https://zhuanlan.zhihu.com/p/37290775
https://github.com/NELSONZHAO/zhihu/blob/master/mt_attention_birnn/mt_attention_birnn.ipynb
Seq2Seq架构:
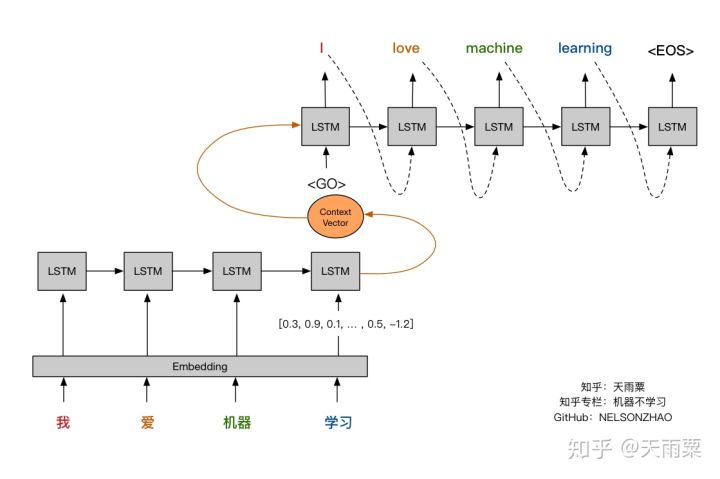
通过Encoder将输入语句进行编码得到固定长度的Context Vector向量,这个编码过程实际上是一个信息有损压缩的过程;随后再将Context Vector传给Decoder进行翻译结果的生成,在Decoder端生成每个单词时,均参考来自Encoder端相同的Context Vector,如下图所示。
引入Attention机制,给予当前待翻译的词更多的权重,使得我们翻译每个词时会对源语句有不同的侧重,如下图所示。
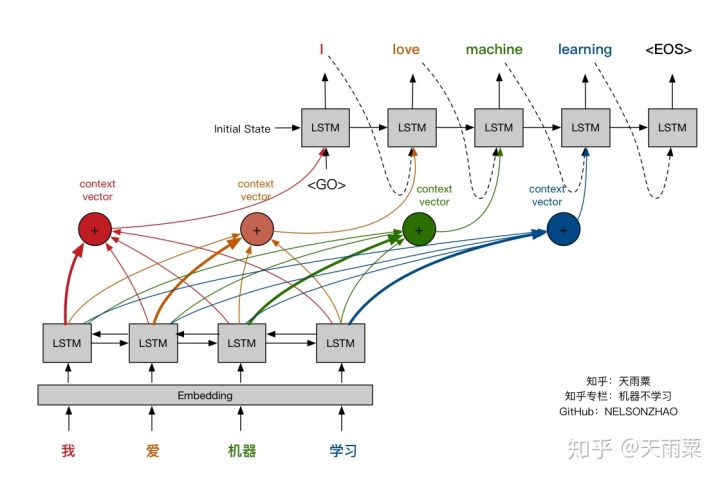
BiRNN正如其名字所说——双向RNN,意思是我们不仅考虑句子的正向序列,还要考虑反向序列,以此让模型捕获句子的完整信息。
本篇文章以Keras作为框架,在Seq2Seq基础模型上加入Attention机制与BiRNN,以英法平行语料为训练数据,构建翻译模型并采用BLEU对模型结果进行评估。
1.Attention层
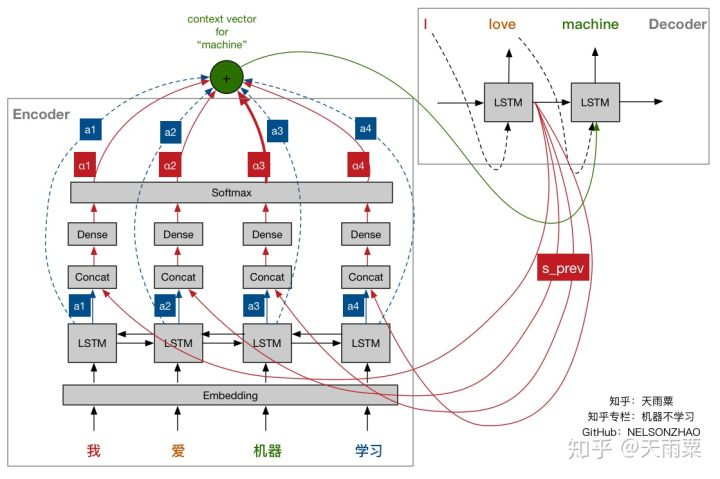
以“我爱机器学习”为例,假如我们当前时刻准备生成“machine”这个词,此时我们需要计算Context Vector。
我们对图中的符号先进行定义:
- s_prev代表Decoder端前一轮的隐层状态,即代表了翻译“love”阶段的输出隐层状态;
- 蓝色框图中的a1-a4分别代表了Encoder端每个输入词BiRNN隐层状态。例如,a1代表了“我”这个词经过Bi-LSTM后的输出向量;
- 红色α1-α4分别代表了Attention机制学习到的权重。例如α3代表了“机器”这个词的权重,可以看到α3对应的线条比较粗,意味着在翻译生成“machine”这个词时对应的Context Vector会给予“机器”这个词更多的Attention;
- 绿色的圈圈代表加权后的Context Vector。
Attention中权重α是关于a和s_prev的函数,我们首先将Bi-LSTM的隐层状态a和s_prev进行concat;然后利用全连接层并采用Softmax激活函数训练一个小的神经网络,得到输出α。进而再利用得到的权重α对Bi-LSTM的隐层状态a进行加权求和,得到当前翻译“machine”的Context Vector,最后将这个Context Vector输入给Decoder进行处理。对翻译的每个词我们都可以采用同样的方式进行构造。

2.Embedding层
采用Glove预训练好的100维词向量作为Embedding层,加载进模型。
3.模型构建
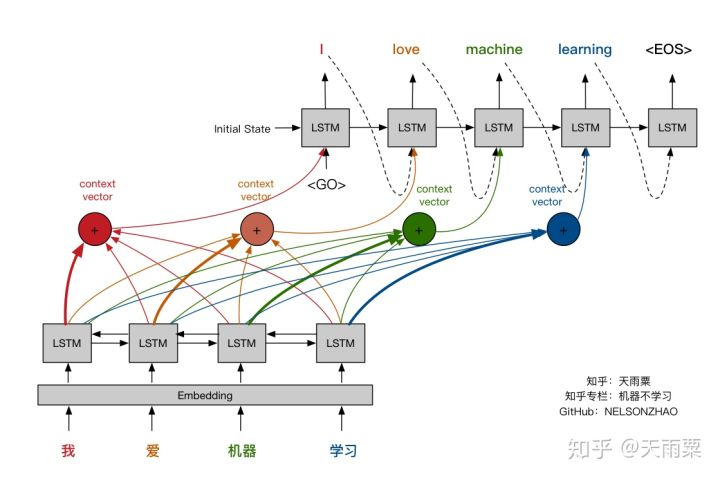
在Encoder端,对输入句子进行学习,求得当前的Context Vector,并将其传递给Decoder处理;在Decoder端,以t-1的输出和当前Context Vector作为LSTM输入,翻译得到结果。
