文件上传
以人人网上传头像为例,用Fiddler抓取的上传头像接口报文如下
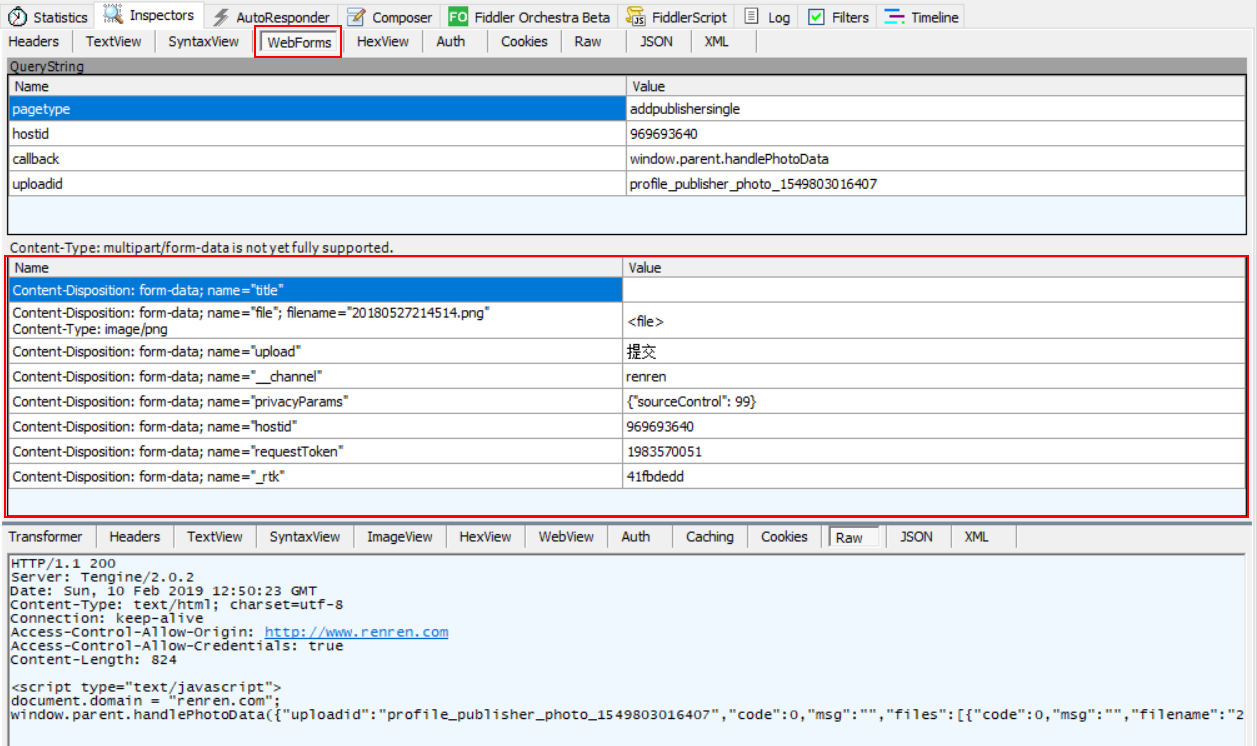
上传头像图片代码:
import requests upload_url = 'http://upload.renren.com/upload.fcgi?pagetype=addpublishersingle&hostid=969693640&callback=window.parent.handlePhotoData&uploadid=profile_publisher_photo_1549803016407' data = { "upload": "提交", "__channel": "renren", "privacyParams": '{"sourceControl": 99}', "hostid": "969693640", "requestToken": "1983570051", "_rtk": "41fbdedd" } files = {'file':('20180527214514.png',open("D:\20180527214514.png","rb"),"image/png")} headers = { "Content-Type": "multipart/form-data", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36", "Cookie": "anonymid=jqaq5unrglqofe; _r01_=1; _de=0A77BBB010E3F31F230189D3D5BDB247; depovince=GW; ick_login=77da0297-4cd5-4b1c-8a27-e5c0c3cd5225; ick=36f73ac4-827f-4c32-a0dc-2bc674f2f101; __utma=151146938.867379497.1546164320.1546164320.1549801247.2; __utmc=151146938; __utmz=151146938.1549801247.2.2.utmcsr=renren.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmb=151146938.10.10.1549801247; t=d61f48b472869e4873c3ce871b8afa490; societyguester=d61f48b472869e4873c3ce871b8afa490; id=969693640; xnsid=288bb964; jebecookies=46621450-73a5-41db-982f-ab36a5170dbb|||||; ver=7.0; loginfrom=null; springskin=set; jebe_key=a5ea1884-792f-4b19-9a89-f60c153512d7%7C96f44a5209ae47155358d1204ba3ec93%7C1549802951410%7C1%7C1549802951375; vip=1; wp_fold=0" } rec = requests.post(url=upload_url,data=data,headers=headers,files=files)
文件下载
方法一:
使用 urllib 模块提供的 urlretrieve() 函数。urlretrieve() 方法直接将远程数据下载到本地。
urlretrieve(url, [filename=None, [reporthook=None, [data=None]]])
说明:
-
参数 finename 指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
-
参数 reporthook 是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
-
参数 data 指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
实例:
from urllib import request load_url = 'http://docs.python-requests.org/zh_CN/latest/_static/requests-sidebar.png' def Schedule(a,b,c): ''' a:已经下载的数据块 b:数据块的大小 c:远程文件的大小 ''' per = 100.0 * a * b / c if per > 100 : per = 100 print('%.2f%%' % per) request.urlretrieve(url=load_url,filename='d:\python.png',reporthook=Schedule)
方法二:
使用requests模块
import requests load_url = 'http://docs.python-requests.org/zh_CN/latest/_static/requests-sidebar.png' rec = requests.get(url=load_url,stream=True) with open("D:\python.png","wb") as f: for chunk in rec.iter_content(chunk_size=1024): f.write(chunk)
-
stream参数默认为False,它会立即开始下载文件并放到内存中,如果文件过大,有可能导致内存不足。
-
stream参数设置成True时,它不会立即开始下载,当你使用iter_content或iter_lines遍历内容或访问内容属性时才开始下载。
-
iter_content:一块一块的遍历要下载的内容
-
iter_lines:一行一行的遍历要下载的内容
使用上面两个函数下载大文件可以防止占用过多的内存,因为每次只下载小部分数据。