1.学习模糊神经推理系统
https://blog.csdn.net/leneey/article/details/80909047
基本对过程有了了解,但是要对它形成讲解还不行,所以先看论文吧。
2.学习模糊逻辑
https://blog.csdn.net/yuyanjingtao/article/details/90177004
#不了解模糊逻辑的话,接下来我应该都看不懂了。
1.隶属度(Degree of Membership)
在模糊逻辑的眼中,大雨,小雨,和中雨之间是没有严格的界限的,也就是说某一种雨量的大小并不完全归属于某一个类,而是以隶属度来衡量的。
比如对于10mm降雨,隶属于小雨的隶属度为0.5, 中雨的隶属度为0.4,大雨的隶属度为0.1;
对于100mm降雨,小雨的隶属度为0, 中雨的隶属度为0.3,大雨的隶属度为0.7。
将逻辑的输入数值(降雨量)转化成各个集合(小雨,中雨,大雨)的隶属度的过程就叫做Fuzzification。 也是模糊逻辑的第一步。
如何确定输入数值与隶属度的关系呢,这就要用到隶属度函数,隶属度函数的图形可以是任意的,但常用的方法是三角形或者梯形。
#无图
上图是考试分数和学生成绩的隶属度关系。 比如考0分,Poor的隶属度为1,Avg. 和Good为0。 考试为32.5分(红黑交叉点),Poor的隶属度为0.5,Avg.为0.5, Good为0。 在任意一点都能找到其所对应的集合的隶属度。
所以这个隶属度函数其实也是一个规则的确立,还是说这个是通过NN学习的???
2. 模糊逻辑的“与,或,非”运算
模糊逻辑的运算实际上就是模糊逻辑中分解出的各个隶属度的运算。我们将逻辑的两个输入定义为A,B,输出为C(A与B -> C),举个例子,A = Poor: 0.5(Poor的隶属为0.5 )B = Good:0.2, 那么C= A与B是多少呢?
#挺有意思的,是因为比较简单,目前我还能看懂。。
最大隶属法,最小隶属法。
3. 模糊逻辑的决策规则(Rule Base)
百度百科:“隶属度A(x)越接近于1,表示x属于A的程度越高,A(x)越接近于0表示x属于A的程度越低。用取值于区间[0,1]的隶属函数A(x)表征x 属于A的程度高低,这样描述模糊性问题比起经典集合论更为合理。
#这个在链接中有给出

首先对于给定的两个值,根据隶属度函数(一般是三角形,矩阵之类的。),就可以计算出对taste,hunger的隶属度;
计算出隶属度之后就可以计算出对于隶属度规则来说,的一个分布吧。

这些输出我们在模糊逻辑中定义为Fire Strength(FS)。耐火程度。
4. 去模糊化(De-fuzzyfication)
模糊逻辑通过模糊化将输入的数值转化成各个集合的隶属度之后,再通过规则和运算得到若干个FS。
这些FS并不能为我们解决实际问题。
以之前分配食物为例,我们期望的是:给出任意两个输入值(Taste 和 Hunger)能输出一个确定的数值,这时我们就要用去模糊化来得到这个输出值了。
应用最广泛的就是:加权平均。


这个输出有什么用呢?你可以通过这个输出决定是否分配食物,设定一个阈值。
比如为4,如果小于等于这个阈值就不分配食物,大于这个阈值就分配食物。
另外去模糊化方法:最大值均值法;中心法;最大值平均法等。
总结:
从整个过程来看,最重要的就是模糊规则和模糊函数。对于给定的输入根据模糊函数计算出模糊值,模糊值可以对应到模糊规则结果上,然后去模糊化。
3.模糊逻辑和神经网络结合
汇集神经网络和模糊计算是优点,即人工神经网络具有 较强的自学习和联想功能能力,人工干预少,精度较高,对专家知识的利用也较好;而模糊计算的特点有 推理过程容易理解、专家知识利用较好、对样本的要求较低等。
1. 利用神经网络,来学习、演化模糊规则库。类似数据挖掘的过程,模糊竞争学习算法 : 利用神经网络来增强的 模糊计算系统
2. 利用模糊控制方法,不断改善神经网络的性能,如模糊BP算法 :利用模糊计算增强的神经网络。
4.the time between failure (TBFs)为什么能够用来做软件错误预测的数据呢?
https://tiku.baidu.com/web/singledetail/ca8be48da0116c175f0e4854

因为TBF能够表示软件的可用性,是有意义的数据,能表示软件的可靠性!

5.最小二乘法
#论文中又提到了LSE,但是我脑袋一片空白,虽然这是高中学的东西。
https://blog.csdn.net/ccnt_2012/article/details/81127117
大略看了一下,思想就是min(MSE),通过求导求极值。
6.优化时用到了遗传算法
https://www.jianshu.com/p/ae5157c26af9
其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向。
遗传算法的过程图解:
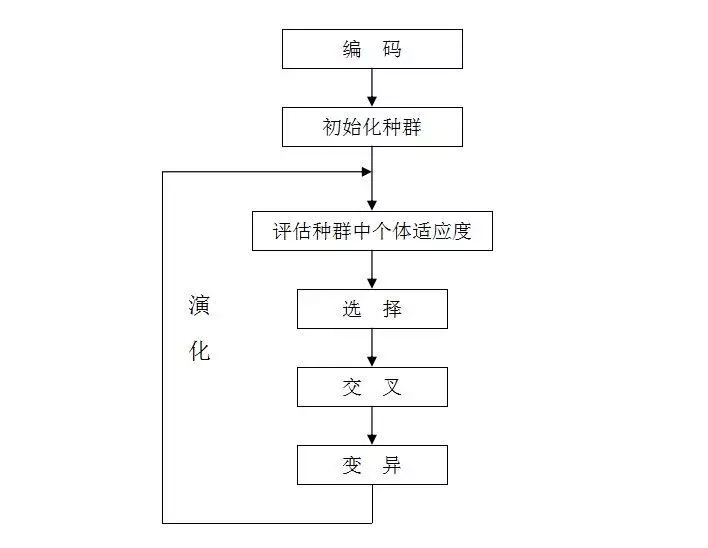
7.提到了训练时使用4折交叉验证
https://blog.csdn.net/weixin_39183369/article/details/78953653(讲的不错)
针对数据量不够大的情况,K折交叉验证。
8.接下来就去做PPT了。