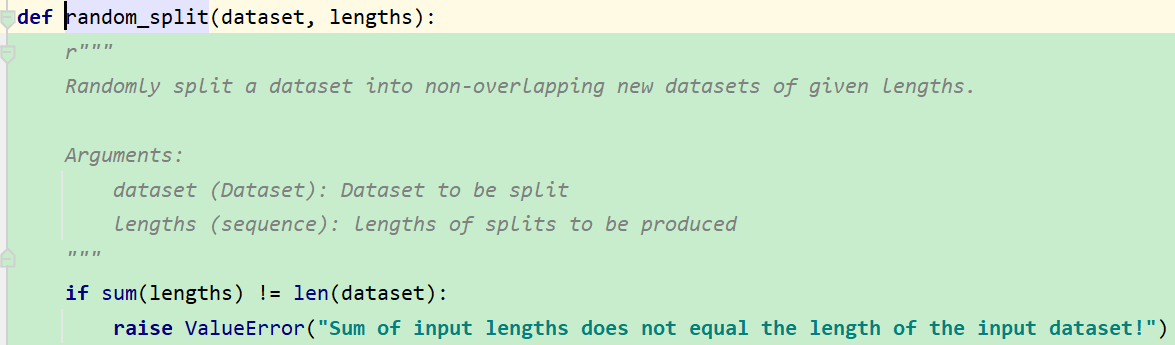
1.torch.utils.data.random_split()
pytorch有多种方法划分,但这个是最简单的。
转自:https://www.cnblogs.com/marsggbo/p/10496696.html
train_size = int(0.8 * len(full_dataset)) test_size = len(full_dataset) - train_size train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size])
划分完了之后训练和测试集的类型是:
<class 'torch.utils.data.dataset.Subset'>
由原来的Dataset类型变为Subset类型,两者都可以作为torch.utils.data.DataLoader()的参数构建可迭代的DataLoader。
随机划分时,需要保证和为dataset的长度:
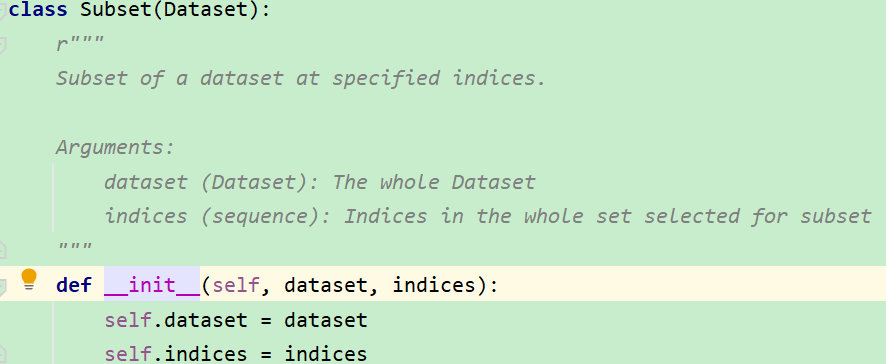
2.torch.utils.data.Subset()
https://stackoverflow.com/questions/47432168/taking-subsets-of-a-pytorch-dataset
import torchvision import torch trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=None) evens = list(range(0, len(trainset), 2))#偶数位 odds = list(range(1, len(trainset), 2))#奇数位 trainset_1 = torch.utils.data.Subset(trainset, evens)#Subset类型 trainset_2 = torch.utils.data.Subset(trainset, odds)#Subset类型 #由Subset对象构建DataLoader trainloader_1 = torch.utils.data.DataLoader(trainset_1, batch_size=4, shuffle=True, num_workers=2) trainloader_2 = torch.utils.data.DataLoader(trainset_2, batch_size=4, shuffle=True, num_workers=2)
传入的第二个参数为所需要选取的样本的下标:
3.SubsetRandomSampler类
https://www.cnblogs.com/marsggbo/p/10496696.html
# Creating data indices for training and validation splits: dataset_size = len(dataset) indices = list(range(dataset_size)) split = int(np.floor(validation_split * dataset_size)) if shuffle_dataset : np.random.seed(random_seed) np.random.shuffle(indices) train_indices, val_indices = indices[split:], indices[:split] #随机选择下标 # Creating PT data samplers and loaders: train_sampler = SubsetRandomSampler(train_indices) valid_sampler = SubsetRandomSampler(val_indices) #以sampler取样器作为 train_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, sampler=train_sampler) validation_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, sampler=valid_sampler)