引言
介绍
- 目前精度高的检测器都是基于two-stage,proposal-driven机制,第一阶段生成稀疏的候选对象位置集,第二阶段使用CNN进一步将每个候选位置分为前景或者背景以及确定其类别;
- 提出一个one-stage检测器可以匹配two-stage检测器在COCO上AP,例如FPN、Mask R-CNN,为了到达这一结果针对训练过程中类别不平衡这个阻碍问题,设计出一个新的loss,focal loss;
- R-CNN类检测器可以通过two-stage级联和启发式采用来解决class imbalance问题,proposal stage包括:Selective Search、EdgeBoxes、DeepMask、RPN,可以迅速候选区域数目降低过滤大量background样本;在第二个分类stage启发式采样,可以采取的策略有:固定前景和背景的比例1:3或者采用OHEM在线困难样本挖掘,可以用来维持前景和背景样本可操作性平衡;
- one stage检测器需要处理更大的候选位置集,虽然也应用了同样的启发式采样,但是效率低下因为在训练过程中很容易受到简单背景样本的支配;这种低效率问题是目标检测的典型问题,对此典型的解决方法是bootstrapping、HEM;
- focal loss是一个能够动态缩放的cross entropy loss,当正确类别的置信度提高时缩放因子衰减为0,缩放因子可以自动降低easy例子在训练期间贡献loss的权重,使得模型注重hard例子;
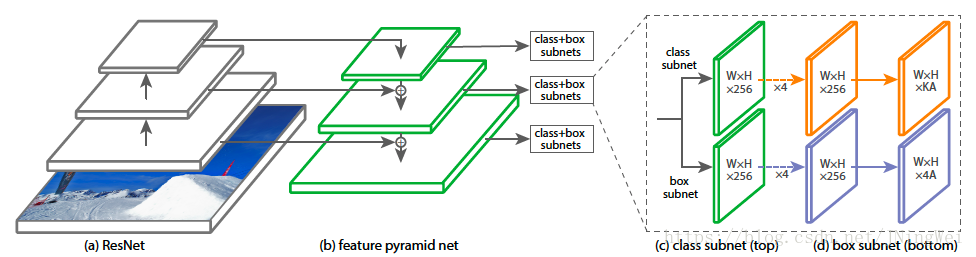
- 为了验证focal loss的有效性设计了一种one-stage的目标检测器RetinaNet,它的设计利用了高效的网络特征金字塔以及采用了anchor boxes,表现最好的RetinaNet结构是以ResNet-101-FPN为bakcbone,在COCO测试集能达到39.1的AP,速度为5fps;
创新点
1、Focal Loss:

2、RetinaNet:
为了评估focal loss的有效性,设计和训练出了RetinaNet,在使用focal loss对RetinaNet进行训练时可以匹配之前的one-stage的方法,同时在精度上超过了目前所有的two-stage检测器