建立测试数据:
CREATE TABLE FactResults ( Name VARCHAR(50) , Course VARCHAR(50) , Score INT ) INSERT INTO FactResults ( Name , Course , Score ) SELECT '张三' , '语文' , 90 UNION ALL SELECT '张三' , '数学' , 83 UNION ALL SELECT '李四' , '语文' , 74 UNION ALL SELECT '李四' , '数学' , 84 UNION ALL SELECT '李四' , '物理' , 94 SELECT * FROM FactResults
多播:将数据集分发到多个输出的转换。
如同它的名字一样多点传送可以将一个路径中的数据输出到多个路径,你可能会使用这种转换将数据输出到多个路径中。编辑这种task,将它和输入源连接,然后将它和多个Destination连接,除了task的名字之外,它没有特别的编辑选项。
注意:多点传送类似于Split 转换,不同的是多点传送把所有的行都输出,Split将有条件地输出部分行。
Union All:合并多个数据集的转换。
联合所有task的功能和合并正好相反,它将多个数据源中的合并成一个结果集。例如,将两个XML数据源中的数据合并成一个输出然后将数据送入到关键词抽取任务中。
编辑这种转换,首先将第一个数据源连接到task然后将其他数据源连接到这个task。打开编辑界面,保证列被正确映射,DDIS将会自动适应是否正确映射。例如,一个输入字符是20个字符,另一个是50,出书将会是一个多于50个字符的列。
合并:合并两个已排序数据集的转换。
合并转换可以将两个路径中的输入数据合并成一个输出。这种转换类似于Union All转换,它有一些限制:
- 合并之前数据必须排序,可以在此之前使用排序转换或者在数据源中使用ORDER BY语句
- 合并的元数据类型必须相同,例如CustomerID不能在一个路径中是数字型的但是在另一个路径中是字符类型的
- 如果有多于两个路径,需要选择Union All转换
编辑这种task,确保在两个路径中的数据时一致的,选择列的时候会弹出对话框提示数据合并到路径1还是路径2,如果选择合并到路径1,然后连接路径2。这样选择之后最终将会从一个路径映射到另一个路径,有些路径的数据也可以忽略。
合并联接:使用 FULL、LEFT 或 INNER 联接将两个数据集联接起来的转换。
SSIS的一个目标就是使用任务,尽量保证不写任何代码,一个典型的例子就是连接合并。这种合并可以将两个输入进行内连接或者外连接然后选择性地输出。例如,在一个数据流中存储着包含EmployeeID的人力资源信息,在另一个数据流中存储着工资清单信息,可以对这两个路径进行连接,从人力资源信息中取得姓名,从工资清单信息中取得员工工资,然后从一个路径中输出。
注意:如果两个输入路径在同一个数据库,在OLE DB数据源中进行数据连接操作可能效率更高,如果在不同的数据库中可能效率后受到影响。这种连接合并在两个数据不是同一个数据库中或者不想编写代码时会很有用。
在项目中创建一个【数据流任务】,数据流如下:
组件【多播】的功能是:将其输入分发到一个或多个输出,每个输出都与输入一样。
因此第一个多播名称【多播 张三李四】分发出去的内容与上表一样。
每个组件我都用数据表中的姓名(张三、李四)做名称,方便查看。
组件【条件性拆分】设置如下,姓名等于“张三” 的和 姓名不等于“张三” 的分别输出到两个多播中。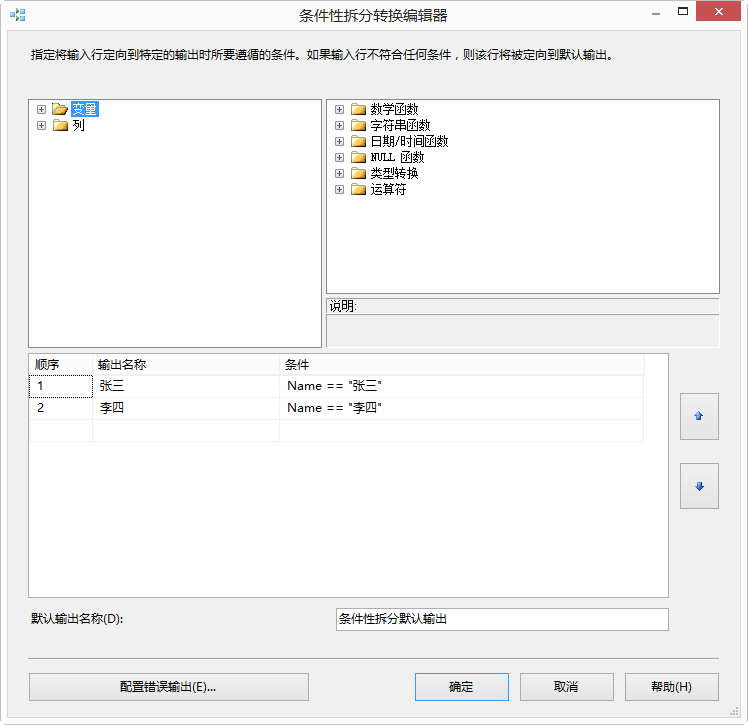
接下来,先看组件【Union All】,是【多播 张三李四】和【多播 只有张三】两个数据的内容上下合并,理论结果: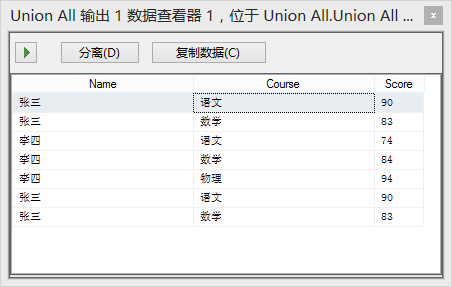
再看组件【合并联接】,是【排序_张三李四】和【排序_李四】两个表数据排序后合并连接。合并方式如图:
连接类型为:左外部连接。左边为【排序_张三李四】,为第一个输入。
条件为(相当于): ON A.Name=B.Name AND A.Course=B.Course
输出名称重新定义。
输出理论结果为:(排序是按组件【排序_张三李四】的排序结果)
最后为组件【合并】,合并是【合并联接】后与【多播 只有张三】排序后的合并。
第一输入为【排序_张三李四左连接】,因为其有多列(5行6列),以此数据结构为准。
第二输入为【排序_张三】(2行3列)
合并转换如图:
可以看出,【排序_张三】列数不够,所以与上表合并时<忽略>,即无任何值。Union是排序合并,理论结果为:
至此,设计完成,现在编译!可看到数据流传递的行数。结果如图: