转自:https://github.com/icrtiou/Coursera-ML-AndrewNg
1.源码-对数据读取
import numpy as np import pandas as pd def get_X(df): """ use concat to add intersect feature to avoid side effect not efficient for big dataset though """ ones = pd.DataFrame({'ones': np.ones(len(df))})#返回某一长度的全为1的array,这是一个字典 data = pd.concat([ones, df], axis=1) # column concat #按列合并,加上一列1,为b使用 return data.iloc[:, :-1].as_matrix() # this return ndarray, not matrix,选取最后一列作为多维数组返回 def get_y(df): '''assume the last column is the target''' return np.array(df.iloc[:, -1])#选最后一列 def normalize_feature(df): """Applies function along input axis(default 0) of DataFrame.""" return df.apply(lambda column: (column - column.mean()) / column.std())
1.pandas数据结构Series
转自:https://www.cnblogs.com/linux-wangkun/p/5903380.html
1.1生成指定Series对象

默认的索引是从0开始。
1.2 生成指定索引
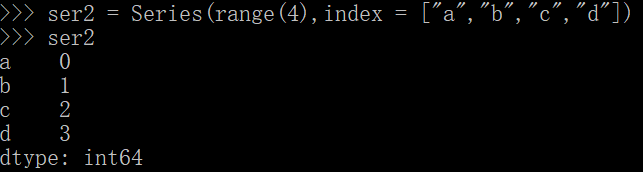
//还有其他的一些知识点,根据字典创建以及自动对齐操作等。
2.pd中的concat函数
转自:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.concat.html?highlight=concat
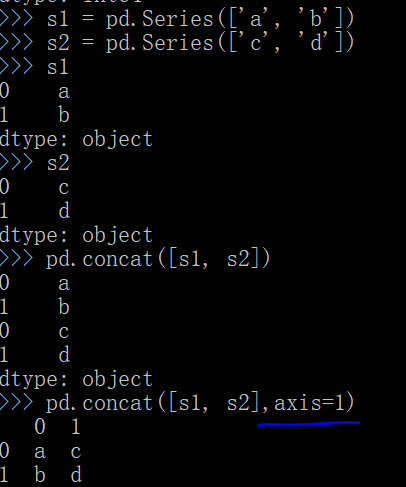
concat函数就是对两个对象进行拼接,默认的axis是0,有点像R中的rbind函数(按行合并),默认是按行合并;
若axis为1,那么即按列合并。
//讲的挺详细的,还有合并两个列名分别相同的数据框,如果列名不完全一样,则用NA补齐。
2.1 内连接

通过join=inner进行内连接合并,对有相同列名的进行合并,然后返回。
join=outer则是取并集,上面是取交集。

3.data.iloc与loc函数
转自:https://blog.csdn.net/llx1026/article/details/77722608
import numpy as np import pandas as pd df = pd.DataFrame(np.arange(0,60,2).reshape(10,3),columns=list('abc')) 结果df: a b c 0 0 2 4 1 6 8 10 2 12 14 16 3 18 20 22 4 24 26 28 5 30 32 34 6 36 38 40 7 42 44 46 8 48 50 52 9 54 56 58
其中loc是索引是字符串时使用,iloc是索引是数字时使用,可以实现数据切片。

注意使用df.loc如果取列的话,需要是[:,'列名'],如果直接df.loc['b']报错。
df.loc[0:3, ['a', 'b']]#取出0,1,2,3行的a,b两列, #如果只取一列那么就这样写df.loc[0:3, 'a'] #如果取多列,那么要把列用[]放在一起如df.loc[0:3, ['a', 'b']] 输出: a b 0 0 2 1 6 8 2 12 14 3 18 20
#不想抽取连续的行和列,那么就需要用[]把要取的行和列都列出来 #如下 df.loc[[1, 5], ['b', 'c']]或df.loc[[1, 5]][['b', 'c']]
如果嫌列名太长,则使用iloc
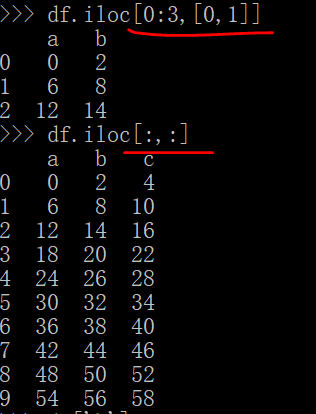
下面的是取全部的行和列。
另一种格式,用这个的话会十分省代码:
还有一种就是如下的格式,意思是取出df中第a列中元素等于6的那一行的b列和c列:
df.loc[df['a'] == 6][['b', 'c']]
//厉害了。
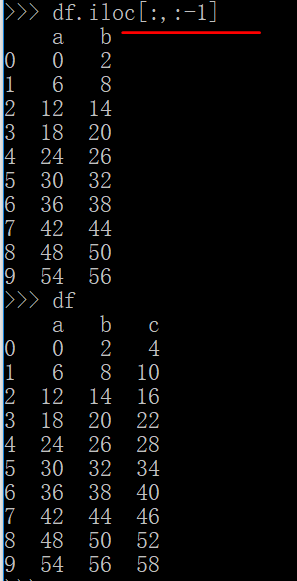
//这一句的意思就是,取所有行,并且列怎么取?-1这里表示最后一列,也就是除去最后一列。