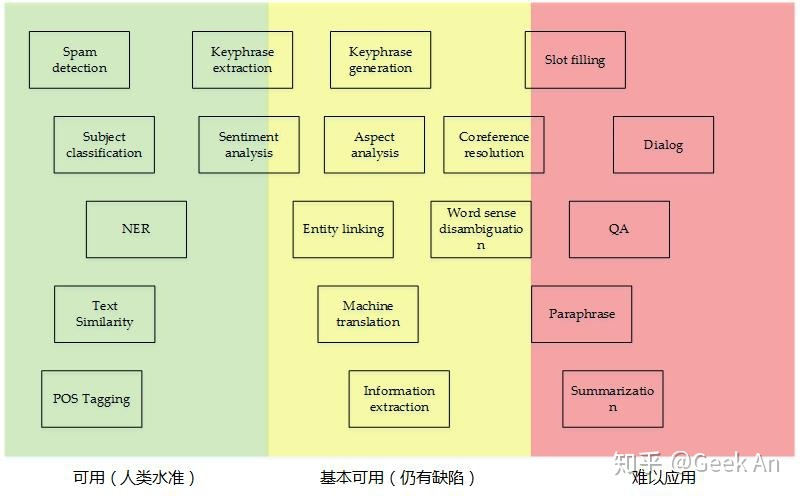
可用水准:垃圾邮件检测,主题分类,命名实体识别,文本相似度,词性标注。
可用与基本可用之间:关键短语提取,情感分析。
基本可用:关键短语生成,方面分析?,实体链接,词义消歧,机器翻译,信息提取
基本与难以之间:槽填充?,指代消解,对话,问答,释义,总结。
2020-2-23更新————————
转自:https://zhuanlan.zhihu.com/p/56802149
1.发展历程。
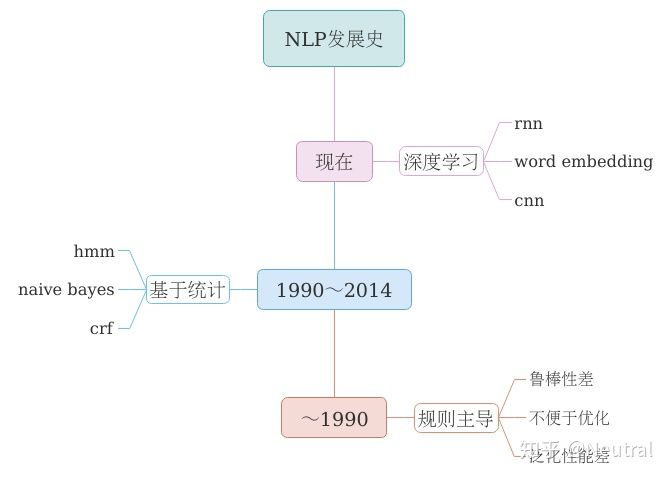
以前主要是专家规则,用规则去匹配,比如说在word文档中搜寻单词,就是使用word,包括正则表达式,当然现在也在用,缺点是泛化性能差,且规则的置顶需要耗费人力物力时间;
之后就是基于统计机器学习,包括马尔可夫,贝叶斯,CRF条件随机场等,这个从数据中学习,但基本上需要人工定制特征,所以也是学习的过程复杂;
目前发展起来的是基于深度学习的,包括RNN,LSTM,词嵌入啊等等技术。
2.任务分类
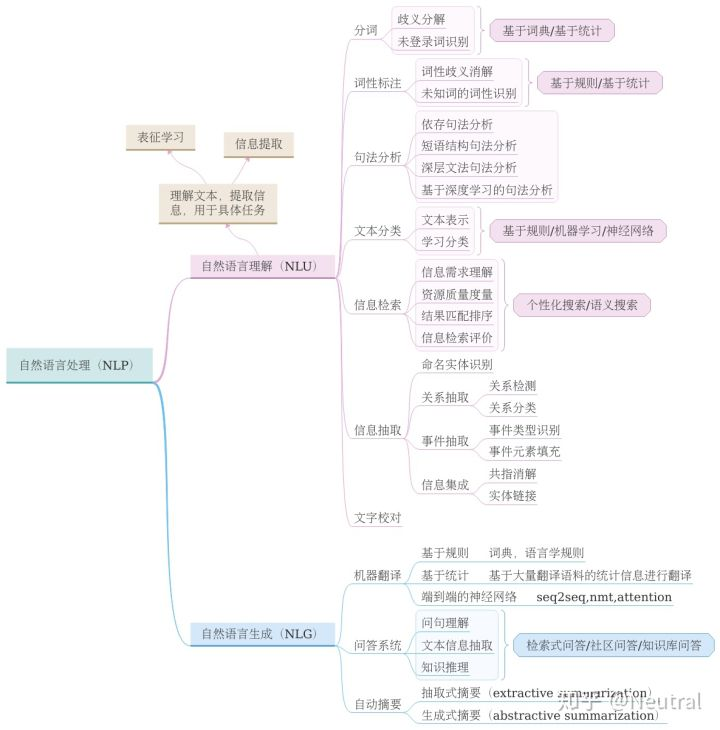
# 我感觉自然语言生成太高深了,我还是选择自然语言理解吧,选择关系抽取任务吧。。。
3.热点技术

对预训练模型,现在的transformer很火;将知识引入,也就是知识图谱吧引入到方法中;迁移学习也是在很多领域都用的;半监督学习等需要很少的数据,然后加入更多的知识。
4.常用工具
转自:https://www.jianshu.com/p/52a933eb64a6
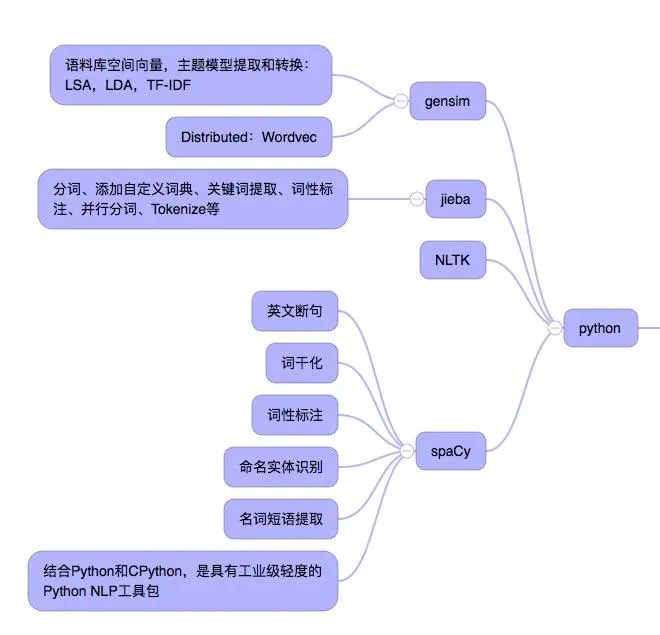
我觉得这个部分是我需要关注的,本科毕设的时候我都是自己手写处理的代码,简直太弱智了。