特征,判决,得到判决
1.什么是haar特征?
特征 = 某个区域的像素点经过某种四则运算之后得到的结果。
这个结果可以是一个具体的值也可以是一个向量,矩阵,多维。实际上就是矩阵运算
2.如何利用特征 区分目标?
阈值判决,如果大于某个阈值,认为是目标。小于某个阈值认为是非目标。
3.如何得到这个判决?
使用机器学习,我们可以得到这个判决门限
Haar特征的计算原理
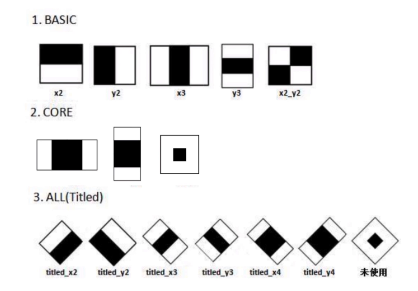
这些是在opencv中使用的haar特征。
基础类型(5种) 核心(3种)all(6种)
这里的14个图片分别对应十四种特征。

如何使用呢?
蓝色区域表明我们所得到的图片。黑白矩形框是我们的特征模板。
比如: 我们的模板是一个(10,10)的矩阵,共覆盖了100个像素点。黑白各占50个像素点
将当前模板放在图像上的任意位置上,在这里,用白色区域覆盖的50个像素之和减去黑色区域的50个像素之和得到我们的特征。

推导公式的一样性。
公式二:
这里的整个区域指黑白两色覆盖的整个100个像素。这两个权重是不一样的。
整体的权重值为1 黑色部分权重值为-2
整个区域的像素值 * 权重1 + 黑色部分 * 权重2
= 整个区域 * 1 + 黑色部分 * -2
=(黑 + 白) * 1 + 黑色部分 * -2
= 白色 - 黑色
Haar特征遍历
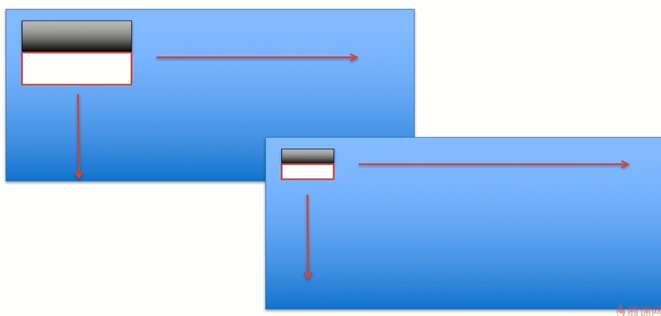
计算整幅图的Haar特征
如果想要计算整幅图的Haar特征,我们就需要遍历,
假设这个haar特征的模板是(10,10)共100个像素。图片的大小是(100,100)
如果想获取这个图片上所有的harr特征。使用当前模板沿着水平和竖直方向进行滑动。从上到下,从左到右进行遍历。
遍历的过程中还要考虑步长问题。这个模板一次滑动几个像素。一次滑动10个像素,就需要9次。加上最开始的第0次。
10个模板。
计算这100个模板才能将haar特征计算完毕。
如果我们的步长设置为5.那么就要滑动20次。400个模板。运算量增加4倍。
其实仅仅这样的一次滑动并没有结束,对于每一个模板还要进行几级缩放,才能完成。
需要三个条件:100*100,10*10,step=10,模板 1
模板 :缩放,这就需要再次进行遍历
运算量太大 :
计算量 = 14个模版*20级缩放*(1080/2*720/2) * (100点+ -) = 50-100亿
(50-100)*15 = 1000亿次
积分图
特征:计算矩形方块中的像素
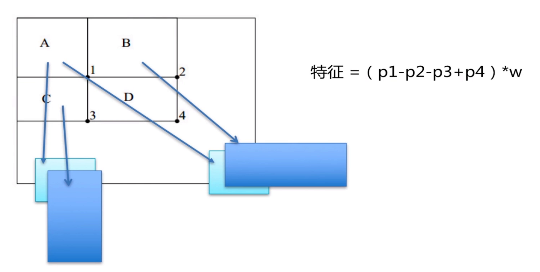
有ABCD四个区域,每个区域都是一个矩形方块。
A区域是左上角那一块小区域,而B区域是包含A区域的长条。
C区域又是包含A的竖直长条。D区域是四个方块之和。
1,2,3,4表明这四个小区域。
进行快速计算:
A 1 B 1 2 C 1 3 D 1 2 3 4
4 = A-B-C+D = 1+1+2+3+4-1-2-1-3 = 4(10*10 变成3次+-)
任意一个方框,可由周围的矩形进行相减得到。
问题: 在计算每一个方块之前,需要将图片上所有的像素全部遍历一次。至少一次。
特征=(p1-p2-p3+p4)*w
p1 p2 p3 p4 分别是指某一个特征相邻的abcd的模块指针。
adaboost分类器
haar特征一般会和adaboost一起使用
haar特征 + Adaboost是一个非常常见的组合,在人脸识别上取的非常大成功
Adaboost分类器优点在于前一个基本分类器分出的样本,在下一个分类器中会得到加权。加权后的全体样本再次被用于训练下一个基本分类器。
就是说它可以加强负样本。
例如:我们有 苹果 苹果 苹果 香蕉 找出苹果
第一次训练权值分别为: 0.1 0.1 0.1 0.5
因为香蕉是我们不需要的所以0.5,我们正确的样本系数减小,负样本得到加强。
把出错的样本进行加强权值。再把整个结果送到下一个基本分类器
训练终止条件:
1. for迭代的最大次数 count
2. 每次迭代完的检测概率p(p是最小的检测概率,当大于p就终止)
分类器的结构
haar特征计算完之后要进行阈值判决,实际是一个个判决过程。
if(haar> T1) 苹果[第一级分类器];[第二级分类器]and haar>T2
两级都达成了,才会被我们认定为苹果。
两级分类器的阈值分别是t1 和 t2,对于每一级的分类器我们称之为强分类器。
2个强分类器组成。一般有15-20强分类器。 要连续满足15-20个强分类器才能认证为目标。
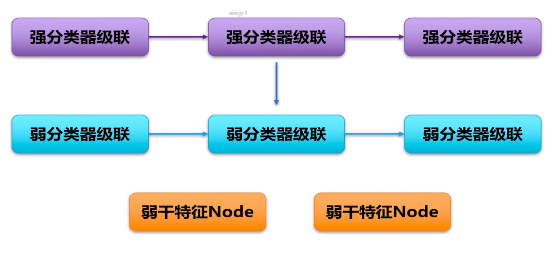
3个强分类器,每个强分类器会计算出一个独立的特征点。使用每一个独立的特征进行阈值判。
强分类器1 特征x1 阈值t1 强分类器2 特征x2 阈值t2 3同理(阈值是通过训练终止时得到的)
进行判决过程: x1>t1 and x2>t2 and x3>t3
三个判决同时达成,目标-》苹果
三个强分类器只要有一个没通过就会被判定为非苹果。作用:判决。而弱分类器作用:计算强分类器特征x1 x2 x3
每个强分类器由若干个弱分类器组成
1强 对多个弱分类器 对应多个特征节点
弱分类器作用:计算强分类器特征x1 x2 x3
强分类器的输入特征是多个弱分类器输出特征的综合处理。
x2 = sum(y1,y2,y3)
y1 弱分类器特征谁来计算的?
node节点来计算
一个弱分类器最多支持三个haar特征,每个haar特征构成一个node节点
Adaboost分类器计算过程
3个haar -》 3个node
node1 haar1 > node的阈值T1 z1 = a1
node1 haar1 < node的阈值T1 z1 = a2
Z = sum(z1,z2,z3) > 弱分类器T y1 = AA
Z = sum(z1,z2,z3) < 弱分类器T y1 = BB
从node向强分类器
第一层分类器:haar->Node z1 z2 z3 得到的就是z1 z2 z3
第二层分类器:Z>T y1 y2 y3: 弱分类器的计算特征
第三层分类器:x = sum(y1,y2,y3) > T1 obj
训练过程
1.初始化数据 权值分布 苹果 苹果 苹果 香蕉 0.1 0.1 0.1 0.1 (第一次权值都是相等的)
2.遍历阈值 p计算出误差概率,找到最小的minP t
3.计算出G1(x)
4.权值分布 update更新权重分布: 0.2 0.2 0.2 0.7
5.训练终止条件。
在苹果或者win平台都有相应的可执行文件,不用我们代码实现
opencv自带的人脸识别的Adaboost分类器的文件结构(xml)