1.什么是过拟合?
过拟合(overfitting)是指在模型参数拟合过程中的问题,由于训练数据包含抽样误差,训练时,复杂的模型将抽样误差也考虑在内,将抽样误差也进行了很好的拟合。
具体表现就是最终模型在训练集上效果好;在测试集上效果差。模型泛化能力弱。
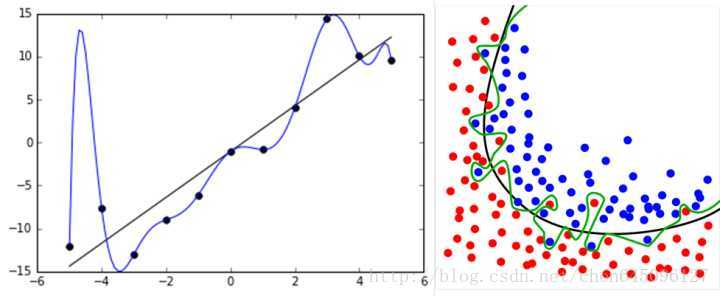
2、产生过拟合根本原因:
(1)观察值与真实值存在偏差
训练样本的获取,本身就是一种 抽样。抽样操作就会存在误差, 也就是你的训练样本 取值 X, X = x(真值) + u(随机误差),机器学习的 优化函数 多为 min Cost函数,自然就是尽可能的拟合 X,而不是真实的x,所以 就称为过拟合了,实际上是学习到了真实规律以外的 随机误差。举个例子说,你想做人脸识别,人脸里有背景吧,要是你这批人脸背景A都相似,学出来的模型,见到背景A,就会认为是人脸。这个背景A就是你样本引入的误差。
(2)训练数据不足,数据太少,导致无法描述问题的真实分布
举个例子,投硬币问题 是一个 二项分布,但是如果 你碰巧投了10次,都是正面。那么你根据这个数据学习,是无法揭示这个规律的,根据统计学的大数定律(通俗地说,这个定理就是,在试验不变的条件下,重复试验多次,随机事件的频率近似于它的概率),当样本多了,这个真实规律是必然出现的。
为什么说 数据量大了以后 就能防止过拟合,数据量大了,
问题2,不再存在,
问题1,在求解的时候因为数据量大了, 求解min Cost函数时候, 模型为了求解到最小值过程中,需要兼顾真实数据拟合 和 随机误差拟合,所有样本的真实分布是相同的(都是人脸),而随机误差会一定程度上抵消(背景),
另外:维度灾难与过拟合请移步:https://www.cnblogs.com/CJT-blog/p/10422923.html
(3)数据有噪声(类似(1))
我们可以理解地简单些:有噪音时,更复杂的模型会尽量去覆盖噪音点,即对数据过拟合。这样,即使训练误差Ein 很小(接近于零),由于没有描绘真实的数据趋势,Eout 反而会更大。
即噪音严重误导了我们的假设。还有一种情况,如果数据是由我们不知道的某个非常非常复杂的模型产生的,实际上有限的数据很难去“代表”这个复杂模型曲线。我们采用不恰当的假设去尽量拟合这些数据,效果一样会很差,因为部分数据对于我们不恰当的复杂假设就像是“噪音”,误导我们进行过拟合。
如下面的例子,假设数据是由50次幂的曲线产生的(下图右边),与其通过10次幂的假设曲线去拟合它们,还不如采用简单的2次幂曲线来描绘它的趋势。

(4)训练模型过度,导致模型非常复杂
有点像原因(3),模型强大到连噪声都学会了。
3、抑制过拟合的几种方法
(1)数据处理:清洗数据、减少特征维度、类别平衡;
1、清洗数据:纠正错误的label,或者删除错误数据
2、降维:
维数约减(移步:https://www.cnblogs.com/CJT-blog/p/10253853.html)
特征选择(移步:https://www.cnblogs.com/CJT-blog/p/10286574.html)
3、类别平衡:
请移步:https://www.cnblogs.com/CJT-blog/p/10223157.html
(2)辅助分类节点(auxiliary classifiers)
在Google Inception V1中,采用了辅助分类节点的策略,即将中间某一层的输出用作分类,并按一个较小的权重加到最终的分类结果中,这样相当于做了模型的融合,同时给网络增加了反向传播的梯度信号,提供了额外的正则化的思想.
(3)正则化:
获取更多数据:从数据源获得更多数据,或数据增强;
L2、L1、BN层等;
使用合适的模型(减少网络的层数、神经元个数等,限制权重过大),限制网络的拟合能力,避免模型过于复杂;
增加噪声:输入时+权重上(高斯初始化);
多种模型结合:集成学习的思想;
Dropout:随机从网络中去掉一部分隐神经元;
限制训练时间、次数,及早停止
········
详细请移步:https://www.cnblogs.com/CJT-blog/p/10424060.html
4、欠拟合
现象:训练的模型在训练集上面的表现很差,在验证集上面的表现也很差。
原因:模型发生欠拟合的最本质原因是“训练的模型太简单,最通用的特征模型都没有学习到”;
措施:
方案1:做特征工程,添加更多的特征项。即提供的特征不能表示出那个需要的函数;
方案2:减少正则化参数。即使得模型复杂一些;
方案3:使用更深或者更宽的模型。
方案4:使用集成方法。融合几个具有差异的弱模型,使其成为一个强模型;
参考资料:
https://www.cnblogs.com/eilearn/p/9203186.html
https://blog.csdn.net/u012457308/article/details/79577340
https://blog.csdn.net/taoyanqi8932/article/details/71101699
https://blog.csdn.net/liuy9803/article/details/81611402
https://blog.csdn.net/chen645096127/article/details/78990928