原文:https://blog.csdn.net/prdslf001001/article/details/78615823
1、位:
数据存储的最小单位。每个二进制数字0或者1就是1个位;
2、字节:
8个位构成一个字节;即:1 byte (字节)= 8 bit(位);
1 KB = 1024 B(字节);
1 MB = 1024 KB; (2^10 B)
1 GB = 1024 MB; (2^20 B)
1 TB = 1024 GB; (2^30 B)
3、字符:
a、A、中、+、*、の......均表示一个字符;
一般 utf-8 编码下,一个汉字 字符 占用 3 个 字节;
一般 gbk 编码下,一个汉字 字符 占用 2 个 字节;
4、字符集:
即各种各个字符的集合,也就是说哪些汉字,字母(A、b、c)和符号(空格、引号..)会被收入标准中;
5、编码:
规定每个“字符”分别用一个字节还是多个字节存储,用哪些字节来存储,这个规定就叫做“编码”。(其实际是对字符集中字符进行编码,即:每个字符用二进制在计算中表示存储);
通俗的说:编码就是按照规则对字符进行翻译成对应的二进制数,在计算器中运行存储,用户看的时候(比如浏览器),在用对应的编码解析出来用户能看懂的;
(1)标准ASCii字符集:有96个打印字符,和32个控制字符组成;一共96+32=128个;
用7位二进制数来对每1个字符进行编码;
而由于7位还还不够1个字节,而电脑的内部常用字节来用处理,每个字节中多出来的最高位用0替代;
0 000 0000.........................0
0 111 1111..........................127; 从0----127,来表示128个ACSii编码;
比如:字符 'A'----------在计算器内部用0100 0001 (65)来表示;
字符'a'-----------在计算器内部用0 110 0001 (97)来表示;
注意:'10'在计算器内部是没有编码的,因为它是字符串,而不是单个字符。可以分别对1,0字符编码存储;
(2)扩展ASCii字符集:将标准的ASCii最高位1,得到十进制代码128---255(1 000 0000----1 111 1111);所以字符集一共有0---255, 256个字符;
(3)gb2312字符集: 所有汉字字符在计算机内部采用2个字节来表示,每个字节的最高位规定为1【正好与标准ASCii字符(最高位是0)不重叠,并兼容】,不支持繁体字;
所以:gb2312表示汉字的编码为:[129--255][129--255] (两个字节,每个字节最高位是1);小于127的字符,与ASCii编码相同;
(4)gbk字符集:gb2312的扩充,兼容gb2312,除了收录gb2312所有的字符外,还收录了其他不常见的汉字、繁体字等;
gbk中字符是一个或两个字节,单字节字符00--7F(0---127)这个区间和ASCII是一样的;
双字节字符的第一个字节是在81--FE(129--254)之间。通过这个可以判断是单字节还是双字节;
即:在gbk字符编码,如果第一个字节是>128的,则再往后找一个字节,组成汉字;如果第一个字节<128,则表示的是一个单字节(此时和ASCII是一样的);
- <?php
- // gbk编码下,无乱码截取中文字符;
- // 方法1:自定义函数1;
- function subgbk($str,$lens){ // 形参 $str 表示将要截取的原始字符串, $lens 表示 设定需要截取的 字符 个数;
- if($lens<=0){
- return '';
- }
- $chars = 0; // 计算,统计已经截取的字符个数;
- $res = ''; // 已经截取的字符长度;
- $offset = 0; // 偏移量,从字符串中那个字节开始截取;
- $lengths = strlen($str); // 将要截取的原始字符串 字节 的数;
- while($chars<$lens && $offset<$lengths){
- $hight = ord(substr($str,$offset,1)); // 计算出 gbk字符中 高字节的所对应编码的值;
- if($hight>128){
- // 截取两个字节,代表一个字符;即:双字节字符;
- $count = 2;
- }else{
- //截取一个字节,代表一个字符,即:单字节字符;
- $count = 1;
- }
- $res .= substr($str,$offset,$count);
- $offset += $count;
- $chars++;
- }
- return $res;
- }
- ?>
- <?php
- // 方法2:自定义函数2;
- // 思路:先把字符串中 所有的 字符 逐一取出来 组成数组,然后对 数组元素 进行截取;最后截取出的数组拼接成想要的字符串;
- function strgbk2($str,$strat,$length=NULL){ // 第三个参数默认设置的值是NULL,这个参数是参考了下边的array_slice()函数,如果省略的话,则表示,一直截取到最后末尾;
- $zijielen = strlen($str); // 计算出 原始字符串 $str 的 字节长度;
- $chars = 0; // 统计计算截取的 字符 数;
- $zifuarr = array(); //将字符串按照 字符 的形式 分割到 数组中;(待存储);
- for($i = 0;$i<$zijielen;){ // $i 表示 原始字符串 $str 中的字节(标记);
- if(ord(substr($str,$i,1)) > 128){
- // 双字节字符,两个字节来表示一个字符;
- $zifuarr[] = $str[$i].$str[$i+1];
- // $zifuarr[] = substr($str,$i,2); 两种写法的意思是一样的,都是 取得 某个字符 某些的 字节;
- $i += 2;
- }else{
- // 单字节字符,一个字节表示一个字符;
- $zifuarr[] = $str[$i];
- // $zifuarr[] = substr($str,$i,1); 两种写法的意思是一样的,都是 取得 某个字符 某个的 字节;
- $i++;
- }
- $chars++; // 每次循环,相当于截取一个存储 字符; 相当于所有的数组元素个数 count($zifuarr);
- }
- if($chars < $strat){ // 当偏移 过 字符 总长度时候;(开始截取的位置,已经超过了字符的总长度);
- return 'No characters have been found !';
- }
- return implode(array_slice($zifuarr,$strat,$length)); // array_slice()是截取数组一部分;implode()是将截取出来的字符串,链接起来;
- }
- ?>
- <?php
- // 方法3:用php内置的函数 mb_substr截取;
- //此函数和 mb_strlen()函数一样,都是针对 多字节 字符 的操作函数,在特定的编码下,针对 字符 的 截取(mb_substr)和长度的计算(mb_strlen);
- $strgbk = 'ds我是fdg一个中国xghdt人';
- echo mb_substr($strgbk,2,3,'gbk'); // 我是f
- ?>
(5)Unicode字符集:容纳世界上所有语言字符和符号的集合;(以及对应的二进制数字);
Unicode只是一个编码规范,目前实际实现的unicode编码只要有三种:UTF-8,UCS-2和UTF-16,三种unicode字符集之间可以按照规范进行转换。
(6)utf-8编码:UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字的应用中,优先采用的编码。
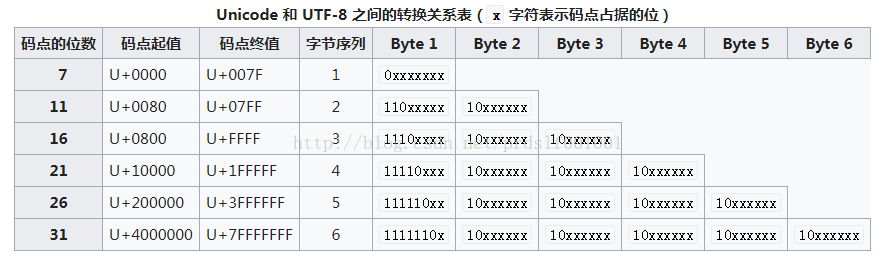
对于UTF-8编码中的任意字节B,如果B的第一位为0,则B独立的表示一个字符(ASCII码);
如果B的第一位为1,第二位为0,则B为一个多字节字符中的一个字节(非ASCII字符);
如果B的前两位为1,第三位为0,则B为两个字节表示的字符中的第一个字节;
如果B的前三位为1,第四位为0,则B为三个字节表示的字符中的第一个字节;
如果B的前四位为1,第五位为0,则B为四个字节表示的字符中的第一个字节;
因此,对UTF-8编码中的任意字节,根据第一位,可判断是否为ASCII字符;根据前二位,可判断该字节是否为一个字符编码的第一个字节;根据前四位(如果前两位均为1),可确定该字节为字符编码的第一个字节,并且可判断对应的字符由几个字节表示;根据前五位(如果前四位为1),可判断编码是否有错误或数据传输过程中是否有错误。
即:
1、单字节的字符,字节的第一位设为0,对于英语文本,UTF-8码只占用一个字节,和ASCII码完全相同;
2、n个字节的字符(n>1),第一字节的前n位设为1,第n+1位设为0,后面字节的前两位都设为10;
3、2个字节,第一个字节的前2位是1;3个字节,第一个字节的前三位是1; 4个字节,第一个字节的前4位都是1;
// 如何截取中文,无乱码,假设utf-8编码;
- <?php
- // 方法1:自定义函数;
- function subutf8($str,$len){ // 两个形式参数,$str代表原始目标字符串,$len表示需要截取 字符 的个数; 注意是 字符的 个数;
- if($len<=0){ // 当 将要截取的字符数 <=0的时候 返回 空字符串;
- return '';
- }
- $chars = 0 ; // $chars 参数 代表 已经截取的字符的个数, 默认初始设置为0;
- $res = ''; // $res 参数 表示 已经截取的字符串的长度, 默认初始设置为空(字符串);
- $offset = 0; // $offset 参数 表示 字节 截取的偏移量; 即从字符串中(偏移几个字节)哪个字节开始截取;
- $lengths = strlen($str); // $lengths 参数 表示 原始整个字符串的 字节的长度; 而应保证 $offset < $lengths; 否则都无字符可截取;
- while($chars<$len && $offset < $lengths){ // $chars<$len; 应是< 而不是<= ;因为是从0开始的,并执行循环截取的;
- $higher = decbin(ord(substr($str,$offset,1))); // 计算出 一个字符 中 第一个字节(高字节)的二进制;
- if(strlen($higher) < 8){ // decbin()函数 转换出来的 二进制数 如果 <128(10000000) 的时候,即是二进制长度<8位的时候,前面高位不默认补0;
- // 截取一个字节;(表示一个字符);
- $count = 1;
- }else if(substr($higher,0,3) == '110'){
- //截取两个字节(表示一个字符);
- $count = 2;
- }else if(substr($higher,0,4) == '1110'){
- //截取三个字节(表示一个字符);
- $count = 3;
- }else if(substr($higher,0,5) == '11110'){
- //截取四个字节(表示一个字符);
- $count = 4;
- }else if(substr($higher,0,6) == '111110'){
- //截取五个字节(表示一个字符);
- $count = 5;
- }else if(substr($higher,0,7) == '1111110'){
- //截取六个字节(表示一个字符);
- $count = 6;
- }
- $res .= substr($str,$offset,$count);
- $offset += $count;
- $chars++;
- }
- return $res;
- }
- ?>
- <?php
- //方法2:使用系统函数截取
- mb_substr(),不会乱码.例:
- $str = '换s几ss个字实现中文字串截取无乱码的方法。';
- echo mb_substr($str,0,5,'UTF-8');// '换s几ss'
- ?>php
- // 中文字符串实现反转;
- $a = '我是一个好人';
- function strrevv($str) {
- $strlen = mb_strlen($str,'UTF-8');
- $arr = array();
- for($a=0;$a<=$strlen;$a++) {
- $arr[] = mb_substr($str,$a,1,'UTF-8');
- }
- $newstr = implode('',array_reverse($arr));
- return $newstr;
- }
- echo strrevv($a);
- // mb_strlen(str,utf-8); 字符串中字符的个数;
- // mb_substr(str,start,length,utf-8); 多字节字符的截取;
- // mb_strpos(str,needle,offset,utf-8);查找子字符串,在字符串中出现的位置;
- // mb_substr_count(str,needle,utf-8);统计子字符串,在字符串中出现的次数;