiprocessing.Pool() #进程池 lock = multiprocessing.Manager().Lock() #加一个写锁,确保每页的内容在一起 ''' if code ' lock = multiprocessing.Lock()'报错: RuntimeError: Lock objects should only be shared between processes through inheritance 用了进程池,而进程池中的进程并不是由当前同一个父进程创建的原因。查了下资料, multiprocessing.Manager()返回的manager对象控制了一个server进程,可用于多进程之间 的安全通信。 ''' for i in range(page): pool.apply_async(scraping_page_data,(lock, i, headers, fileName)) pool.close() pool.join() def scraping_page_data(lock, page, headers, fileName): url = 'http://tuan.bookschina.com/Home/GroupList?Type=0&Category=0&Price=0&Order=11&Page=' + str( page+1) + '&Tyjson=true' response = requests.get(url) result = json.loads(response.text) bookinfo = {} for data in result['Data']: bookinfo['bookName'] = data['book_name'].replace('团购:','') bookinfo['price'] = data['group_price'] bookinfo['iconLink'] = data['group_image'] write_csv_rows(lock, fileName,headers,bookinfo) print(multiprocessing.current_process().name + ' ' + url) def write_csv_headers(path, headers): ''' 写入表头 ''' with open(path, 'a', encoding='gb18030', newline='') as f: f_csv = csv.DictWriter(f, headers) f_csv.writeheader() def write_csv_rows(lock, path, headers, rows): # write one row lock.acquire() with open(path, 'a', encoding='gb18030', newline='') as f: f_csv = csv.DictWriter(f, headers) # 如果写入数据为字典,则写入一行,否则写入多行 if type(rows) == type({}): f_csv.writerow(rows) else: f_csv.writerows(rows) lock.release() def read_csv_column(path, column): # read one row with open(path, 'r', encoding='gb18030', newline='') as f: reader = csv.reader(f) return [row[column] for row in reader] def main(page): # parse_one_page() #Tip: beautifulSoup test csv_filename = "bookInfo.csv" headers = ['bookName', 'price', 'iconLink'] write_csv_headers(csv_filename,headers) dynamtic_scraping_data(page, headers, csv_filename) #matplotlib views, 统计价格小于200的图书价格分布 prices = [] price = read_csv_column(csv_filename, 1) for i in range(len(price)-1): if(price[i+1].find('-') != -1): splitprice = price[i+1].split('-') average_price = (float(splitprice[0]) + float(splitprice[1]))/ 2 if(average_price < 200): prices.append(average_price) elif(float(price[i+1]) < 200): prices.append(float(price[i+1])) plt.hist(prices, bins=18) print(prices) plt.show() if __name__ == '__main__': main(20)
总结:
在测试爬虫程序的过程中,发现了一个非常关键的问题,也就是网络稳定对爬虫程序的影响。如果读取页数相当庞大,在抓取过程中,
会有某个链接出现相应失败的情况,但是本程序默认的操作是跳过继续执行。所以这样就有可能导致数据丢失,以至于分析数据结果
不准确,google后,发现消息队列是一个很好的解决方法,把每次拿到的url存入队列中,每个进程作为消费者去pop队列中的url,如
果拿数据失败,则从新把url指令存入队列,等待重新执行。有机会试着实现一下