1.python大数
https://segmentfault.com/a/1190000015284473
原来py原生就支持大数运算,比如可以用数组来存储大数,不用再像C语言那样,分长整型短整型之类的了。
[longintrepr.h] struct _longobject { PyObject_VAR_HEAD int *ob_digit; }; ob_digit[0] = 789; ob_digit[1] = 456; ob_digit[2] = 123; #这样来实现保存123456789这样的大数。
2.如何不微调提取bert的字向量
https://www.biendata.com/models/category/3529/L_notebook/ :这里面说:“该模型采用BERT模型提取出字向量(不Finetune),然后结合腾讯词向量”。
那么如何获取bert的字向量呢?使用的bert是roeberta_zh_L-24_H-1024_A-16。
那么roeberta_zh_L-24_H-1024_A-16的切词方式是什么样的呢?是按照字来切吗?roberta_wwm_ext它是按照word做mask的,whole word mask,那它切词是按照什么来切的呢?这个我好像真还没注意过。
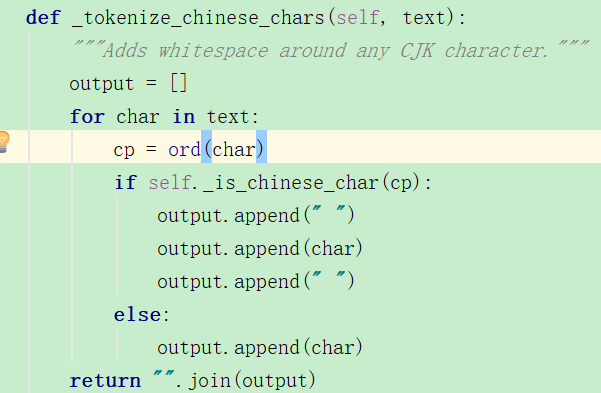
tokenizer里首先就会判断是否是中文,如果是中文的话那就会添加空格。
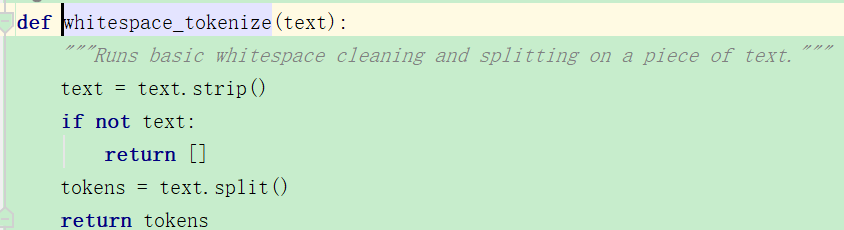
之后就用这个函数直接切分。
上面的是传统bert里,那么现在来看看roeberta_zh_L-24_H-1024_A-16是如何实现的。好像这个分词也没有什么差别啊,也是单个字分开的。

但在介绍中它说,使用了全词mask。具体是怎么实现的呢?
https://github.com/ymcui/Chinese-BERT-wwm,从这里我们可以知道全词mask是这样的?但是它的这个分词是怎么实现的?用的什么工具?

https://github.com/ymcui/Chinese-BERT-wwm/issues/4 这个讲的还蛮不错的,同属一个词的所有子词均会被处理(mask,保留,替换) ,非常好。
假设切词为:tok_list = ["there", "is", "an", "ap", "##p", "##le", "tr", "##ee", "nearby", "."]

https://github.com/ymcui/Chinese-BERT-wwm/issues/73 从这个issue上面我发现,要关注的文件在create_pretraining_data.py,
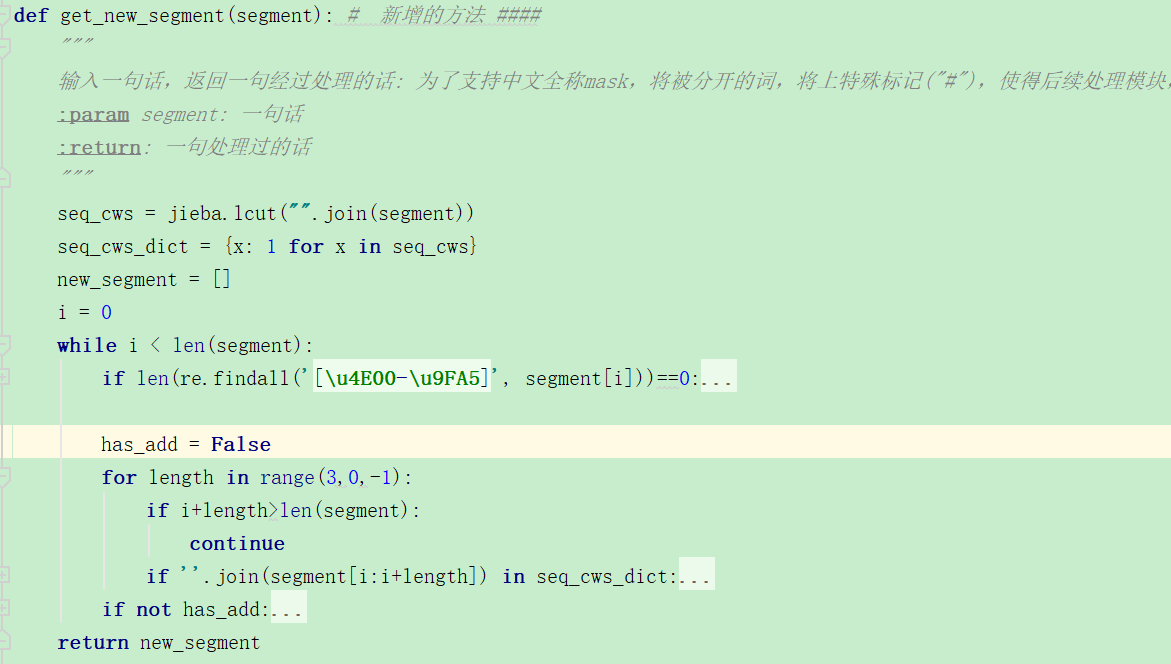
这个函数就是处理分词的,将被分开的词做上##,之后mask的时候全mask掉。
4.from itertools import cycle
https://www.liaoxuefeng.com/wiki/897692888725344/983420006222912
负责把一个序列无限重复下去,
>>> import itertools >>> cs = itertools.cycle('ABC') # 注意字符串也是序列的一种 >>> for c in cs: ... print c ... 'A' 'B' 'C' 'A' 'B' 'C' ...
5.--train_steps 30000 ;
这个train_step的设置我有问题了,因为我的每个train_dataloader都是80k,bs=8,那么共有10k个train_step就可以了啊,多了就会重复训练了,容易过拟合啊。有问题啊,这个地方训练的时候从来都没注意过。
看了别的我忽然明白了,设置为30k,那么就相当于每个交叉验证的过程中,训练集学习3个epoch啊,如此简单!
4-20日——————————————————
1.pytorch中contiguous()
https://blog.csdn.net/jacke121/article/details/80824575
在view之前最好contiguous一下,因为view需要一块连续的存储空间,如果之前tensor进行过transpose或者permute,
import torch x = torch.ones(10, 10) print(x.is_contiguous()) # True print(x.transpose(0, 1).is_contiguous()) # False print(x.transpose(0, 1).contiguous().is_contiguous()) # True #输出 True False True
transpose之后存储空间就是不连续的了,不能直接view。对于上面的例子,如果直接:
x.transpose(0, 1).view(-1,1) #输出:报错 x.transpose(0, 1).view(-1,1) RuntimeError: invalid argument 2: view size is not compatible with input tensor's size and stride
(at least one dimension spans across two contiguous subspaces). Call .contiguous() before .view(). at
就会提示需要调用连续函数。
2.bert中的split_num是什么意思?
https://zhuanlan.zhihu.com/p/94281007 从这里就能看出它的作用,它的数据类型为新闻标题+内容,将内容进行分段,分split_num段,标题作为第一句,这样长文本就能够输入进模型中了,
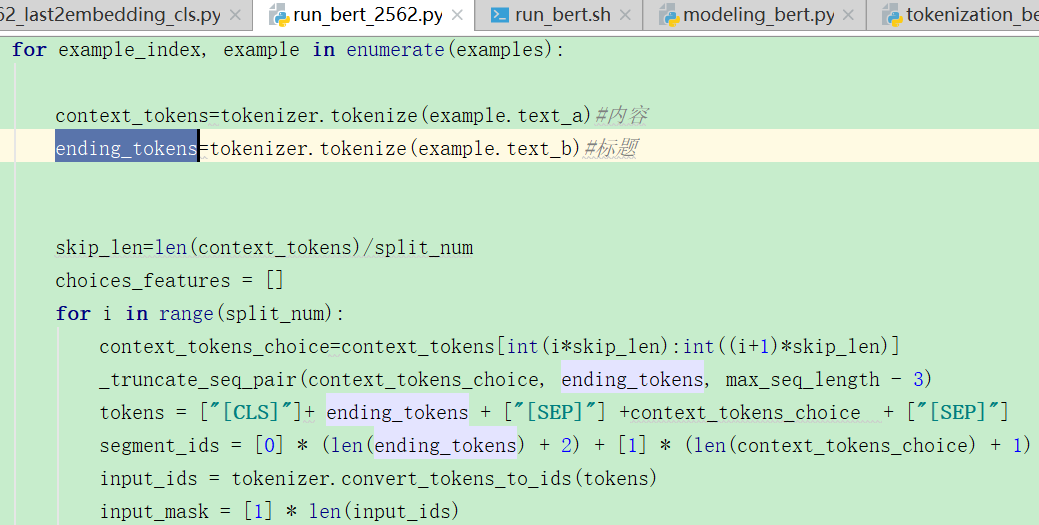
但是它是怎么输入进split_num个模型中的呢?这个地方的实现我还有点模糊,

但是目前我认为,短文本不必要这么构建吧。
3.如何实现首尾相连?
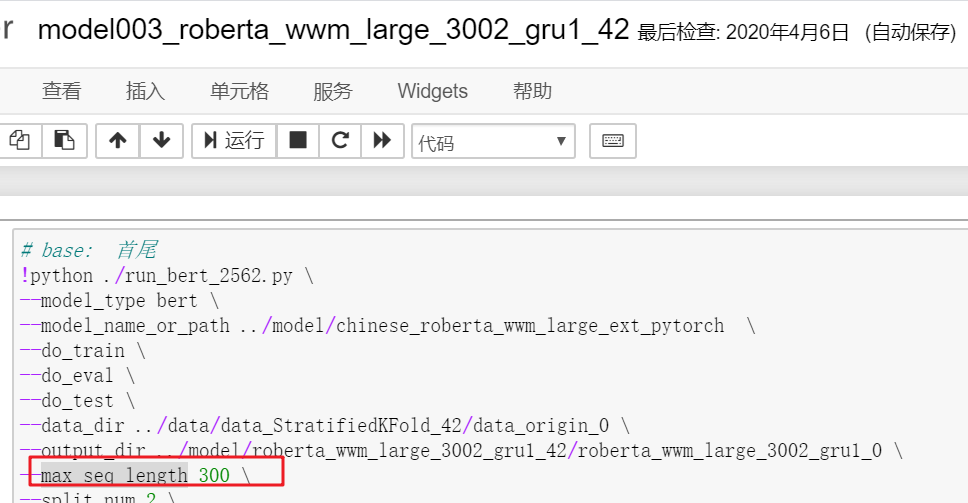
虽然但是,它是怎么实现首尾相连的呢?
它也没有明着建立多个bert啊,这里还是不明白,存疑。
???????
4.lstm hidden_size 对长文本和短文本有什么不同吗
这个我也不太明白,没搜到什么,我觉得对于短文本可以设置的小一些,比如256,对于长文本设置的长一些比如512;
如果对短文本设置的比较大,会不会过拟合这样?
5.BertModel的forward输出
它的forward之后输出是什么呢?
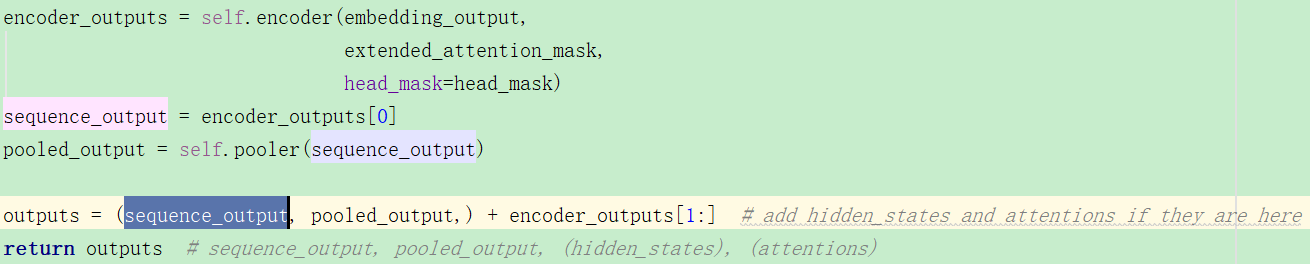
可以看到由三部分组成,在注释里分别是这么说的:
sequence_output:也就是the last hidden-state,模型最后一层的输出处的隐藏状态序列,shape为:(batch_size, sequence_length, hidden_size)`
pooled_output:序列的第一个标记(分类标记,CLS)的最后一层隐藏状态,shape为:(batch_size, hidden_size)
encoder_outputs[1:]:这个是其他层的输出,当config.output_hidden_states=True`的时候才会有,但是我看其他的模型参数这个都会默认为False啊,而且后来也没有修改。
![]()
就一般第三个参数是没有的吧,如果没有设置为True的话。
但是看这个代码的话,我认为它要想输出最后两层的bert的输出就应该将output_hidden_states设置为True,
当这个参数设置为True的时候,encoder_outputs[1:]的shape可以参考下面的代码:
import numpy as np a=np.random.randn(8,4,2) a=[a,a] b=a[-1][:,0] c=a[-1][:,0] #输出: >>> b.shape (8, 2) >>> c.shape (8, 2)
因为它是所有隐层的输出,是一个list,每个元素的shape为:(batch_size, sequence_length, hidden_size)。

后面两个就可以获取到倒数第二层和倒数第三层[CLS]的输出了,这样接下去连接一个线性层和softmax。