转自:https://juejin.cn/post/7085140011985109029,https://www.51cto.com/article/708109.html
https://www.infoq.cn/article/5fboevkal0gvgvgeac4z
1.为何重试
微服务节点之间的调用频繁,服务间的互相调用无论是RPC还是HTTP,都是依赖于网络,但经常由于网络抖动等系统原因导致服务之间调用失败,此时如果使用重试可以提高服务节点之间调用的成功率,提高系统的稳定性。
重试不仅提高系统的稳定性还可以提高系统的数据的一致性,现有的分布式事务系统复杂度较高,往往是选择最终一致性,即通过重试补偿的形式,达到最终一致性。
2.风险
重试能够提高服务稳定性,但是一般情况下大家都不会轻易去重试,主要是因为重试的流量不可控,且有放大故障,产生重试风暴的风险,重试流量呈指数级放大,存在链路放大的效应,导致系统雪崩。
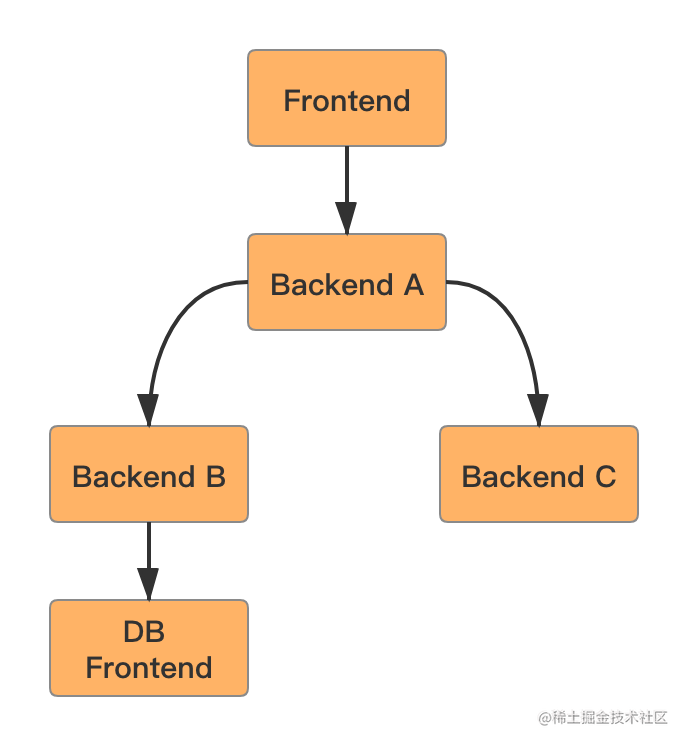
假设现在场景是 Backend A 调用 Backend B,Backend B 调用 DB Frontend,均设置重试次数为 3 。
- 如果 Backend B 调用 DB Frontend,请求 3 次都失败了,这时 Backend B 会给 Backend A 返回失败。
- 但是 Backend A 也有重试的逻辑,Backend A 重试 Backend B 三次,每一次 Backend B 都会请求 DB Frontend 3 次,这样算起来,DB Frontend 就会被请求了 9 次,实际是指数级扩大。
存在指数放大效应。
3.重试机制
包括同步原地重试、异步重试。
- 原地重试:程序在调用下游服务失败的时候重新发起一次;
- 异步重试:将请求信息丢到某个 mq 中,后续有一个程序消费到这个事件进行重试。【追求强一致,可快速响应上游,由异步完成重试】
重试算法:
- 线性退避:每次失败固定等待固定的时间。
- 随机退避:每次失败等待随机的时间重试。
- 指数退避:连续重试时,每次等待的时间都是前一次等待时间的倍数。
- 综合退避:结合多种方式,比如线性 + 随机抖动、指数 + 随机抖动。加上随机抖动可以打散众多服务失败时对下游的重试请求,防止雪崩。
为何需要等待?因为网络抖动或者下游负载高,马上重试成功的概率必然远远小于稍等一会再重试。
4.防止重试风暴
4.1 单实例限流
一个服务不能不受限制的重试下游,很容易造成下游被打挂。常用的是令牌桶或者滑动窗口两种实现,这里简单实用滑动窗口实现。如下图所示,每秒会产生一个Bucket,我们在Bucket里记录这一秒内对下游某个接口的成功、失败数量。进而可以统计出每秒的失败率,结合失败率及失败请求数判断是否需要重试,每个 Bucket 在一定时间后过期。
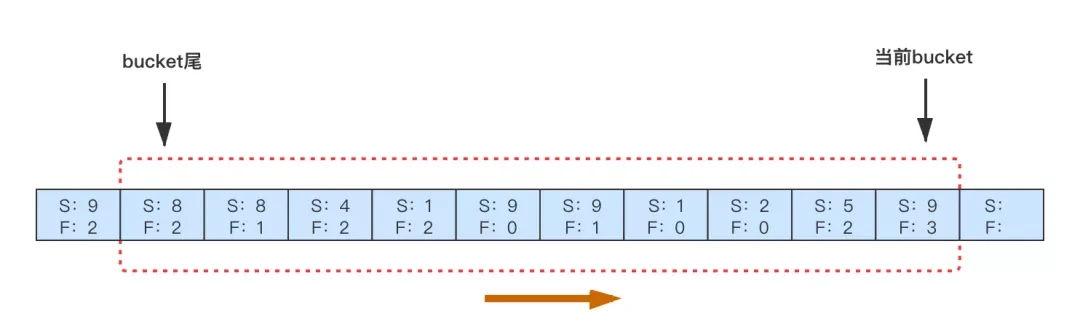
如果下游大面积失败,这种时候是不适合重试的,我们可以配置一个比如失败率超过10%不重试的策略,这样在单机层面就可以避免很多不必要的重试。
//这里的图意思是,针对一个服务就会有一个滑动窗口来记录吗,窗口范围表示时间,定时向右移动,窗口内记录该服务调用下游接口成功失败的情况?
4.2 限制链路重试-规范重试状态码
链路层面防止重试的最好做法是只在最下游重试,“只有最靠近错误发生的那一层才重试”,如上图中只允许Backend B重试,Google使用如下方式来实现:
- 约定一个特殊的业务状态码nomore_retry,它表示失败了,但是别重试。
- 任何一个环节收到下游这个错误,不会重试,继续透传给上游。
通过这个模式,如果是数据库抖动情况下,只有最下游的三个重试请求,上游服务判断状态码知道不可重试不再重试。除此之外,在一些业务异常情况下也可通过状态码区分出无需重试的状态。可以有效避免重试风暴,但是缺陷是需要业务方强耦合上这个状态码的逻辑,一般需要公司层面做框架上的约束。(不然大家都不这么做,状态码也无效了。)
4.3 超时优化
但4.2也可能有问题,关于超时的情况,显然无法通过错误码识别,例如 A -> B -> C -> D 情况,如果C故障了,B可以获取到错误码,并返回给 A,但是因为 A 请求 B 超时了,所以是获取不到错误码的,这个时候 A 又会发起重试。那么针对超时的情况有没什么办法做优化,避免无必要的重试呢?
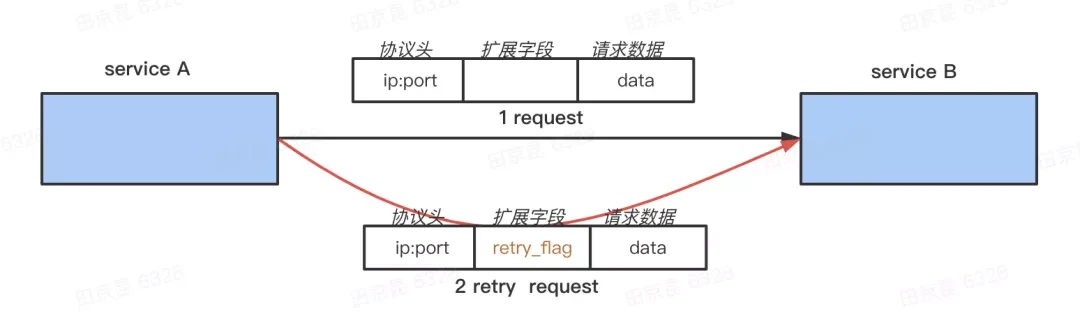
“对重试请求不重试”的方案:
对于重试的请求,我们在 Request 中打上一个特殊的 retry flag ,在上面 A -> B -> C 的链路,当 B 收到 A 的请求时会先读取这个 flag 判断这个请求是不是重试请求,如果是,那它调用 C 即使失败也不会重试;否则调用 C 失败后会重试 C 。同时 B 也会把这个 retry flag 下传,它发出的请求也会有这个标志,它的下游也不会再对这个请求重试:
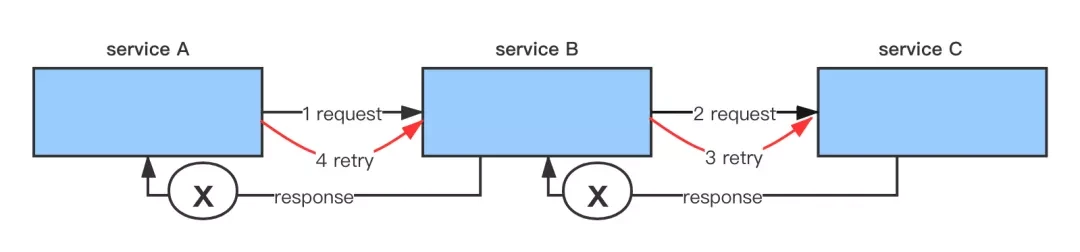
重试就在B处给截断了。 最坏情况下是倍数增长,而不是指数。
4.4 超时场景优化
分布式系统中,RPC 请求的结果有三种状态:成功、失败、超时,其中最难处理的就是超时的情况。
需要设置让上游时间更长一点?以及Backup Requests机制,设置一个比超时时间小的时间点t3,超过这个时间不返回认为超时,则发送第二个请求,当然会控制这个量。
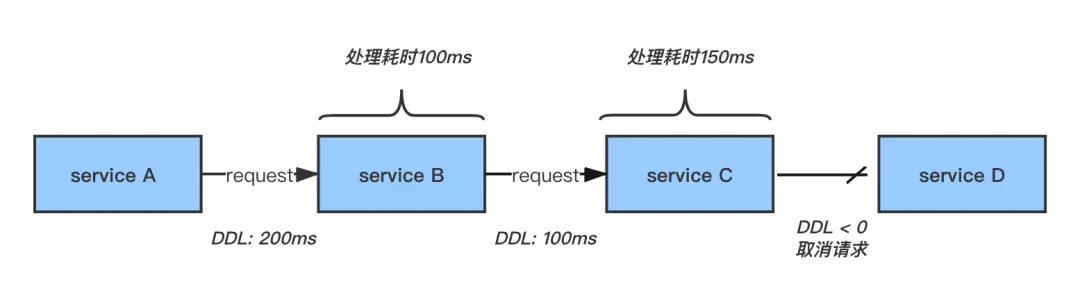
DDL是给每个请求加一个过期时间,像TTL路由时间一样,如果过期了则表明该包不存在,则丢弃不继续请求了。从而减少无用重试。
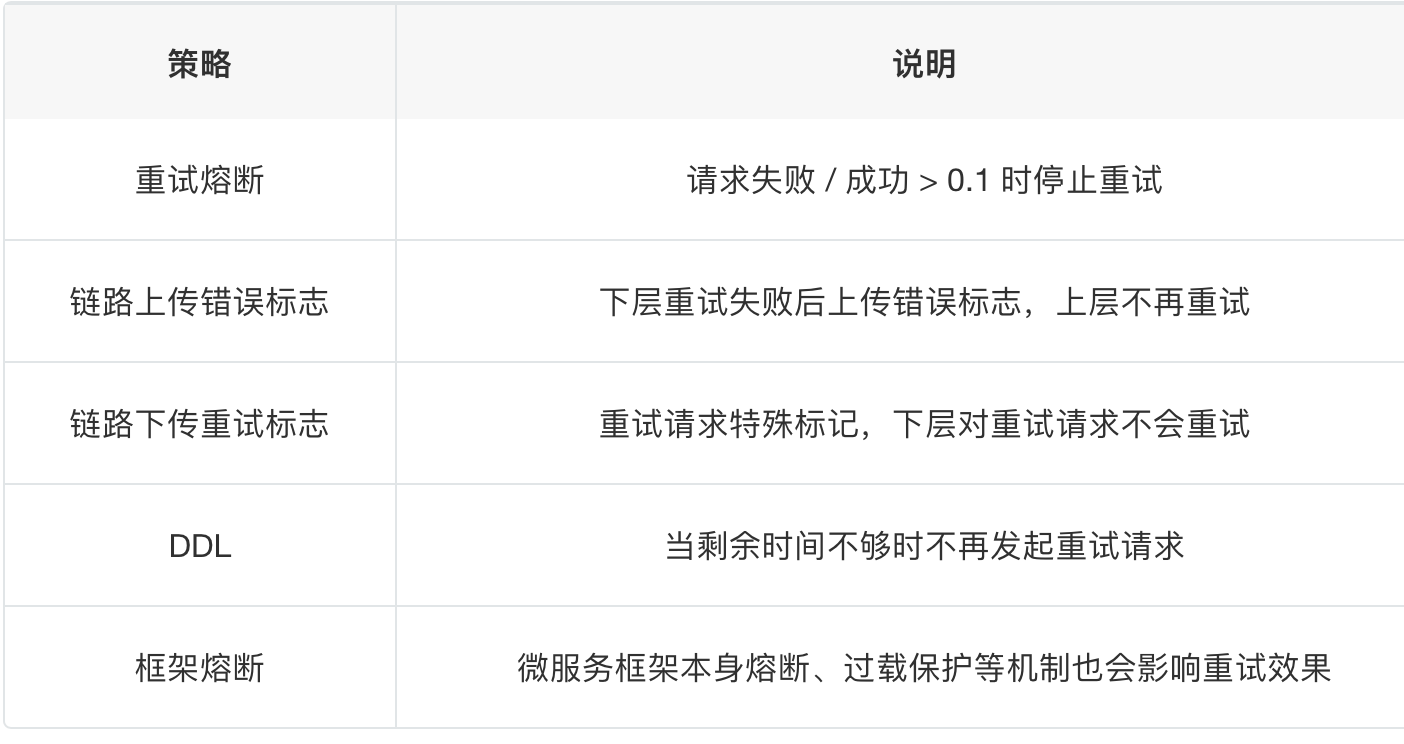
总结:
//大厂还是牛啊。