摘要
CNN由于卷积操作的局部性,难以学习全局和长范围的语义信息。交互。 提出swin-unet,是一个像Unet的纯transformer,用于医学图像分割。采用层级的带移动窗口的swin transformer作为编码器,提取上下文特征。一个对称的、带有patch展开层的、基于swin-transformer的解码器用于上采样操作,恢复特征图的空间分辨率。 在直接下采样输入和上采样输出4倍时,在多器官和心脏分割任务上证明,提出的网络超过了全卷积或卷积和transformer的结合方法。模型和代码将公开在:https://github.com/HuCaoFighting/Swin-Unet
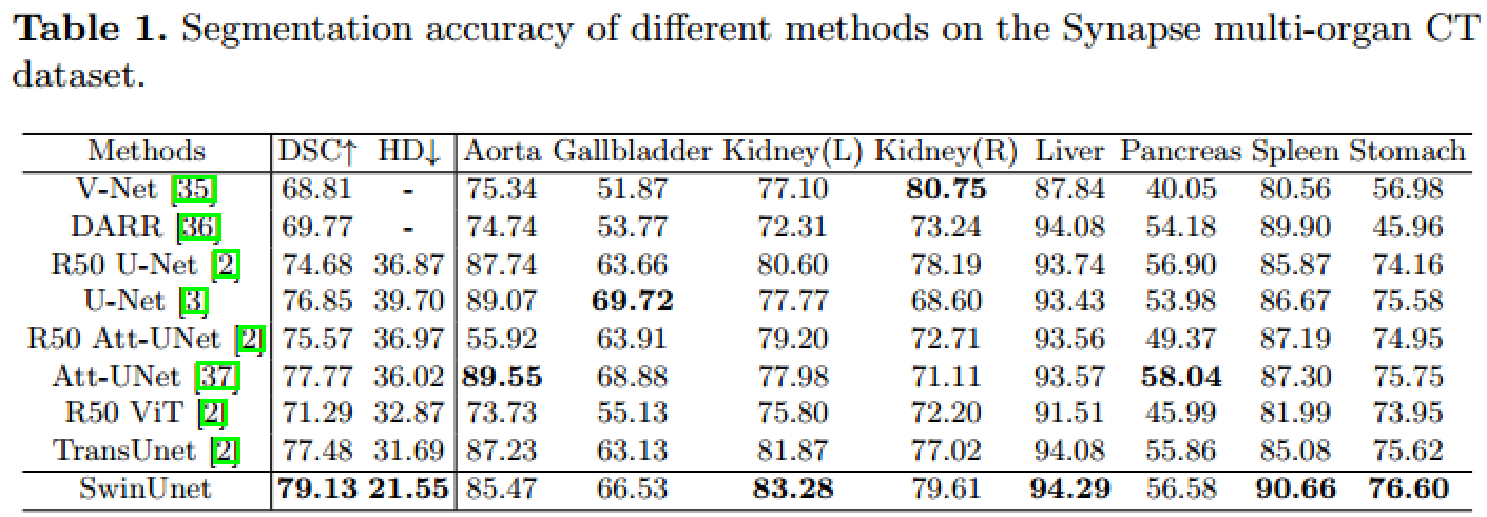
方法
结构概览
- patch大小为4x4,因此每个patch的特征维度是4x4x3=48,之后应用线性嵌入层投影特征维度到任意维度(表示为C)。
- 转换的patch token经过几个swin transformer块和patch合并层,以产生层级特征表示。patch合并层用于下采样和升维,swin transformer块用于特征表示学习。
- 受unet启发,设计对称的基于transformer的解码器,由swin transformer块和patch扩展层组成。提取的上下文特征通过跳跃连接于编码器的多尺度特征融合,以补偿下采样造成的空间信息损失
-
相比于patch合并层,一个patch扩展层变形毗邻维度的特征图到一个2倍上采样的大特征图。最后的patch扩展层用于直径4倍的上采样,以恢复特征图的分辨率到输入大小(wxh),然后线性投影层用于这些上采样的特征,输出像素级别的分割预测
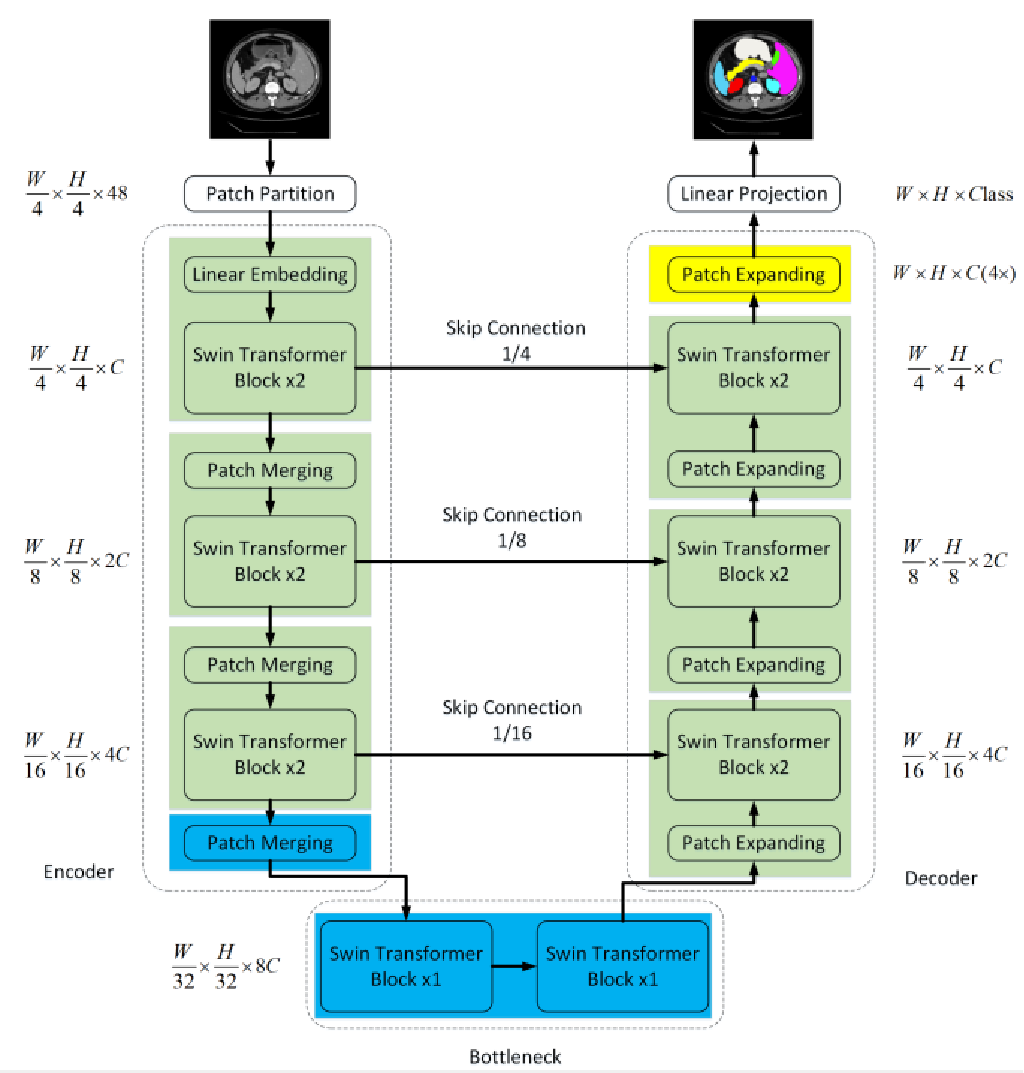
swin transformer块
swin transformer基于移动窗口构建,图2中展示了两个连续的swin transformer块,

每个swin transformer块由LN层、多头注意力模块、残差连接和2层的带有GELU的MLP组成。基于窗口的多头注意力(W-MSA)和基于移动窗口的多头自注意力模块(SW-MSA),用于后续的两个transformer块。基于这个窗口切分机制,连续的swin transformer块可以表示为:
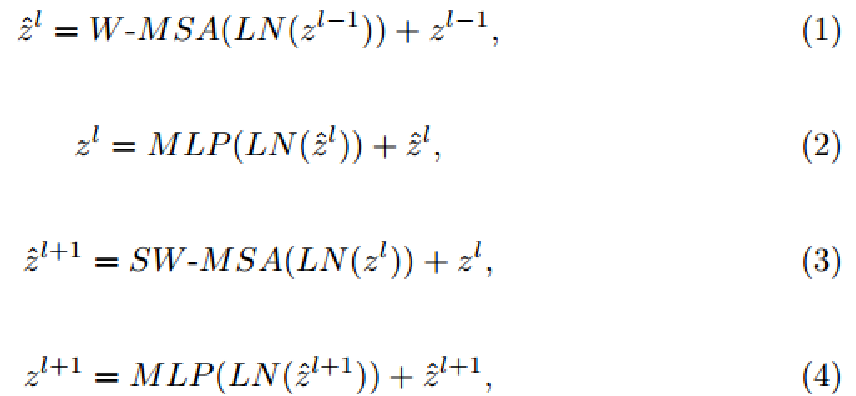
自注意力计算方法为:
![]()
M2代表patch数量,d代表q或k的维度。B中的值来源于偏置矩阵。
Encoder
- C维的分辨率维H/4 x W/4的标记化输入输入到两个连续的Swin Transformer块中进行表示学习,特征维度和分辨率不变。同时,patch合并层将缩减token的数量(2倍下采样),提升特征维度到原始维度的2倍。这个步骤在编码器中重复3次。
- patch合并层:输入patch分成4部分,通过patch合并层拼接在一起,采用这个过程,特征分辨率将下采样2倍,因为拼接操作导致特征维度提升4倍,一个线性层用于拼接的特征,将特征维数统一为2×原始维数
BottleNeck
只有两个连续swin transformer块用于构建bottleneck,学习深度特征表示,bottleneck中特征维度和分辨率不变
Decoder
- 基于swin transformer块构建,在解码器中采用patch扩展层,用于删改杨提取的特征,patch扩展层将相邻维度的特征图变为更高分辨率(2倍上采样),维度数量减半。
- patch 扩展层:以第一个patch扩展层为例,上采样前,一个线性层应用到输入特征(W/32 x H/32 X 8C)以增加特征维度到原来的2倍(W/32 x H/32 X 16C)。然后,采用重排操作,扩展原输入特征的分辨率2倍,同时缩减特征维度到输入维度的1/4(W/32 × H/32 × 16C -> W/16 × H/16 × 4C)
Skip Connection
将浅层特征和深度特征拼接到一起,以缩减下采样引起的空间分辨率损失。后跟1个线性层,拼接的特征维度与上采样的特征维度相同
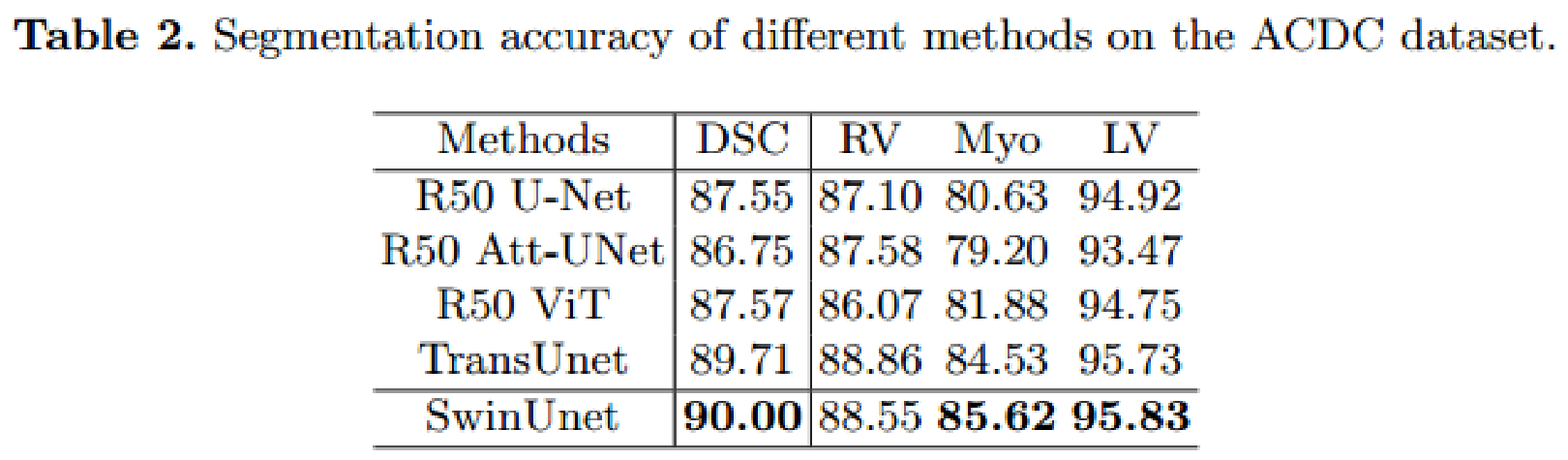
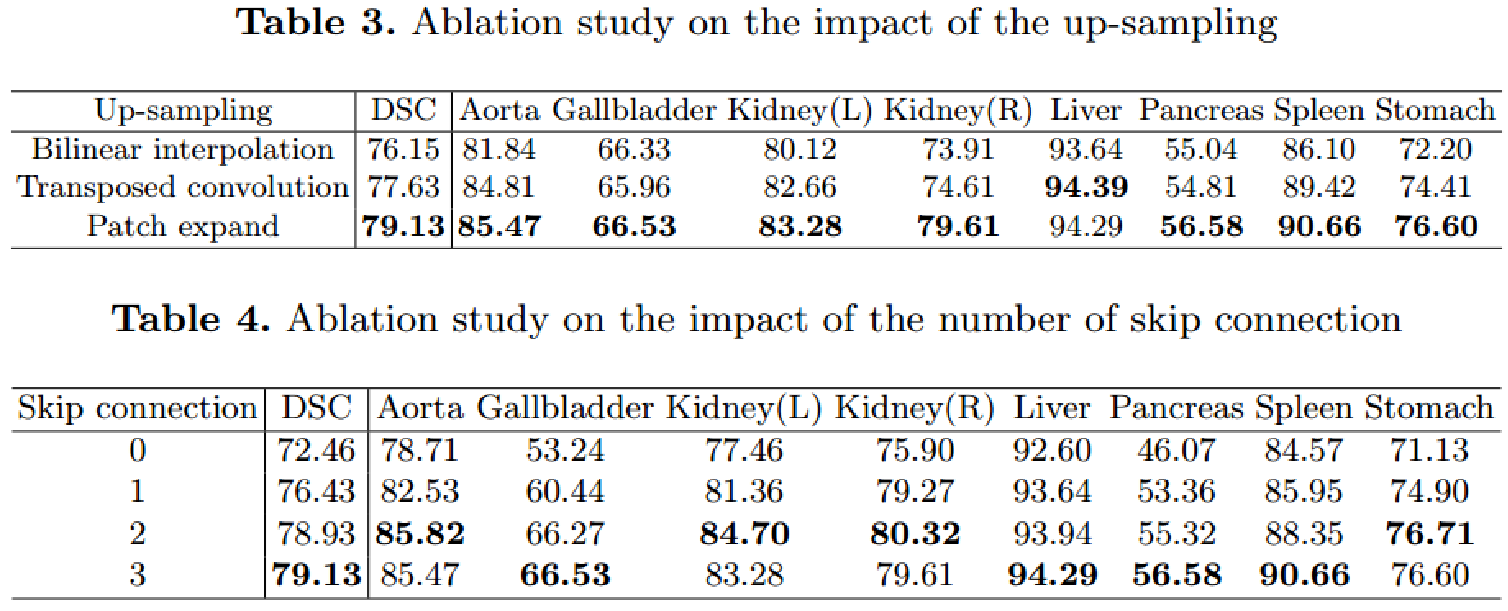
实验