RNN:
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入
在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)。
RNN的结构及变体
基础的神经网络包含输入层、隐层、输出层,通过激活函数控制输出,层与层之间通过权值连接。
激活函数是事先确定好的,那么神经网络模型通过训练“学“到的东西就蕴含在“权值“中。
基础的神经网络只在层与层之间建立了权连接,RNN最大的不同之处就是在层之间的神经元之间也建立的权连接。如图。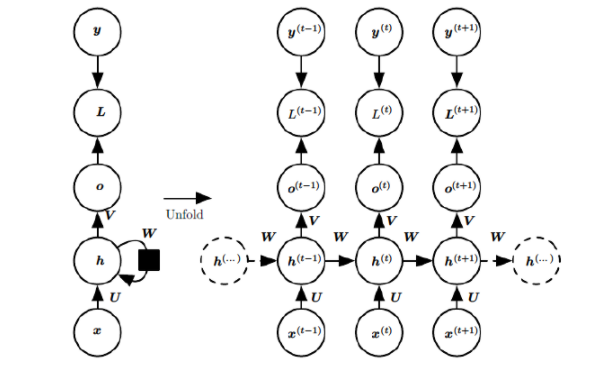
这是一个标准的RNN结构图,图中每个箭头代表做一次变换,也就是说箭头连接带有权值。
左侧是折叠起来的样子,右侧是展开的样子,左侧中h旁边的箭头代表此结构中的“循环“体现在隐层。
在展开结构中我们可以观察到,在标准的RNN结构中,隐层的神经元之间也是带有权值的。
也就是说,随着序列的不断推进,前面的隐层将会影响后面的隐层。
图中O代表输出,y代表样本给出的确定值,L代表损失函数,我们可以看到,“损失“也是随着序列的推荐而不断积累的。
除上述特点之外,标准RNN的还有以下特点:
1、权值共享,图中的W全是相同的,U和V也一样。
2、每一个输入值都只与它本身的那条路线建立权连接,不会和别的神经元连接。
以上是RNN的标准结构,然而在实际中这一种结构并不能解决所有问题.
例如我们输入为一串文字,输出为分类类别,那么输出就不需要一个序列,只需要单个输出。如图。

同样的,我们有时候还需要单输入但是输出为序列的情况。那么就可以使用如下结构:

还有一种结构是输入虽是序列,但不随着序列变化,就可以使用如下结构:
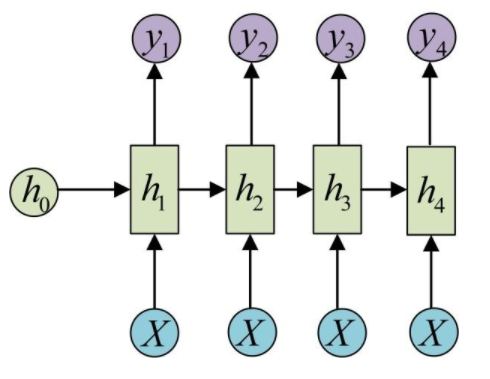
原始的N vs N RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
解决不等长问题:
RNN最重要的一个变种:N vs M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。

这个结构的原理是先编码后解码。左侧的RNN用来编码得到c,拿到c后再用右侧的RNN进行解码。得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
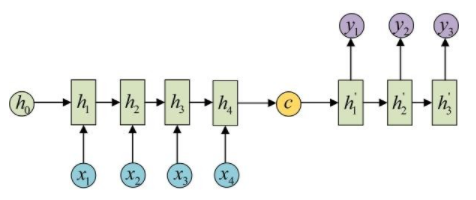
RNN还有很多种结构,用于应对不同的需求和解决不同的问题。
几种不同的结构。但相同的是循环神经网络除了拥有神经网络都有的一些共性元素之外,它总要在一个地方体现出“循环“,而根据“循环“体现方式的不同和输入输出的变化就形成了多种RNN结构。
标准RNN的前向输出流程
标准结构的RNN的前向传播过程

各个符号的含义:x是输入,h是隐层单元,o为输出,L为损失函数,y为训练集的标签。
这些元素右上角带的t代表t时刻的状态,其中需要注意的是,因策单元h在t时刻的表现不仅由此刻的输入决定,还受t时刻之前时刻的影响。
V、W、U是权值,同一类型的权连接权值相同。
具体关于RNN的详细解:(36条消息) RNN_了不起的赵队-CSDN博客_rnn
GNN与RNN
因为图神经网络不论是前向传播的方式,还是反向传播的优化算法,与循环神经网络都有点相像。
实际上,图神经网络与到循环神经网络很相似。为了清楚地显示出它们之间的不同,我们用一张图片来解释这两者设计上的不同:
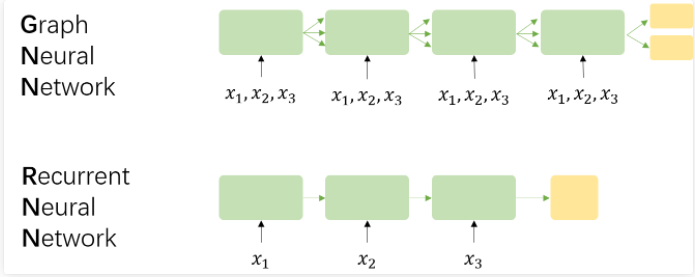
假设在GNN中存在三个结点x1,x2,x3,相应地,在RNN中有一个序列(x1,x2,x3)。
笔者认为,GNN与RNN的区别主要在于4点:

不过鉴于初代GNN与RNN结构上的相似性,一些文章中也喜欢把它称之为 Recurrent-based GNN,也有一些文章会把它归纳到 Recurrent-based GCN中。
GNN的局限
初代GNN,也就是基于循环结构的图神经网络的核心是不动点理论。
它的核心观点是通过结点信息的传播使整张图达到收敛,在其基础上再进行预测。
收敛作为GNN的内核,同样局限了其更广泛的使用,其中最突出的是两个问题:

Over Smooth
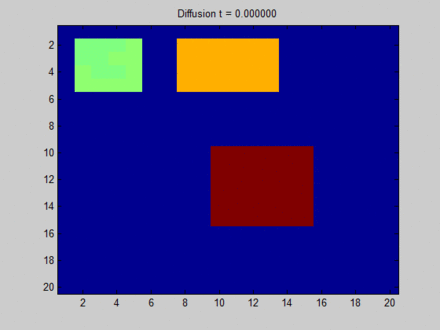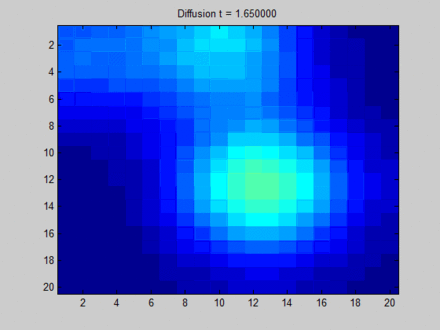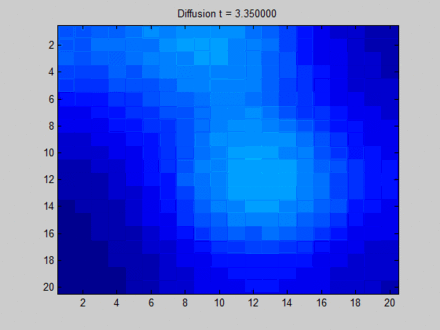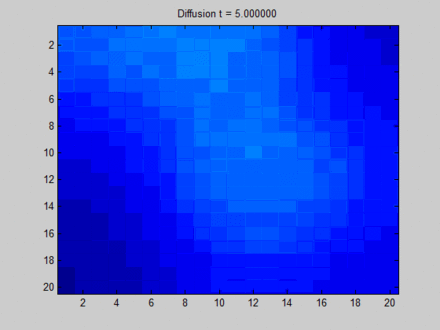
其中我们把整个布局视作一张图,每个像素点与其上下左右以及斜上下左右8个像素点相邻,这决定了信息在图上的流动路径。
初始时,
蓝色表示没有信息量,如果用向量的概念表达即为空向量;
绿色,黄色与红色各自有一部分信息量,表达为非空的特征向量。
在图上,信息主要从三块有明显特征的区域向其邻接的像素点流动。
一开始不同像素点的区分非常明显,但在向不动点过渡的过程中,所有像素点都取向一致,最终整个系统形成均匀分布。这样,虽然每个像素点都感知到了全局的信息,但我们无法根据它们最终的隐藏状态区分它们。比如说,根据最终的状态,我们是无法得知哪些像素点最开始时在绿色区域。
事实上,上面这个图与GNN中的信息流动并不完全等价。
从笔者来看,如果我们用物理模型来描述它,上面这个图代表的是初始时有3个热源在散发热量,而后就让它们自由演化;
但实际上,GNN在每个时间步都会将结点的特征作为输入来更新隐藏状态,这就好像是放置了若干个永远不灭的热源,热源之间会有互相干扰,但最终不会完全一致。
门控图神经网络(Gated Graph Neural Network)#
我们上面细致比较了GNN与RNN,可以发现它们有诸多相通之处。
直接用类似RNN的方法来定义GNN:
于是,门控图神经网络(Gated Graph Neural Network, GGNN) 就出现了。
虽然在这里它们看起来类似,但实际上,它们的区别非常大,其中最核心的不同即是门控神经网络不以不动点理论为基础。
这意味着:
f 不再需要是一个压缩映射;迭代不需要到收敛才能输出,可以迭代固定步长;
优化算法也从 AP 算法转向 BPTT
GGNN状态更新
与图神经网络定义的范式一致,GGNN也有两个过程:状态更新与输出。
相比GNN而言,它主要的区别来源于状态更新阶段。
具体地,GGNN参考了GRU的设计,把邻居结点的信息视作输入,结点本身的状态视作隐藏状态,其状态更新函数如下:

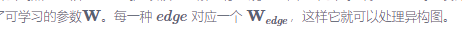
对比GNN的GGNN的状态更新公式,
发现:在GNN里需要作为输入的结点特征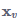
没有出现在GGNN的公式中!
但实际上,这些结点特征对我们的预测至关重要,因为它才是各个结点的根本所在。
为了处理这个问题,GGNN将结点特征作为隐藏状态初始化的一部分。
先回顾一下GGNN的流程,其实就是这样:

GGNN实例1:到达判断#
比如说给定一张图G,开始结点 S,对于任意一个结点 E,模型判断开始结点是否可以通过图游走至该结点。
同样地,这也可以转换成一个对结点的二分类问题,即可以到达和不能到达。
下图即描述了这样的过程:
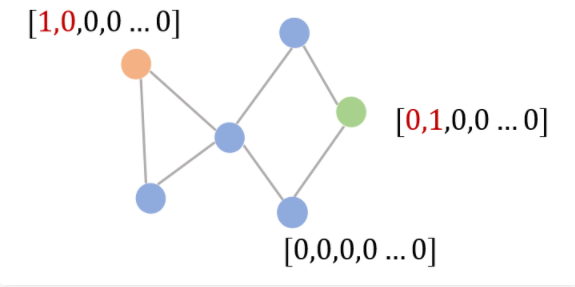
图中的红色结点即开始结点S,绿色结点是我们希望判断的结点E,我们这里称其为结束结点。
那么相比于其他结点,这两个结点具有一定特殊性。
那我们就可以使用第1维为1来表示开始结点,第2维为1来表示结束结点。
最后在对结束结点分类时,如果其隐藏状态的第1维被赋予得到了一个非0的实数值,那意味着它可以到达。
从初始化的流程我们也可以看出GNN与GGNN的区别:
GNN依赖于不动点理论,所以每个结点的隐藏状态即使使用随机初始化都会收敛到不动点;
GGNN则不同,不同的初始化对GGNN最终的结果影响很大。
GGNN实例2:语义解析
语义解析的主要任务是将自然语言转换成机器语言,在这里笔者特指的是SQL(结构化查询语言,Structured Query Language),它就是大家所熟知的数据库查询语言。
任务:可以让小白用户也能从数据库中获得自己关心的数据。正是因为有了语义解析,用户不再需要学习SQL语言的语法,也不需要有编程基础,可以直接通过自然语言来查询数据库。
事实上,语义解析放到今天仍然是一个非常难的任务。除去自然语言与程序语言在语义表达上的差距外,很大一部分性能上的损失是因为任务本身,或者叫SQL语言的语法太复杂。比如我们有两张表格,一张是学生的学号与其性别,另一张表格记录了每个学生选修的课程。那如果想知道有多少女生选修了某门课程,我们需要先将两张表格联合(JOIN),再对结果进行过滤(WHERE),最后进行聚合统计(COUNT)。这个问题在多表的场景中尤为突出,每张表格互相之间通过外键相互关联。
其实呢,如果我们把表格中的Header看作各个结点,表格内的结点之间存在联系,而外键可以视作一种特殊的边,这样就可以构成一张图,正如下图中部所示:
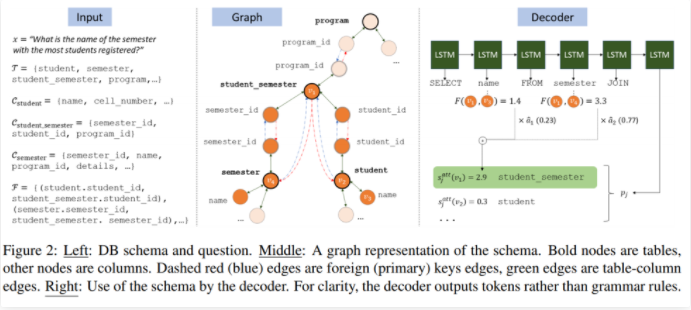
论文[11]就是利用了表格这样的特性,利用GGNN来解决多表问题。
先看一般的语义解析方法,再介绍[11]是如何将图跟语义解析系统联系在一起的。
目前绝大部分语义解析会遵循Seq2seq(序列到序列,Sequence to sequence)的框架,输入是一个个自然语言单词,输出是一个个SQL单词。但这样的框架完全没有考虑到表格对SQL输出暗含的约束。
比如说,在单个SELECT子句中,我们选择的若干Header都要来自同一张表。
再举个例子,能够JOIN的两张表一定存在外键的联系,就像我们刚刚举的那个学生选课的例子一样。
GGN结合到传统的语义解析方法中的三步:

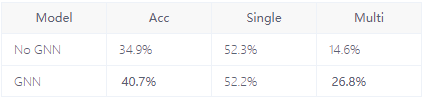
最终该论文在多表上的效果也确实很好,下面放一个在Spider[12]数据集上的性能对比:
GNN与GGNN#
GGNN目前得到了广泛的应用,相比于GNN,其最大的区别在于不再以不动点理论为基础。
虽然这意味着不再需要迭代收敛,但同时它也意味着GGNN的初始化很重要。
GNN后的大部分工作都转向了将GNN向传统的RNN/CNN靠拢,可能的一大好处是这样可以不断吸收来自这两个研究领域的改进。
但基于原始GNN的基于不动点理论的工作非常少,至少在看文献综述的时候并未发现很相关的工作。
但从另一个角度来看,虽然GNN与GGNN的理论不同,
但从设计哲学上来看,它们都与循环神经网络的设计类似。
- 循环神经网络的好处在于能够处理任意长的序列,但它的计算必须是串行计算若干个时间步,时间开销不可忽略。所以,上面两种基于循环的图神经网络在更新隐藏状态时不太高效。如果借鉴深度学习中堆叠多层的成功经验,我们有足够的理由相信,多层图神经网络能达到同样的效果。
- 基于循环的图神经网络每次迭代时都共享同样的参数,而多层神经网络每一层的参数不同,可以看成是一个层次化特征抽取(Hierarchical Feature Extraction)的方法。
而在下一篇博客中,我们将介绍图卷积神经网络。它摆脱了基于循环的方法,开始走向多层图神经网络。在多层神经网络中,卷积神经网络(比如152层的ResNet)的大获成功又验证了其在堆叠多层上训练的有效性,所以近几年图卷积神经网络成为研究热点。
整篇文章参考博客:
从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (一) - SivilTaram - 博客园 (cnblogs.com)