作者: Dominik Moritz, Bill Howe, Jeffrey Heer
发表于CHI 2019, 三位作者都来自于University of Washington Interactive Data Lab
项目代码:https://github.com/uwdata/falcon
简介
Linked Visualization(链接可视化系统)是通过刷选、放缩等操作,在不同可视化视图上进行交互,链接(link)不同视图的操作,并更新视图的一种可视化方式。为了支持有效的探索,Linked Visualization必须提供快速响应来消除延迟敏感。在百万级以上的数据量时,传统可视化方法无法实现实时的探索,引出一系列问题。
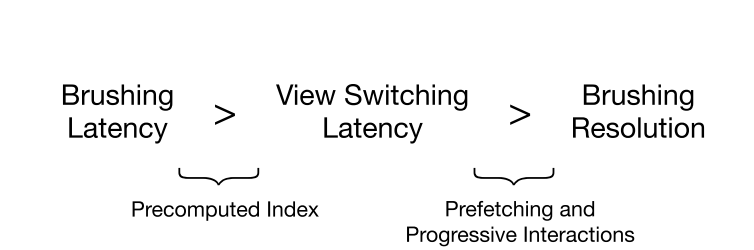
本文提出falcon,一个大数据Linked Visualizations的低延迟方案,实现对十亿数据集的冷启动探索。falcon平衡交互延迟和视图精度,从查询和界面系统两方面对Linked Visualizations进行优化,降低刷选和链接(brushing and linking)的延迟。结合数据索引,数据预取和渐进式交互等方法,falcon系统使用加载数据子索引来优化刷选延迟,通过逐步加载交互式分辨率,以减少视图切换时间。实验表明,falcon实现了50fps的刷选交互延迟,无需昂贵的预计算和存储代价。
相关工作
- Linked Visualization在商用可视化软件,如tableau, powerBI, DataV中应用非常广泛。他们经常使用直方图作为可视化方式,辅以brushing and linking 作为交互手段,让用户在展示不同维度的视图之间交互式刷选部分子集,同时在其它视图间同步展示子集结果。
- 在论文The effects of interactive latency on exploratory visual analysis(2014 TVCG)中,Liu and Heer指出超过500ms的延迟会对用户行为造成较大影响,用户对刷选(brushing and linking)相比平移(pan)和缩放(zoom)有更高的延迟敏感度。
- 过去的工作采用预处理数据索引或者稀疏数据块的方案来达到加快可视查询和交互的目标,但它们无不会导致高昂的计算和存储代价。这些文章有imMens(2013 EuroVis), Nanocube(2013 VIS)等等。
- falcon分解高维数据索引,分解后它仅支持与单个活动视图的交互,当用户与特定视图交互(active view)时,将其所需部分数据索引进行加载。这样每次交互所需索引的大小在视图数量上是线性的,这避免了维度爆炸。
界面设计
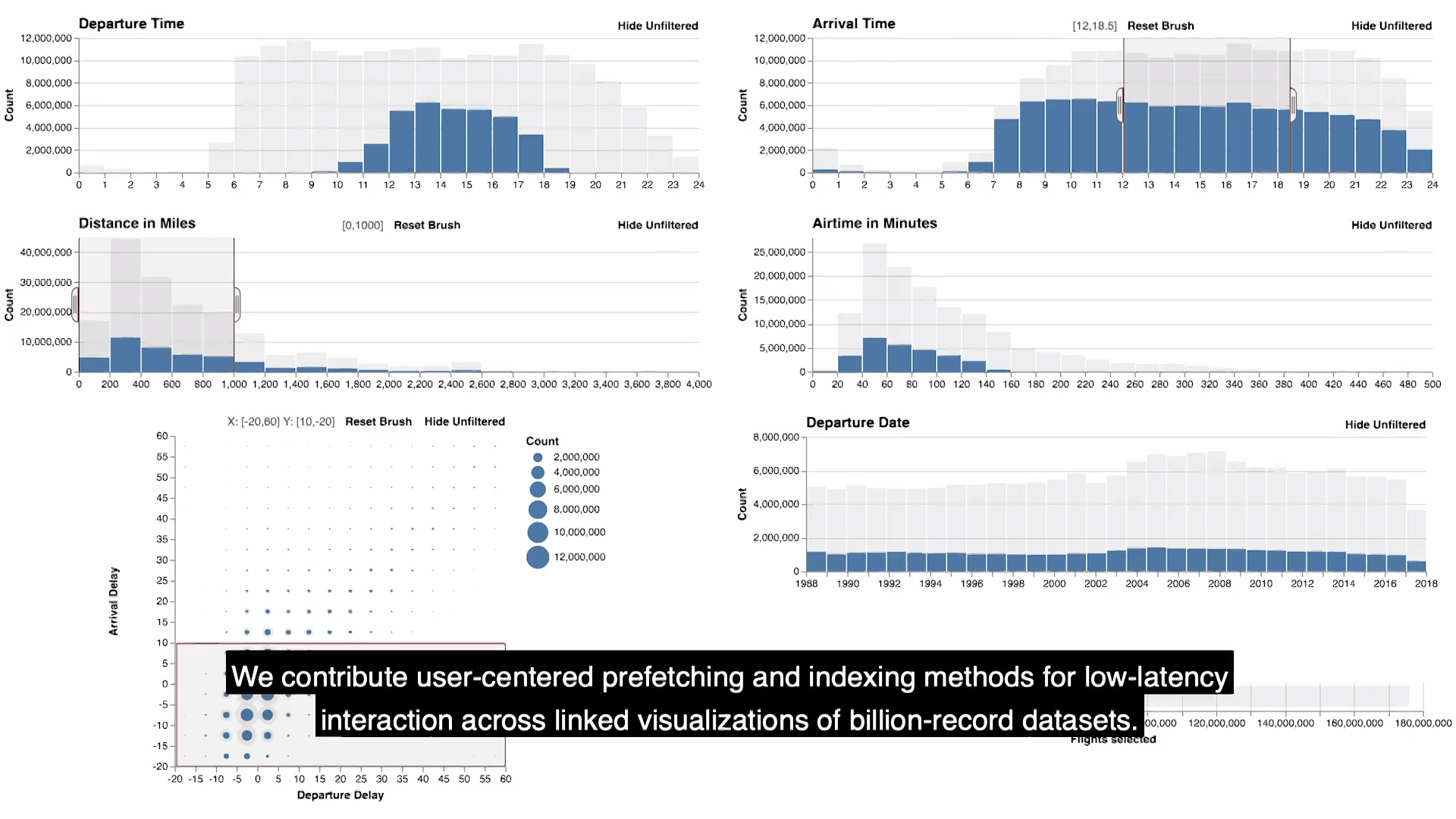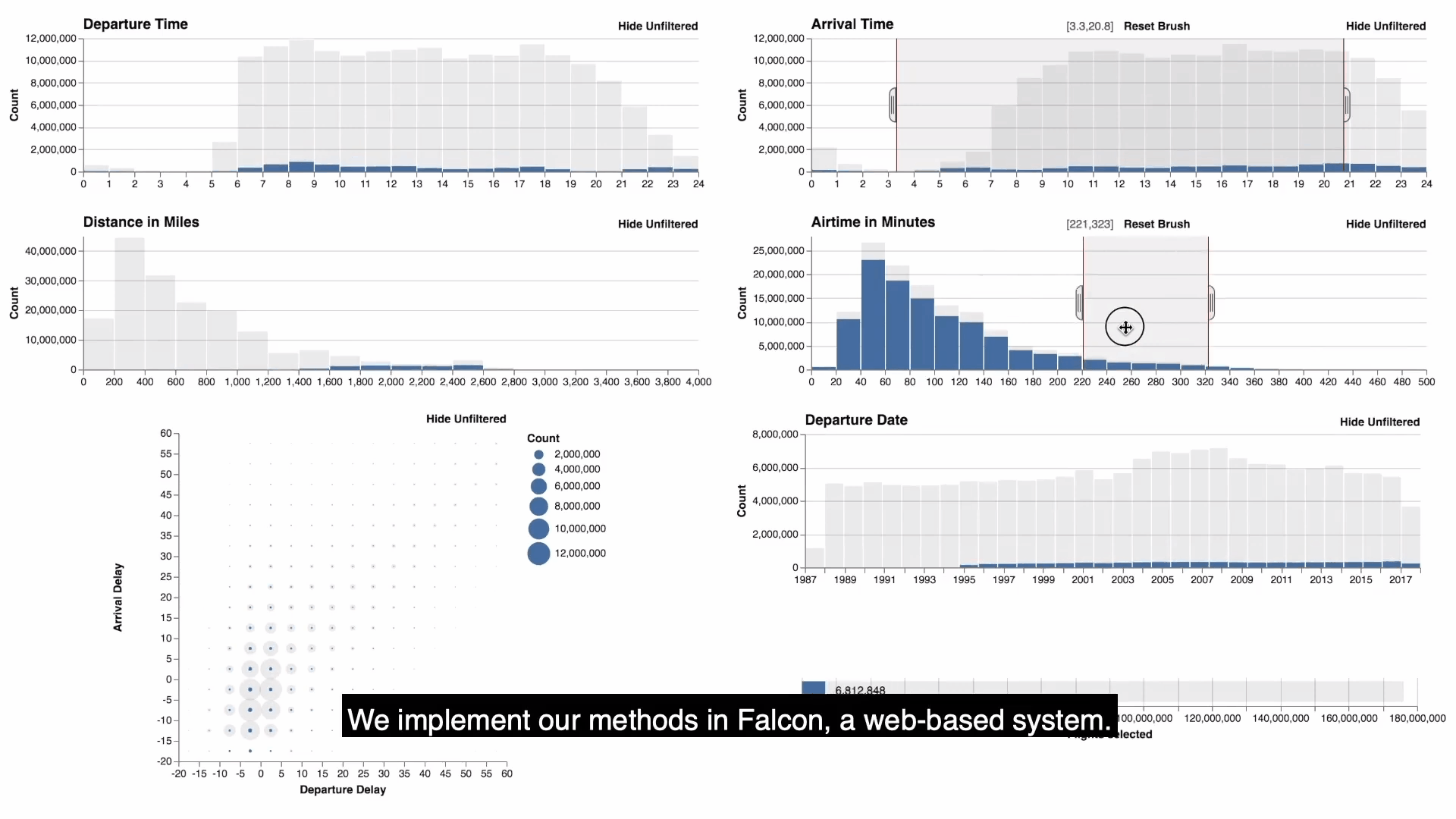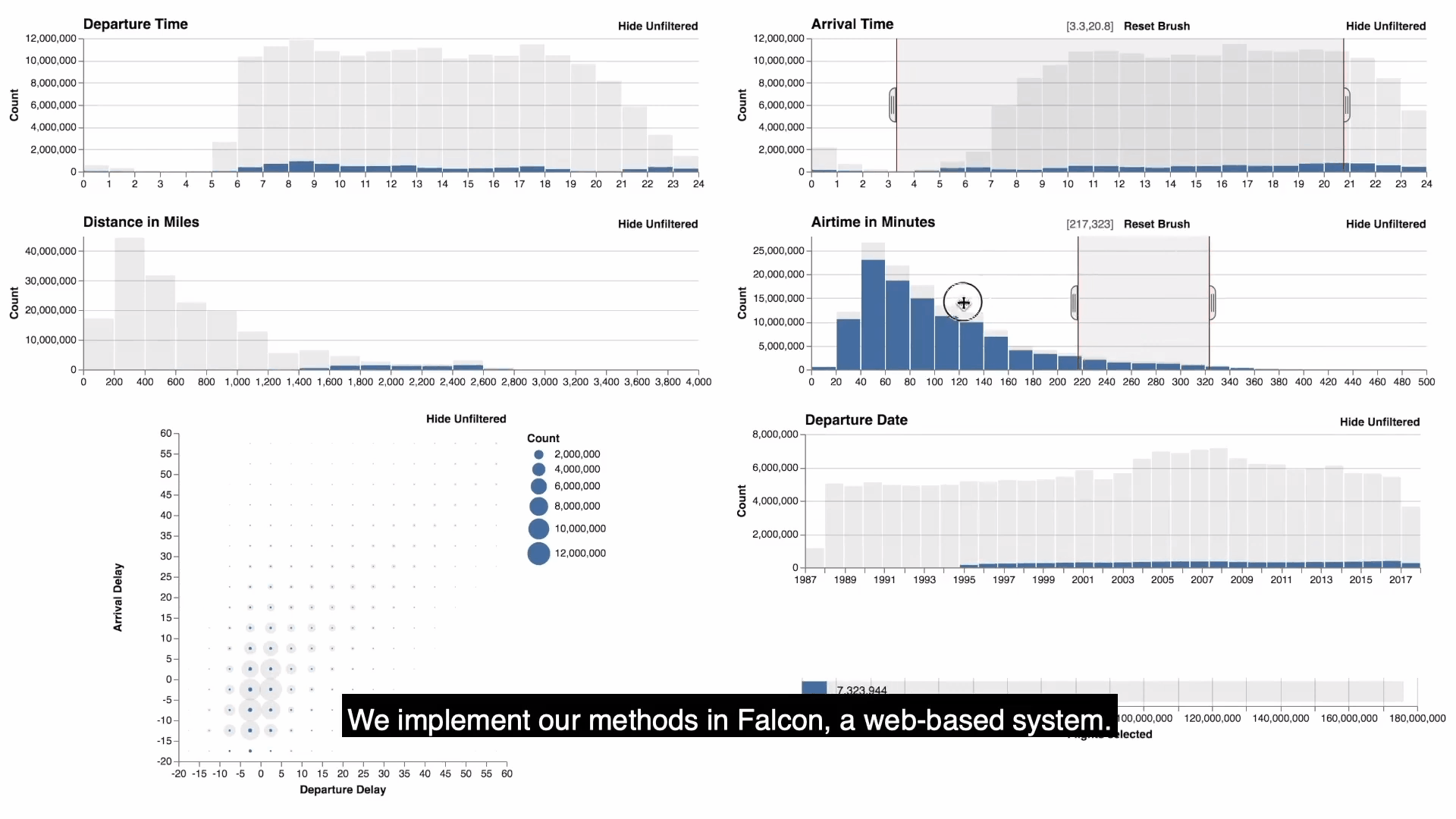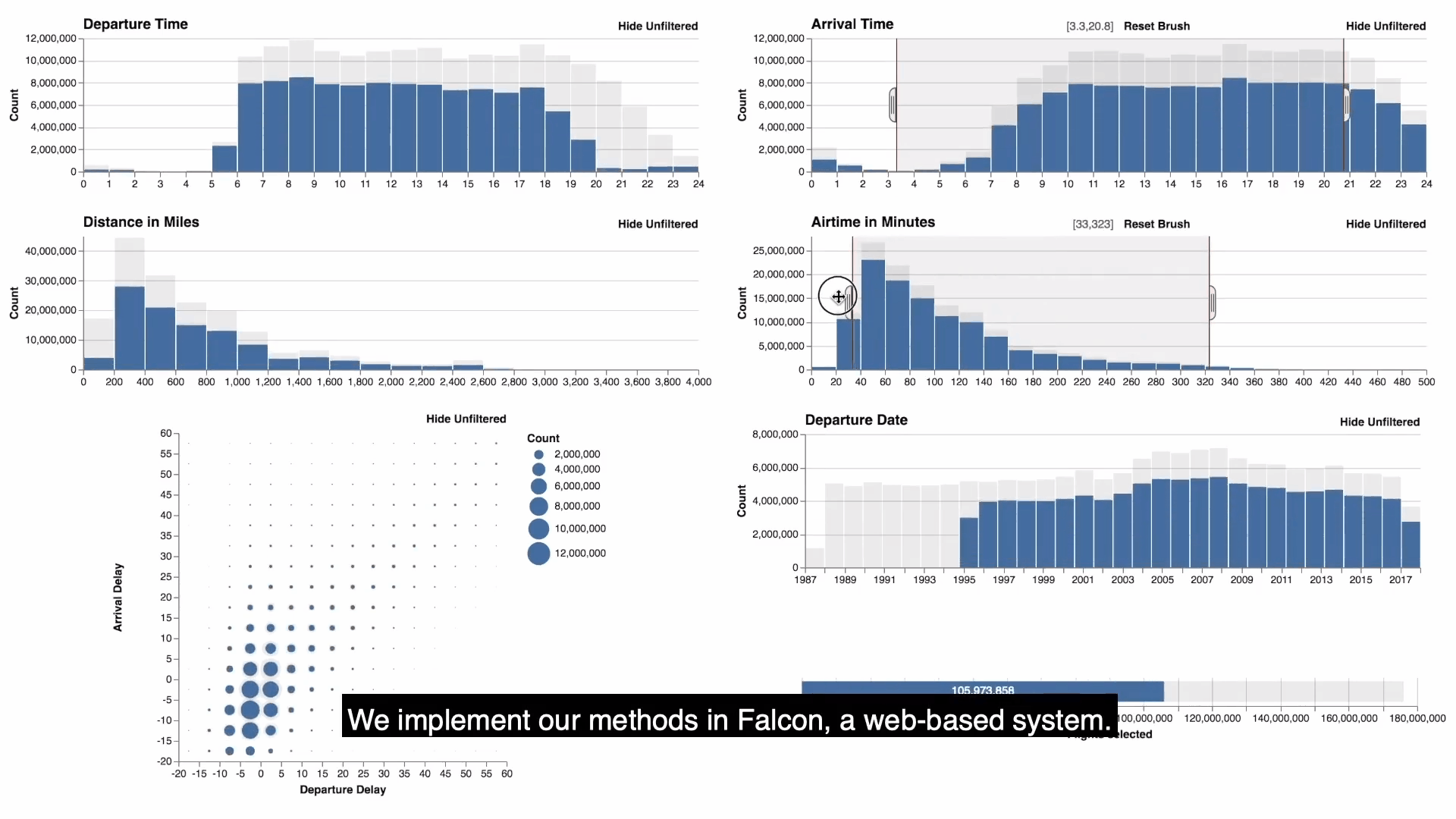
- falcon提供了一个可视化的视图仪表板,具有零,一个或两个维度的直方图。如图显示的是flights数据的可视化结果。每个视图都支持刷选,放缩,平移的功能,通过brushing and linking同步更新所有视图的查询结果,此外还可以通过按钮来选择是否查看没有被过滤的数据。
- 需要注意的是正在刷选的视图是主视图(active view), 其余都是次视图(passive view),上图中鼠标所正在刷选的(第二行第二个)就是active view。
算法与模型
数据索引
大数据可视化系统中,我们常常使用数据索引来存储数据,以此优化后端处理中的时间复杂度和空间复杂度。数据索引又叫data tile, datacube。如下图所示,一个1维的直方图,我们可以使用一个同样长度的数组,每条数据按照维度信息放入相应的数据方格当中,形成数据索引。如果是2维的直方图,同理,我们需要一个2维的数组(一个平面)作为数据索引,此时每个直方图的相应格子就是平面中的某一行或者某一列的和。3维依次类推,是一个立方体,此时每个直方图的相应格子就是立方体中的某个平面的和。
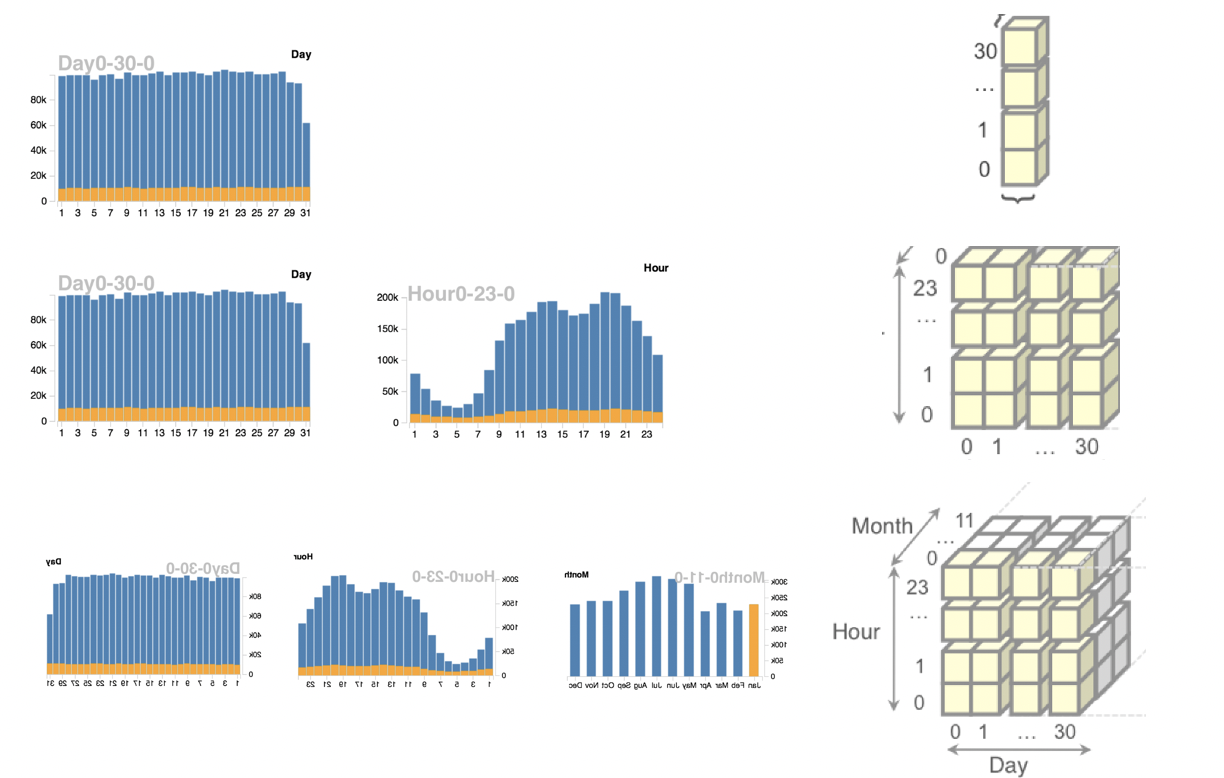
假设数据条数是T, 维度数为m, 每个维度的划分精度为n,那么构建时间复杂度: (O(T)),空间复杂度: (O(n^m)),查询复杂度: (O(n^{m-1}))。可以发现空间复杂度和查询复杂度都随维度呈指数型增长,这样在高维度(多视图)的可视化系统中,存在巨大的维度灾难。针对较高的查询复杂度,我们可以使用sum area table将查询复杂度降到(O(2^m)),但是处理数据索引的空间复杂度依然巨大,当可视化系统的前后端分离的情况下,更会带来巨大的传输延迟和存储负担。
本文针对这个情况提出处理当前刷选窗口(active view)相关的数据子索引的方案,有效减小了空间复杂度,也一并减少了查询复杂度。假设有5个维度,每个维度粒度是10,显示五个单维度的直方图。旧方案需要(O(10^5))的空间复杂度和(O(2^5))的查询复杂度(有sum area table), 只会预处理一次。新方案冷启动无需预处理,每次切换刷选窗口(active view)时需要O(4 * 100)的空间复杂度和仅仅O(4)的查询复杂度。

Falcon 采用两种数据索引的实现方案。一是如果数据量比较小(< (10^6)), 会直接在前端生产高维数据索引, 进行查询。二是如果数据量很大,通过后端的高性能GPU数据库(OmniSci)来生成数据索引。由于falcon只需要当前界面数据子索引的思想,有效减小了响应时间。
延时加载与线性插值
有时计算数据索引需要很长时间,falcon会优先计算粗精度下的数据索引,之后再加载细精度的索引。如果框选范围处于条形图的中间位置,falcon会使用线性插值的方式进行拟合。论文通过实验证明,尽管使用线性插值,真实值和拟合值的Wasserstein distance处于非常小的范围内(99%的情况下< 0.01)。
实验
作者将Falcon与SquareCrossfilter进行了比较,记录了300万条记录的5个视图的刷选实验结果。Falcon的性能是恒定的,接近浏览器的最大帧速率60fp。反观SquareCrossfilter,当向刷选开始和结束过程中,系统会反应缓慢。

此外本文还针对不同数据集进行了测试。下表统计不同数据集大小的所有视图的在切换刷选窗口(active view)的等待时间的平均值,中位数和第95百分位树,分别在像素分辨率(1维为500个bins,2维200×200bins)和bin分辨率(1维25bin和2维25×25bins)下进行统计。测试结果其中包括了网络传输的时间,灰色显示计算第一个视图的传输完成的时间,Browser指只有前端的实现方法,Core指使用GPU数据库作为后端的实现方法。

实验表明:
-
falcon对于只有前端和前后端分离的两种方案,都有显著的性能提升。
-
falcon的框选操作的时长不再取决于原数据量大小,框选精度不再取决于原本数据的最小精度。
-
falcon通过逐步加载和线性插值的方式来减小用户在数据量较大时的不舒适感。
总结
针对大数据Linked Visualizations,本文提出了考虑刷新延迟优先于视图切换延迟,以及降低交互的初始分辨率以改善视图切换时间的方案。基于原型系统falcon,当连接到后端GPU数据库系统时,falcon支持流畅浏览和刷选数十亿条记录,而无需昂贵的预计算或其他内存等方面的限制。但falcon还有许多不足之处,如:
-
falcon只实现了关于求和的功能,并不涉及中位数,平均数等更复杂的计算。也不涉及非数值型数据的计算。
-
默认用户每次只会刷选一个视图,如果用户使用的是触屏设备,这个假设就会被推翻。
-
更注重刷选的操作,对于缩放等操作并没有进行优化和讨论。
-
对于数据索引的处理方面有更多的发挥空间,比如数据压缩,中间件的处理等等。
总之,falcon从一个不同的视角解决了Linked Visualizations的刷选延迟问题,实现了对十亿数据集的冷启动探索。