转自:https://docs.python.org/3/library/urllib.parse.html
1.urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)
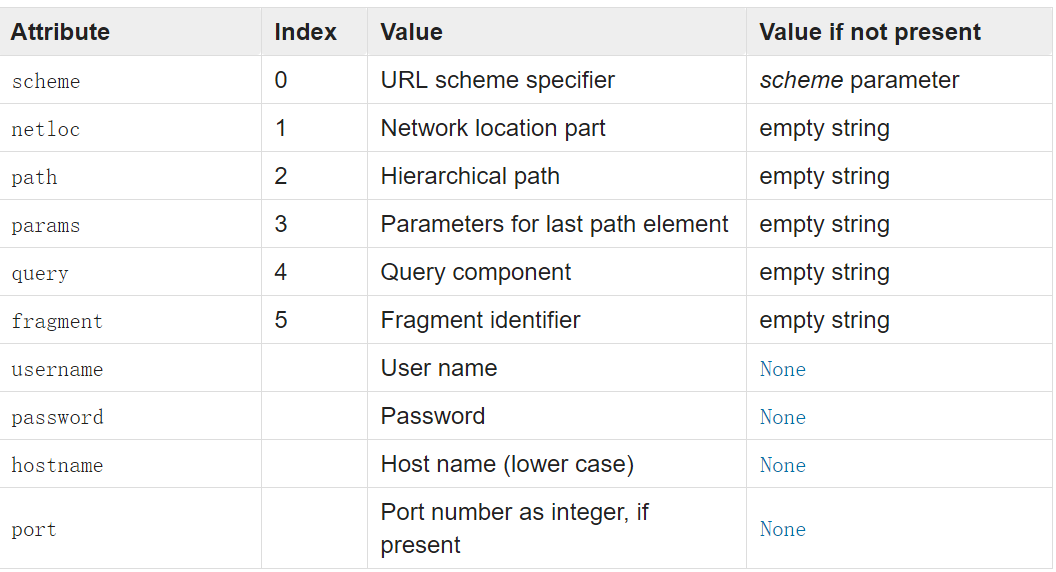
可以将一个网址解析为6个部分,这对应着一个url的通用结构:scheme://netloc/path;parameters?query#fragment
>>> from urllib.parse import urlparse >>> o = urlparse('http://www.cwi.nl:80/%7Eguido/Python.html') >>> o ParseResult(scheme='http', netloc='www.cwi.nl:80', path='/%7Eguido/Python.html', params='', query='', fragment='')