简述
JDK1.8开始,引入了一个全新的流式Stream API,它位于java.util.stream包中,StreamAPI用于帮我们更方便地操作集合,他的本质就是对数据的操作进行流水线式处理,也可以理解为一个更加高级的迭代器,主要的作用便是遍历其中每一个元素。
Stream的特点
和list等容器不同,Stream代表的是任意Java对象的序列,且stream输出的元素可能并没有预先存储在内存中,而是实时计算出来的。它可以“存储”有限个或无限个元素。
例如我们要表示一个全体自然数的集合,用List是不可能写出来的,因为自然数是无限的,内存再大也没法放到List中,但我们可以用stream做到
Stream<BigInteger> naturals = createNaturalStream(); // 全体自然数我们不考虑这个方法是如何实现的,我们只需关心现在这些自然数没有实时存在内存里,我们可以对这个自然数流进行平方、加减等操作,等我们需要部分有限的数据时,再通过API获得,也就是说真正的计算发生在流的最后。、
创建Stream
Stream.of
Stream.of静态方法可以直接手动生成一个stream
Stream<String> stream = Stream.of("A", "B", "C", "D");很简单,不过也没什么实际用途
基于数组或Collection
把数组变成stream使用Arrays.stream()方法。对于Collection(List、Set、Queue等),直接调用stream()方法就可以获得stream。
Stream<String> stream1 = Arrays.stream(new String[] { "A", "B", "C" });
Stream<String> stream2 = List.of("X", "Y", "Z").stream();supplier基于Supplier
Supplier创建的Stream会不断调用Supplier.get()方法来不断产生下一个元素,这种Stream保存的不是元素,而是算法,它可以用来表示无限序列。例如我们可以用supplier来创建一个自然数streampublic class Main { public static void main(String[] args) { Stream<Integer> natual = Stream.generate(new NatualSupplier());//自然数stream } } class NatualSupplier implements Supplier<Integer> { int n = 0; public Integer get() { n++; return n; } }
其他方法
我们可以通过一些API提供的接口,直接获得Stream
例如Files类的lines()方法可以把一个文件变成一个Stream,每个元素代表文件的一行内容
Stream<String> lines = Files.lines(Paths.get("/path/to/file.txt"))
正则表达式的Pattern对象有一个splitAsStream()方法,可以直接把一个长字符串分割成Stream序列而不是数组
Pattern p = Pattern.compile("\\s+");
Stream<String> s = p.splitAsStream("The quick brown fox jumps over the lazy dog");
s.forEach(System.out::println);
Map映射
Stream.map()是Stream最常用的一个转换方法,它把一个Stream转换为另一个Stream
本质上就是将stream流里的每一个元素进行一个函数映射,如何映射由我们定义
例如我们可以将stream里面的数字做个平方
Stream<Integer> s = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> s2 = s.map(n -> n * n);
map方法里面接收的是Function接口对象
@FunctionalInterface public interface Function<T, R> { // 将T类型转换为R: R apply(T t); }
filter过滤
所谓filter()操作,就是对一个Stream的所有元素一一进行测试,不满足条件的就被“滤掉”了,剩下的满足条件的元素就构成了一个新的Stream
注意只有filter里的表达式为真的元素才可以通过这个"滤网",例如我们可以将1到10的偶数过滤掉
public class Main { public static void main(String[] args) { IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9,10) .filter(n -> n % 2 != 0) .forEach(System.out::println); } }
reduce聚合
map()和filter()都是Stream的转换方法,而Stream.reduce()则是Stream的一个聚合方法,它可以把一个Stream的所有元素按照聚合函数聚合成一个结果,例如我们可以将1到9的自然数求和
import java.util.stream.Stream; public class Main { public static void main(String[] args) { int sum = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(0, (acc, x) -> acc + x); System.out.println(sum); // 45 } }
这里的0就是求和的数的初始值,acc代表每一步的求和中间值,写成这样会更好理解
Stream<Integer> stream = ... int sum = 0; for (x : stream) { sum = (sum, n) -> sum + x; }
除了求和我们还可以进行字符串拼接,数字求积等,注意求积时初始值要为1
其他操作
排序
对Stream的元素进行排序十分简单,只需调用sorted()方法
List<String> list = List.of("Orange", "apple", "Banana")
.stream()
.sorted()
.collect(Collectors.toList());
方法要求Stream的每个元素必须实现Comparable接口。如果要自定义排序,传入指定的Comparator即可
List<String> list = List.of("Orange", "apple", "Banana")
.stream()
.sorted(String::compareToIgnoreCase)
.collect(Collectors.toList());
去重
使用distinct
List.of("A", "B", "A", "C", "B", "D")
.stream()
.distinct()
.collect(Collectors.toList()); // [A, B, C, D]
截取
截取操作常用于把一个无限的Stream转换成有限的Stream,skip()用于跳过当前Stream的前N个元素,limit()用于截取当前Stream最多前N个元素
List.of("A", "B", "C", "D", "E", "F")
.stream()
.skip(2) // 跳过A, B
.limit(3) // 截取C, D, E
.collect(Collectors.toList()); // [C, D, E]
合并
将两个Stream合并为一个Stream可以使用Stream的静态方法concat()
Stream<String> s1 = List.of("A", "B", "C").stream();
Stream<String> s2 = List.of("D", "E").stream();
// 合并:
Stream<String> s = Stream.concat(s1, s2);
System.out.println(s.collect(Collectors.toList())); // [A, B, C, D, E]
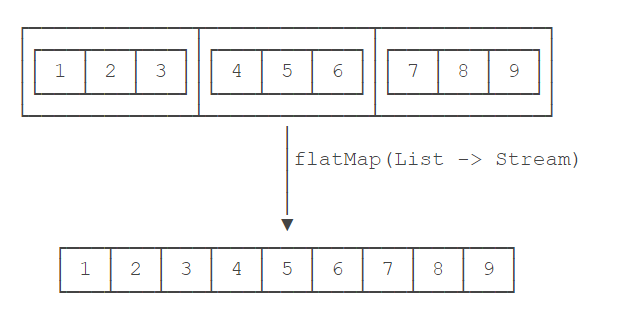
flatMap
如果Stream的元素是集合
Stream<List<Integer>> s = Stream.of( Arrays.asList(1, 2, 3), Arrays.asList(4, 5, 6), Arrays.asList(7, 8, 9));
而我们希望把Stream转换为Stream<Integer>,就可以使用flatMap()
Stream<Integer> i = s.flatMap(list -> list.stream());
并行
通常情况下,对Stream的元素进行处理是单线程的,即一个一个元素进行处理。但是很多时候,我们希望可以并行处理Stream的元素,因为在元素数量非常大的情况,并行处理可以大大加快处理速度。
一个普通Stream转换为可以并行处理的Stream非常简单,只需要用parallel()进行转换
经过parallel()转换后的Stream只要可能,就会对后续操作进行并行处理。我们不需要编写任何多线程代码就可以享受到并行处理带来的执行效率的提升。
Stream<String> s = ... String[] result = s.parallel() // 变成一个可以并行处理的Stream
forEach()
forEach()可以循环处理Stream的每个元素,我们经常传入System.out::println来打印Stream的元素
Stream<String> s = ... s.forEach(str -> { System.out.println("Hello, " + str); });
其他聚合方法
min求最小值,max求最大值
count求stream的元素个数、
sum对stream所有元素求和
average对stream所有元素求平均值
boolean allMatch(Predicate<? super T>)测试是否所有元素均满足测试条件
boolean anyMatch(Predicate<? super T>)测试是否至少有一个元素满足测试条件
流的输出
对于流转换操作来说,流的转换不会触发任何的计算,而只有像reduce一样的聚合操作会触发整条流的计算
输出到集合
以List为例,把Stream的每个元素收集到List的方法是调用collect()并传入Collectors.toList()对象,它实际上是一个Collector实例,通过类似reduce()的操作,把每个元素添加到一个收集器中
Stream<String> stream = Stream.of("Apple","Pear","Orange");
List<String> list = stream.collect(Collectors.toList());
类似的,collect(Collectors.toSet())可以把Stream的每个元素收集到Set中
输出到数组
把Stream的元素输出为数组和输出为List类似,我们只需要调用toArray()方法,并传入数组的“构造方法”
List<String> list = List.of("Apple", "Banana", "Orange");
String[] array = list.stream().toArray(String[]::new);
注意到传入的“构造方法”是String[]::new,它的签名实际上是IntFunction<String[]>定义的String[] apply(int),即传入int参数,获得String[]数组的返回值
输出为Map
stream里面的元素是单个的,map需要key和value,所以我们要在输出的时候把元素映射成key和value存入map
这里我们把元素以:为切割点,前面为key,后面为value
Stream<String> stream = Stream.of("APPL:Apple", "MSFT:Microsoft");
Map<String, String> map = stream
.collect(Collectors.toMap(
// 把元素s映射为key:
s -> s.substring(0, s.indexOf(':')),
// 把元素s映射为value:
s -> s.substring(s.indexOf(':') + 1)));
分组输出
我们可以将stream里的元素按照我们指定的分组规则进行分组,这里我们按照字符串的首字母进行分组,相同的为一组
List<String> list = List.of("Apple", "Banana", "Blackberry", "Coconut", "Avocado", "Cherry", "Apricots");
Map<String, List<String>> groups = list.stream()
.collect(Collectors.groupingBy(s -> s.substring(0, 1), Collectors.toList()));
分组输出使用Collectors.groupingBy(),它需要提供两个函数:一个是分组的key,这里使用s -> s.substring(0, 1),表示只要首字母相同的String分到一组,第二个是分组的value,这里直接使用Collectors.toList(),表示输出为List
假设我们有一个学生类,包含学生姓名、班级和成绩
class Student { int gradeId; // 年级 int classId; // 班级 String name; // 名字 int score; // 分数 }
如果现在有一个Stream<Student>,利用分组输出,我们可以很简单地将学生按照年级归类
Stream<Student> studentStream = Stream.of( new Student(1,1,"xiaoming",100), new Student(1,2,"xiaozhang",99), new Student(2,1,"xiaoming",58), new Student(2,3,"xiaoming",68) ); Map<Integer, List<Student>> groups = studentStream.collect(Collectors.groupingBy(s -> s.getGradeId(),Collectors.toList()));
Reference
https://www.liaoxuefeng.com/wiki/1252599548343744
https://blog.csdn.net/m0_60489526/article/details/119984236