str本质
Python str的本质可以通过help命令查看
>>> help(str)
可以看到
Help on class str in module __builtin__:
class str(basestring)
| str(object='') -> string
|
| Return a nice string representation of the object.
| If the argument is a string, the return value is the same object.
|
| Method resolution order:
| str
| basestring
| object
|
| Methods defined here:
......
str的本质是Python模块__builtin__中的一个类,里面定义了很多的方法。
str特性
Python strings是不能改变的,字符串的值是固定的。因此,给一个字符串的具体下表位置赋值是会出错的:
>>> word='Python'
>>> word[0] = 'J'
...
TypeError: 'str' object does not support item assignment
>>> word[2:] = 'py'
...
TypeError: 'str' object does not support item assignment
如果要得到一个不同的字符串,那就得创建一个新的:
>>> 'J' + word[1:]
'Jython'
>>> word[:2] + 'py'
'Pypy'
可以使用模块__builtin__中的一个內建函数len()获得字符串的长度:
>>> help(len)
Help on built-in function len in module __builtin__:
len(...)
len(object) -> integer
Return the number of items of a sequence or collection.
>>> s = 'supercalifragilisticexpialidocious'
>>> len(s)
34
字符串是可迭代对象
>>> s = 'I love Python'
>>> list(s)
['I', ' ', 'l', 'o', 'v', 'e', ' ', 'P', 'y', 't', 'h', 'o', 'n']
>>> for c in s:
... print(c)
...
I
l
o
v
e
P
y
t
h
o
n
>>>
str method
以下函数均为str类里面的成员函数按照功能分类的结果
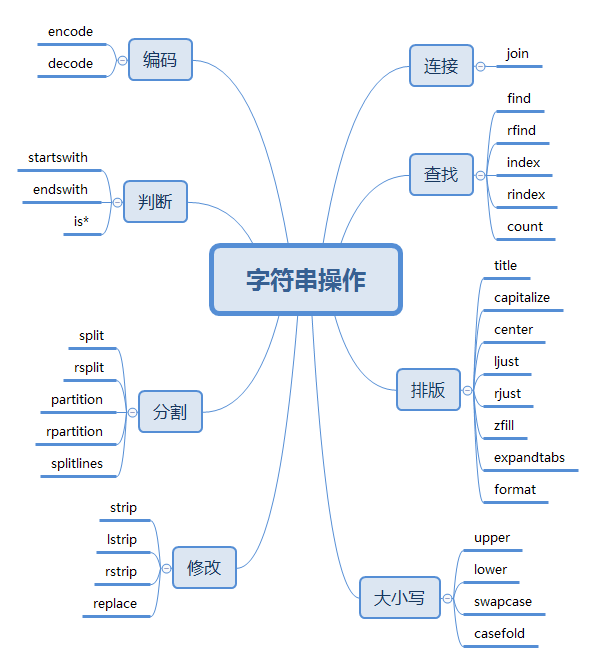
xmind文件可点这里下载
连接
str.join(iterable)
S.join(iterable) -> string
函数功能
将序列iterable中的元素以指定的字符S连接生成一个新的字符串。
函数示例
>>> iter="apple"
>>> s="-"
>>> s.join(iter)
'a-p-p-l-e'
查找
str.find(sub[, start[, end]])
S.find(sub [,start [,end]]) -> int
函数功能
和C++的字符串的find函数功能一样。检测字符串中是否存在子字符串sub,如果存在,则返回找到的第一个子串的下标,如果找不到,则返回-1,而C++返回的是string::nops。
函数示例
>>> s="this is my dog, i love this dog and it's a good dog!"
>>> s.find("dog")
11
>>> s.find("dog",12,len(s)-1)
28
>>> s.find("dog",12,20)
-1
str.rfind(sub[, start[, end]])
S.rfind(sub [,start [,end]]) -> int
函数功能
和C++的字符串的find函数功能一样。检测字符串中是否存在子字符串sub,如果存在,则返回找到的最后一个子串的下标,如果找不到,则返回-1,而C++返回的是string::nops。
函数示例
>>> s="this is my dog, i love this dog and it's a good dog!"
>>> s.rfind("dog")
48
>>> s.rfind("dog",0,len(s)-10)
28
str.index(sub[, start[, end]])
S.index(sub [,start [,end]]) -> int
函数功能
与 python find()方法的功能一样,只不过如果子串sub不在S中会报一个异常(ValueError: substring not found)。
函数示例
>>> s="this is my dog, i love this dog and it's a good dog!"
>>> s.index("dog")
11
>>> s.index("digw")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
str.rindex(sub[, start[, end]])
S.rindex(sub [,start [,end]]) -> int
函数功能
与 python rfind()方法的功能一样,只不过如果子串sub不在S中会报一个异常(ValueError: substring not found)。
函数示例
>>> s="this is my dog, i love this dog and it's a good dog!"
>>> s.rindex("dog")
48
>>> s.rfind("dog")
48
>>> s.rindex("oihofa")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
str.count(sub[, start[, end]])
S.count(sub[, start[, end]]) -> int
函数功能
在字符串中查找某个子串出现的次数。start和end是两个可选的参数,表示起止下标位置。python默认下标位置是从0开始的。
函数示例
>>> s="this is my dog, i love this dog and it's a good dog!"
>>> print s
this is my dog, i love this dog and it's a good dog!
>>> s.count("dog")
3
>>> s.count(" ")
12
>>> s.count("dog",15)
2
>>> s.count("dog",15,32)
1
排版
str.capitalize()
S.capitalize() -> string
- Return a copy of the string S with only its first character capitalized.
函数功能
首字符是字母,返回第一个字母大写,其他不变
函数示例
>>> s='linux'
>>> s.capitalize()
'Linux'
>>> s='790873linux'
>>> s.capitalize()
'790873linux'
str.center(width[, fillchar])
S.center(width[, fillchar]) -> string
函数功能
已字符串S为中心,返回width长度的字符串,其中多余部分都是用fillchar来填充。如果width小于或者等于len(S),则返回str本身。如果不给定fillchar这个参数,那么默认填充空格
函数示例
>>> s='linux'
>>> a=s.center(len(s)+1,'m')
>>> print a
linuxm
>>> a=s.center(len(s)+2,'m')
>>> print a
mlinuxm
>>> a=s.center(len(s)+3,'m')
>>> print a
mlinuxmm
>>> a=s.center(len(s)+4,'m')
>>> print a
mmlinuxmm
>>> a=s.center(len(s)-1,'m')
>>> print a
linux
str.ljust(width[, fillchar])
S.ljust(width[, fillchar]) -> string
函数功能
返回一个原字符串左对齐,并使用字符fillchar填充至指定长度width的新字符串。
width -- 指定字符串长度
fillchar -- 填充字符,默认为空格
函数示例
>>> a="apple"
>>> a.ljust(10)
'apple '
>>> a.ljust(10,'.')
'apple.....'
>>> a.ljust(3,'2')
'apple'
str.rjust(width[, fillchar])
S.rjust(width[, fillchar]) -> string
函数功能
返回一个原字符串右对齐,并使用字符fillchar填充至指定长度width的新字符串。
width -- 指定字符串长度
fillchar -- 填充字符,默认为空格
函数示例
>>> a="apple"
>>> a.rjust(10)
' apple'
>>> a.rjust(10,'.')
'.....apple'
>>> a.rjust(3,'.')
'apple'
str.expandtabs([tabsize])
S.expandtabs([tabsize]) -> string
函数功能
把字符串中的 tab 符号(' ')转为空格,tab 符号(' ')默认的空格数是8,tabsize -- 指定转换字符串中的 tab 符号(' ')转为空格的字符数。
函数示例
>>> s = "today is a good d ay"
>>> print s
today is a good d ay
>>> s.expandtabs()
'today is a good d ay'
>>> s.expandtabs(4)
'today is a good d ay'
>>> s.expandtabs(1)
'today is a good d ay'
>>> s.expandtabs(0)
'today is a good day'
str.format(*args, **kwargs)
S.format(*args, **kwargs) -> string
函数功能
格式化字符串变量。2.7版本和3.1版本之后才支持{}这种格式。老版本会报错
ValueError: zero length field name in format
参见:ValueError: zero length field name in format python
函数示例
>>> name = 'StivenWang'
>>> fruit = 'apple'
>>> print 'my name is {},I like {}'.format(name,fruit)
my name is StivenWang,I like apple
>>> print 'my name is {1},I like {0}'.format(fruit,name)
my name is StivenWang,I like apple
>>> print 'my name is {mingzi},I like{shuiguo}'.format(shuiguo=fruit,mingzi=name)
my name is StivenWang,I like apple
大小写
str.lower()
S.lower() -> string
转换字符串中所有大写字符为小写
>>> a="oiawh92dafawFAWF';;,"
>>> a.lower()
"oiawh92dafawfawf';;,"
str.upper()
S.upper() -> string
转换字符串中所有小写字符为大写
>>> a="oiawh92dafawFAWF';;,"
>>> a.upper()
"OIAWH92DAFAWFAWF';;,"
str.swapcase()
S.swapcase() -> string
函数功能
将字符串的大小写转换。小写转大写,大写转小写
函数示例
>>> s="ugdwAWDgu2323"
>>> s.swapcase()
'UGDWawdGU2323'
分割
str.split([sep[, maxsplit]])
S.split([sep [,maxsplit]]) -> list of strings
函数功能
通过指定分隔符sep对字符串进行切片,如果参数maxsplit有指定值,则仅分隔 maxsplit个子字符串。如果分隔符sep没有给定,则默认以空格分割。
函数示例
>>> s="sys:x:3:3:Ownerofsystemfiles:/usr/sys:"
>>> s.split(":")
['sys', 'x', '3', '3', 'Ownerofsystemfiles', '/usr/sys', '']
>>> s.strip(":").split(":")
['sys', 'x', '3', '3', 'Ownerofsystemfiles', '/usr/sys']
>>> len(s.strip(":").split(":"))
6
>>> s="sa aa aa as"
>>> s.split()
['sa', 'aa', 'aa', 'as']
str.splitlines([keepends])
S.splitlines(keepends=False) -> list of strings
函数功能
按照行分隔,返回一个包含各行作为元素的列表。如果参数keepends=False后者为空或者为0,则不包含"
",否则包含"
"
函数示例
>>> s="Line1-a b c d e f
Line2- a b c
Line4- a b c d"
>>> print s.splitlines()
['Line1-a b c d e f', 'Line2- a b c', '', 'Line4- a b c d']
>>> print s.splitlines(0)
['Line1-a b c d e f', 'Line2- a b c', '', 'Line4- a b c d']
>>> print s.splitlines(1)
['Line1-a b c d e f
', 'Line2- a b c
', '
', 'Line4- a b c d']
>>> print s.splitlines(2)
['Line1-a b c d e f
', 'Line2- a b c
', '
', 'Line4- a b c d']
>>> print s.splitlines(3)
['Line1-a b c d e f
', 'Line2- a b c
', '
', 'Line4- a b c d']
>>> print s.splitlines(4)
['Line1-a b c d e f
', 'Line2- a b c
', '
', 'Line4- a b c d']
str.partition(sep)
S.partition(sep) -> (head, sep, tail)
函数功能
根据指定的分隔符sep将字符串进行分割(返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串)。且分隔符不能为空也不能为空串,否则会报错。
函数示例
>>> s="are you know:lilin is lowser"
>>> s.partition("lilin")
('are you know:', 'lilin', ' is lowser')
>>> s.partition("")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: empty separator
>>> s.partition()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: partition() takes exactly one argument (0 given)
修改
str.strip([chars])
S.strip([chars]) -> string or unicode
函数功能
用于移除字符串头尾指定的字符(默认为空格)。如果字符为unicode的,则先把字符串转化为unicode的再进行strip操作。
函数示例
>>> s="egg is a apple"
>>> print s.strip("e")
gg is a appl
>>> s="
egg is a apple
"
>>> print s
egg is a apple
>>> print s.strip("
")
egg is a apple
str.lstrip([chars])
S.lstrip([chars]) ->string or unicode
函数功能
用于截掉字符串左边的空格或指定字符。
函数示例
>>> s="egg is a apple"
>>> print s.lstrip("e")
gg is a apple
>>> s="
egg is a apple
"
>>> print s.lstrip("
")
egg is a apple
>>>
str.rstrip([chars])
S.rstrip([chars]) -> string or unicode
函数功能
用于截掉字符串右边的空格或指定字符。
函数示例
>>> s="egg is a apple"
>>> print s.rstrip("e")
egg is a appl
>>> s="
egg is a apple
"
>>> print s.rstrip("
")
egg is a apple
>>>
str.replace(old, new[, count])
S.replace(old, new[, count]) -> unicode
函数功能
把字符串中的 old(旧字符串)替换成 new(新字符串),如果指定第三个参数max,则替换不超过 count次。
函数示例
>>> s="saaas"
>>> s.replace("aaa","aa")
'saas'
>>> s="saaaas"
>>> s.replace("aaa","aa")
'saaas'
>>> s="saaaaas"
>>> s.replace("aaa","aa")
'saaaas'
>>> s="saaaaaas"
>>> s.replace("aaa","aa")
'saaaas'
以上替换并不会递归替换,每次都是找到3个a之后替换成两个a,然后继续从3个a后面的位置开始遍历,而不是从头开始遍历。
编码
和编码相关的函数总共就两个str.decode([encoding[, errors]])hestr.encode([encoding[, errors]])
首先了解下和编码相关的几个概念
- str是文本序列
- bytes是字节序列
- 文本是有编码的 (utf-8, gbk, GB18030等)
- 字节没有编码这种说法
- 文本的编码指的是字符如何使用字节来表示
- Python3字符串默认使用utf-8编码
>>> s = '刘亦菲'
>>> type(s)
<class 'str'>
>>> help(s.encode)
Help on built-in function encode:
encode(...) method of builtins.str instance
S.encode(encoding='utf-8', errors='strict') -> bytes
Encode S using the codec registered for encoding. Default encoding
is 'utf-8'. errors may be given to set a different error
handling scheme. Default is 'strict' meaning that encoding errors raise
a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
'xmlcharrefreplace' as well as any other name registered with
codecs.register_error that can handle UnicodeEncodeErrors.
# 默认的编码是utf-8,以下按照默认编码
>>> s.encode()
b'xe5x88x98xe4xbaxa6xe8x8fxb2'
>>> '刘'.encode()
b'xe5x88x98'
>>> '亦'.encode()
b'xe4xbaxa6'
>>> '菲'.encode()
b'xe8x8fxb2'
>>> bin(0xe5)
'0b11100101'
>>> bin(0x88)
'0b10001000'
>>> bin(0x98)
'0b10011000'
>>> b = s.encode()
>>> b
b'xe5x88x98xe4xbaxa6xe8x8fxb2'
>>> b.decode()
'刘亦菲'
#以下为指定编码为GBK
>>> b = s.encode('GBK')
>>> b
b'xc1xf5xd2xe0xb7xc6'
>>> b.decode('GBK')
'刘亦菲'
>>> b.decode()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc1 in position 0: invalid start byte
以上对encode和decode的方法的使用中出现了bytes类型。以下是对该类型的简单介绍
- bytes 由str通过 encode方法转化得到
- 通过 b前缀定义bytes
>>> b = b'xe5x88x98'
>>> type(b)
<class 'bytes'>
>>> b
b'xe5x88x98'
>>> b.decode()
'刘'
除了encode外, str操作,都有对应bytes的版本, 但是传入参数也必须是bytes
bytes的可变版本bytearray
bytearray 是可变,在图像处理中经常会用到变化的bytes。相对bytes来说, bytearray多了 insert, append, extend, pop, remove, clear reverse这些操作,并且可以索引操作。
判断
str.startswith(prefix[, start[, end]])
函数功能
用于判断字符串是否以指定前缀开头,如果以指定后缀结尾返回True,否则返回False。可选参数"start"与"end"为检索字符串的开始与结束位置。prefix可为tuple。
函数示例
>>> s = "I am Mary,what's your name ?"
>>> s.startswith("I am")
True
>>> s.startswith("I are")
False
>>> s.startswith("I am",1,5)
False
str.endswith(suffix[, start[, end]])
S.endswith(suffix[, start[, end]]) -> bool
函数功能
用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。可选参数"start"与"end"为检索字符串的开始与结束位置。suffix可为tuple。
函数示例
>>> s = "I am Mary,what's your name ?"
>>> print s
I am Mary,what's your name ?
>>> s.endswith("name ?")
True
>>> s.endswith("mame ?")
False
>>> s.endswith("name ?",0,len(s)-2)
False
str.isalnum()
S.isalnum() -> bool
函数功能
检测字符串是否由字母或数字组成。如果是,返回True,如果有别的字符,则返回False。
字符串不为空,如果为空,则返回False。
函数示例
>>> a="123"
>>> a.isalnum()
True
>>> a="daowihd"
>>> a.isalnum()
True
>>> a="ofaweo2131giu"
>>> a.isalnum()
True
>>> a="douha ioh~w80"
>>> a.isalnum()
False
>>> a=""
>>> a.isalnum()
False
str.isalpha()
S.isalpha() -> bool
函数功能
检测字符串是否只由字母组成。字符串不为空,如果为空,则返回False。
函数示例
>>> a="123"
>>> a.isalpha()
False
>>> a="uuagwifo"
>>> a.isalpha()
True
>>> a="oiwhdaw899hdw"
>>> a.isalpha()
False
>>> a=""
>>> a.isalpha()
False
str.isdigit()
S.isdigit() -> bool
函数功能
检测字符串是否只由数字组成。字符串不为空,如果为空,则返回False。
函数示例
>>> a="123"
>>> a.isdigit()
True
>>> a="dowaoh90709"
>>> a.isdigit()
False
>>> a=""
>>> a.isdigit()
False
str.islower()
S.islower() -> bool
函数功能
检测字符串是否由小写字母组成。
函数示例
>>> a="uigfa"
>>> a.islower()
True
>>> a="uiuiga123141a"
>>> a.islower()
True
>>> a="uiuiga12314WATA"
>>> a.islower()
False
>>> a=""
>>> a.islower()
False
>>> a="doiowhoid;'"
>>> a.islower()
True
str.isupper()
S.isupper() -> bool
函数功能
检测字符串是否由大写字母组成。
函数示例
>>> a="SGS"
>>> a.isupper()
True
>>> a="SGSugdw"
>>> a.isupper()
False
>>> a="SGS123908;',"
>>> a.isupper()
True
str.isspace()
S.isspace() -> bool
函数功能
检测字符串是否只由空格组成
函数示例
>>> a=" "
>>> a.isspace()
True
>>> a=" 12 dw "
>>> a.isspace()
False
参考资料
记得帮我点赞哦!
精心整理了计算机各个方向的从入门、进阶、实战的视频课程和电子书,按照目录合理分类,总能找到你需要的学习资料,还在等什么?快去关注下载吧!!!

念念不忘,必有回响,小伙伴们帮我点个赞吧,非常感谢。
我是职场亮哥,YY高级软件工程师、四年工作经验,拒绝咸鱼争当龙头的斜杠程序员。
听我说,进步多,程序人生一把梭
如果有幸能帮到你,请帮我点个【赞】,给个关注,如果能顺带评论给个鼓励,将不胜感激。
职场亮哥文章列表:更多文章

本人所有文章、回答都与版权保护平台有合作,著作权归职场亮哥所有,未经授权,转载必究!