● 子类调用父类构造函数
|
※ 为什么子类要调用父类的构造函数? 因为子类继承父类,会继承到父类中的数据,所以子类在进行对象初始化时,先调用父类的构造函数,这就是子类的实例化过程。 |
|
MyWidget( QWidget *parent, const char *name ) : QWidget( parent, name )
#include <iostream.h> class animal { public: animal(int height, int weight) { cout<<"animal construct"<<endl; } … };
class fish:public animal { public: fish():animal(400,300) { cout<<"fish construct"<<endl; //这是构造函数fish()的语句 } … };
void main() { fish fh; } |
|
在fish类的构造函数后,加一个冒号(:),然后加上父类的带参数的构造函数。这样,在子类的构造函数被调用时,系统就会去调用父类的带参数的构造函数去构造对象。△子类和父类的构造函数如果有参数, 那么参数不能省略. |
● 子类调用父类构造函数的复杂案例
|
派生子类会继承基类的所有成员,除了构造函数和析构函数。也就是说子类是无法继承父类的构造函数和析构函数的.因此,子类对于从父类继承过来的成员变量,若不想自己写构造函数初始化时,就只能先初始化父类中的成员变量,然后再继承过来。如以下程序中: #include<iostream> #include<string> using namespace std;
class Student { public: Student(int n,string nam,char s) { num=n; name=nam; sex=s; } ~Student(){}
protected: int num; string name; char sex; };
class Student1:public Student { Student1(int n,string nam,char s,int a,string ad):Student(n,nam,s) { age=a; addr=ad; } void show() { } private: int age; string addr; };
int main() { Student1 stud1(10010,"Wang",'f',19,"BeiJing Road,Shanghai"); ...... ...... } |
|
子类Student1中的构造方法只有对新增成员int age和string addr的初始化操作,对于从父类继承过来的成员num,name,sex无初始化语句,但子类又不能继承父类的构造函数,要么就另外再写一个初始化语句,可这样操作就造成了重复性语句, 此时就得通过Student1(int n,string nam,char s,int a,string ad):Student(n,nam,s) {age=a;addr=ad;}先初始化父类成员变量,从而间接初始化子类从父类继承过来的成员变量。 以上是对基类Student及子类Student1的定义。 请注意派生子类构造函数首行的写法: Student1(int n,string nam,char s,int a,string ad):Student(n,nam,s) 其一般形式为: 派生类构造函数名(总参数列表):基类构造函数名(参数列表) { 派生类中新增数据成员初始化语句; } |
● 定义对象(实例)指针 & 指向对象成员的指针
|
一. 定义对象(实例)指针: ① 情况一: 动态对象的指针 Clock *pt = new Clock; //定义对象指针, 该指针指向动态对象,该对象调用默认构造函数Clock() //要注意,这里进行了两次的内存分配,一个是指针pt的存储分配,另一个是实例化A对象的存储分配(由new来完成和返回)
② 情况二: 静态对象的指针 Time t1; Clock *pt = &t1; //定义对象指针, 该指针指向动态对象
※ 如果只有: Clock *pt; 这时编译器是没有分配一个类A的对象的存储空间的,它只是给指针pa分配一个指针的存储空间,你可以把这个指针理解为是没有值的(因为这个指针的存储空间里的值是原来内存中遗留下来的值,对于这个指针来说是没有意义的)。
二. 指向对象成员的指针 ① 指向对象数据成员的指针 Time t1; int *p1; //定义指向整型数据的指针变量 p1=&t1.hour; //将对象t1的数据成员hour的地址赋给p1,p1指向t1.hour cout<<*p1<<endl; //输出t1.hour的值 ② 指向对象成员函数的指针 需要提醒读者注意: 定义指向对象成员函数的指针变量的方法和定义指向普通函数的指针变量方法有所不同。这里重温一个指向普通函数的指针变量的定义方法: 数据类型名 (*指针变量名) (参数表列); 如 void ( *p)( ); //p是指向void型函数的指针变量 可以使它指向一个函数,并通过指针变量调用函数: p = fun; //将fun函数的人口地址传给指针变童p,p就指向了函数fn (*P)( ); //调用fn函数
而定义一个指向对象成员函数的指针变量则比较复杂一些。如果模仿上面的方法将对象成员函数名赋给指针变最P: p = t1.get_time; 则会出现编译错误; 应该采用下面的形式: void (Time::*p2)( ); //定义p2为指向Time类中公用成员函数的指针变量 注意:(Time:: *p2) 两侧的括号不能省略,因为()的优先级高于*。如果无此括号,就相当于: void Time::*(p2()) //这是返回值为void型指针的函数
|
● 多态的进一步理解
|
有A类, 还有A的公有派生类B类, A有虚成员函数func(), B重写了func()函数, 那么: A *pt=new B; 从内存结构来说,B从A派生,就是在A的内存结构的后面,再添加了一些B自己的内容; C++允许基类指针指向派生类. pt->func仍然会调用B的方法 这是通过晚绑定(动态绑定)实现的. |
● 构造函数与初始化列表
|
C++中构造函数后面接单冒号是什么意思? |
|
class TEST { public: int b; int c; int a; TEST(int x, int y):a(x),b(y),c(0){} //带参数的构造函数, 表示用数据成员后括号内的值,来初始化成员变量值 }; //上面类的定义等价于: class TEST { public: int b; int c; int a; TEST(int x, int y) { a=x; b=y; c=0; //c不接受实参, 恒等于0 } }; //需要注意的是,初始化的顺序并不是依赖于a,b,c在初始化列表中出现的顺序,而是与类中定义a,b,c的顺序相同, 即执行构造函数时,实际的初始化顺序为b,c,a,而不是a,b,c. |
● 构造函数后跟冒号的各种情况
|
构造函数后跟冒号的各种情况 |
|
其实冒号后的内容是初始化成员列表,一般有三种情况: 1、对含有对象成员的对象进行初始化,例如, 类line有两个私有对象成员startpoint、endpoint, line的构造函数写成://startpoint、endpoin是非line类的对象 line(int sx,int sy,int ex,int ey):startpoint(sx,sy),endpoint(ex,ey){……} //{……}是构造函数line()的语句 初始化时按照类定义中对象成员的顺序分别调用各自对象的构造函数(即startpoint()和endpoint()),再执行自己的构造函数(即line()) 2、对于不含对象成员的对象,初始化时也可以套用上面的格式,例如, 类rectangle有两个数据成员length、width,其构造函数写成: rectangle():length(1),width(2){} rectangle(int x,int y):length(x),width(y){} 3、对父类进行初始化,例如, CDlgCalcDlg的父类是MFC类CDialog,其构造函数写为: CDlgCalcDlg(CWnd* pParent ): CDialog(CDlgCalcDlg::IDD, pParent) 其中IDD是一个枚举元素,标志对话框模板的ID 使用初始化成员列表对对象进行初始化,有时是必须的,有时是出于提高效率的考虑 |
● this指针进阶
|
#include<iostream> #include<typeinfo> using namespace std; class B; class A; class A { public: void foo() { if(typeid(this)==typeid(A*)) cout<<"A"<<endl; if(typeid(this)==typeid(B*)) cout<<"B"<<endl; show(); }
virtual void show() { } };
class B: public A{ public: virtual void show() { } };
int main() { B b; b.foo(); } B 类型的调用的foo为什么 打印出来的是A类型的呢? |
|
在成员函数内部的this指针无论何时都是指向该类对象的指针,因此b调用了A类的成员函数foo,那么this的类型也是A类的 |
● 父类和子类的this
|
父类和子类的this |
|
//简单案例: #include <iostream> using namespace std; class A { public: A() {a=4; } protected: private: int a; }; class B:public A { public: B() {b=73; } protected: private: int b; }; int main() { B tb; return 0; } |
|
在A()下设断点,此时this类型为A * const; 在B()下设断点,此时this类型为B * const。 |
|
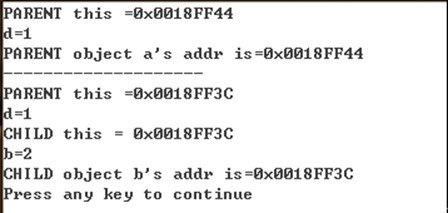
//复杂案例 #include <iostream.h> class PARENT { //基类 int d;
public: PARENT() { d=1; cout<<"PARENT this ="<<this<<endl; cout<<"d="<<this->d<<endl; }
}; class CHILD : public PARENT//子类 { int b;
public: CHILD():PARENT() { b=2; cout<<"CHILD this = "<<this<<endl; cout<<"b="<<this->b<<endl; } };
int main(int argc, char* argv[]) { CHILD cb;//CHILD类的对象 cout<<"CHILD object cb's addr is="<<&cb<<endl; return 0; } |
|
我们看到子类中的 CHILD():PARENT() 意味着子类调用了父类的构造函数(子类本身不能继承父类的构造函数), 但是因为this指针在子类里面, 所以即使PARENT()是属于父类的构造函数, PARENT()构造函数里的this指向的是子类的对象b. 在Qt编程中, 我们经常看到类似如下的代码: Widget::Widget(QWidget *parent) : QWidget(parent), ui(new Ui::Widget) { ui = new Ui::Widget; ui->setupUi(this); } QWidget(parent)意味着子类Widget调用了父类函数函数, ui->setupUi(this);这一句中的this指向的是子类Widget的对象(不是父类QWidget的对象) |
● 父类指针访问子类对象的成员
|
提问: 父类指针能否访问子类对象的成员(前提是子类为普通继承类,并且不用虚函数)? |
|
答: 不能,不用虚函数,即使进行了强制类型转换,也只能通过基类指针访问派生类的基类被继承过去的成员,它是不能够访问派生类的非虚成员函数的. |
● 父类指针接收子类对象指针怎么理解?
|
先做如下三个类假设 class A {} class B : public A {} class C : public B {}
若某函数 定义为 fun(A * pa);
你完全可以这样调用它,B b; fun(&b);
从逻辑上很好理解,因为类B、类C的实例是可以看作类A的实例的。 从内存上看,形如 A -------- B --------++++++++ C --------++++++++~~~~~~~~
- 记号表示类A的成员,+ 表示类B的成员,~表示类C的成员。示意各类占用的内存情况,可以很明显的看出来,类C的前部存放的是类B的内容,而类B的前部存放的是类A的内容。 |
● 父类指针和子类指针之间转换的问题
|
有如下代码: class ClassA { public: virtual ~ClassA(){} virtual void FunctionA(){} };
class ClassB { public: virtual void FunctionB(){} };
class ClassC :public ClassA , public ClassB {
}; 关于pA,pB,pC的取值,下面的描述中正确的是:
A、 pA,pB,pC的取值相同。
B、pC= pA+pB
C、 pA,pB不相同
D、pC不等于pA也不等于pB
ClassC对象构建的时候,先调用A的构造函数,构造A,后调用B的构造函数构造B,最后调用C的构造函数构造C独有的数据。所以在内存中pA和pC都指向对象在内存中的起始位置,pA=pc。但是pB指向对象ClassC时,只是指向ClassB那一部分。所以,答案选择C。
6.参照上面的代码,假设定义了 ClassA* pA2,下面正确的代码是:
A.pA2=static_cast<ClassA*>(pB);
B.void* pVoid=static_cast<void*>(pB);
pA2=static_cast<ClassA*>(pVoid);
C.pA2=pB;
D.pA2=static_cast<ClassA*>(static_cast<ClassC*>(pB));
这道题目涉及到两个知识点,一个是父类指针和子类指针之间转换的问题,一个是static_cast的使用。
下面讲解下这两个知识点,相信看完后上面的题目就很明确了。
(1)首先子类指针转换为父类指针是可以的,父类指针使用时简单的截断内存就可以。但是父类指针转换为子类指针是不安全的,因为在使用子类指针访问父类对象时可能超出对象的内存空间。
(2)static_cast的使用。
基类和子类之间转换:其中子类指针转换成父类指针是安全的;但父类指针转换成子类指针是不安全的。(基类 和子类之间的动态类型转换建 议用dynamic_cast) 基本数据类型转换。enum, struct, int, char, float等。static_cast不能进行无关类型(如非基类和子类)指 针之间的转换。 把空指针转换成目标类型的空指针。 把任何类型的表达式转换成void类型。 static_cast不能去掉类型的const、volitale属性(用const_cast)。 借用一段实例代码如下:
int n = 6;
double d = static_castdouble>(n); // 基本类型转换
int *pn = &n;
double *d = static_castdouble *>(&n) //无关类型指针转换,编译错误
void *p = static_castvoid *>(pn); //任意类型转换成void类型
所以答案B是正确的。对于答案D,父类转子类时不安全的,在编译器下有可能是能够通过的,但不是正确的。 |
● C++中定义没有参数的函数有两种方法
|
方法1(空括号法): 返回值类型 函数名() { 函数体; } 例如: int getarand() { return rand()%10; //产生一个0-9之间的随机数 } 方法2(强调法): 返回值类型 函数名(void) { 函数体; } int getarand(void) { return rand()%10; //产生一个0-9之间的随机数 } |
● 在new对象的时候有加上(),有不加(),不知道这个到底是什么区别
|
在new对象的时候有加上(),有不加(),不知道这个到底是什么区别? 比如: CBase *base = new CDerived(); CBase *base = new CDeviced; |
|
对于除了默认构造函数, 还有重载的构造函数的类,不论有没有括号,都用重载的构造函数进行初始化;如果只有默认构造函数的类,则不加括号的new只分配内存空间,不进行内存的初始化,而加了括号的new会在分配内存的同时初始化为0。 |
● 综合案例
|
下面这个案例涉及到①构造函数的重载;②引用作形参;③无名对象 |
|
#include<iostream> #include<iomanip> using namespace std; //------------------------------------- class Date{ int year, month, day; public: Date(int y=2000, int m=1, int d=1); // 设置默认参数 Date(const string& s); // 重载 bool isLeapYear()const; friend ostream& operator<<(ostream& o, const Date& d); };//----------------------------------- Date::Date(const string& s){ year = atoi(s.substr(0,4).c_str()); month = atoi(s.substr(5,2).c_str()); day = atoi(s.substr(8,2).c_str()); }//------------------------------------ Date::Date(int y, int m, int d){ year=y,month=m,day=d; } //------------------------------------- bool Date::isLeapYear()const{ return (year % 4==0 && year % 100 )|| year % 400==0; }//------------------------------------ ostream& operator<<(ostream& o, const Date& d){ o<<setfill('0')<<setw(4)<<d.year<<'-'<<setw(2)<<d.month<<'-'; return o<<setw(2)<<d.day<<' '<<setfill(' '); }//------------------------------------ int main(){ Date c("2005-12-28"); Date d(2003,12,6); Date e(2002); // 默认两个参数 Date f(2002,12); // 默认一个参数 Date g; // 默认三个参数 cout<<c<<d<<e<<f<<g; }//====================================
|
|
|

● 一次性对象(only-one-time object)/匿名对象/无名对象
|
一次性对象(only-one-time object)/匿名对象/无名对象 |
|
创建对象时如果不给出对象名,也就是说直接以类名调用构造函数,则产生一个无名对象,无名对象经常在参数传递时用到。例如: cout << Date(2011, 2, 22) << endl; Date(2011, 2, 22)是一个对象,该对象在做了<< 操作后便烟消云散了,所以这种对象一般用在创建后不需要反复使用的场合。 再如: string("abc"),这句话产生的就是一个无名对象,这个对象产生以后,没有什么办法使用它。但是对于string str("abc")来说,则产生的是一个有名字的对象,他的名字就是 str。 |
● 定义二维数组为什么只可以省略第一维的长度?
|
定义二维数组为什么可以省略第一维的长度,但却不能省略第二维的长度啊? |
|
有初始化的时候,第二维的数字代表分配内存的长度,第一维的数字代表分配内存倍数; 倍数可以让机器去数,但长度没有的话就不好开辟空间了。 |
● 连接字符串(concatenate strings)
|
#include <stdio.h>
main() { printf("hello" "world "); } |
|
|

● 有关void* p=NULL;
|
有关void* p=NULL; //Address of an untyped block of memory |
|
#include <stdio.h>
int main() { int *p = NULL; (int *&)p = (int *)p + 1; void *pDest = NULL; (char *&)pDest = (char *)pDest+1; return 0; } |
|
编译通过, 无结果:
|

● 有关stdafx.h 文件
|
stdafx.h即Standard Application Framework Extensions, 它是包含头文件的包含文件, 是vc生成工程是生成的用户头文件,属于工程的一部分,stdafx.h是vc工程的预编译头文件。用于包含工程中每个都文件都要包含的文件。用于加快编译速度和整理代码结构 比如工程由四个cpp文件组成: a.cpp b.cpp c.cpp d.cpp 每个cpp文件都要包含: stdio.h stdlib.h windows.h 那么可以把: #include <stdio.h> #include <stdlib.h> #include <windows.h> 放到stdafx搜索.h中, 而每个cpp只需要#include "stdafx.h"即可. 这样在便于维护代码,配合上编译器的预编译功能,还可以加快编译速度
如果不喜欢vc自动生成stdafx.h 在生成工程时选中empty project即可 |
● 基类指针和派生类指针指向基类对象和派生类对象的4中方法
|
1. 基类指针指向基类对象,简单。只需要通过基类指针简单地调用基类的功能。 2. 派生类指针指向派生类对象,简单。只需要通过派生类指针简单地调用派生类功能。 3. 将基类指针指向派生类对象是安全的,因为派生类对象"是"它的基类的对象。(例如, 哺乳动物是动物的子类, 兔子既是子类哺乳动物的对象, 也是基类动物的对象 ) 但是要注意的是,这个指针只能用来调用基类的成员函数。 如果试图通过基类指针调用派生类才有的成员函数,则编译器会报错。 为了避免这种错误,必须将基类指针强制转化为派生类指针。然后派生类指针可以用来调用派生类的功能。这称为向下强制类型转换,这是一种潜在的危险操作。 注意:如果在基类和派生来中定义了虚函数(通过继承和重写),并同过基类指针在派生类对象上调用这个虚函数,则实际调用的是这个函数的派生类版本。 4. 将派生类指针指向基类对象,会产生编译错误。"是"关系只适用于从派生类到它的直接(或间接)基类,反过来不行。 基类对象并不包含派生类才有的成员,这些成员只能通过派生类指针调用。 |
● 为什么要用基类指针指向子类的动态对象?
|
因为可以使用统一的虚函数, 这样结构比较统一。 分类少的时候当然可以逐类进行遍历, 但是分类多的时候就应该用基类指针调用虚函数了, 这样便于阅读和维护。 |
● 句柄(handle)
|
(Microsoft Press,by Richard Wilton) 在Windows环境中,句柄是用来标识项目的,这些项目包括:模块(module)、任务(task)、实例 (instance)、文件(file)、内存块(block of memory)、菜单(menu)、控制(control)、字体(font)、资源(resource),包括图标(icon),光标 (cursor),字符串(string)等、GDI对象(GDI object),包括位图(bitmap),画刷(brush),元文件(metafile),调色板(palette),画笔(pen),区域 (region),以及设备描述表(device context)。
(南京大学出版社): 句柄是WONDOWS用来标识被应用程序所建立或使用的对象的唯一整数,WINDOWS使用各种各样的句柄标识诸如应用程序实例,窗口,控制,位图,GDI对象等等。WINDOWS句柄有点象C语言中的文件句柄。 |
|
句柄和指针的联系: 而指针本质就是地址,它也可以区别不同的对象,但是是可以直接访问所指的对象的。
句柄是人为定义出来的为了区分不同的对象(I/O设备,窗口,文件,控件,等等)的整数,但是我们不能直接访问这些对象, 这些整数作为标识可以被系统重新定位到一个内存地址上, 这种间接访问对象的模式增强了系统对引用对象的控制。 总之, 可以把句柄理解为就是一个指针的指针,windows为了让实际地址隐藏起来,只由操作系统来管理,所以没有把直接的地址给用户,需要间接访问。 |
● 关于上转型对象
|
设类B是类A的派生类(子类),具备基类(父类)A的一切特征(A类中所有的成员B类都有),所以使用派生类的构造函数构造的对象可以直接使用A类的指针(△引用呢?)。 我们一般习惯把这种使用派生类的构造函数构造对象并由基类的句柄(指针)来引用的对象称为"上转型"对象。 使用"上转型"对象需要注意,我们无法使用派生类独有而基类中没有的成员, 如果要使用这些特有方法, 我们就必须使用具体类的指针, 方法有二:① 直接使用具体类的指针; ②将基类指针下行转换为下行指针----用宏dynamic_cast(在进行下行转换时, dynamic_cast比ststic_cast更安全) 另外,如果派生类有重写基类的虚函数,调用上转型对象的成员函数时,将执行派生类重写的虚函数中的内容而不执行基类中的对应成员函数的内容, 这就是多态的一种实现方式。 上转型对象中,用作引用的基类可以是抽象类,还可以是虚基类(相当于Java中的接口)。而且,抽象类和虚基类(接口)不能直接创建对象实例,只能用它的派生类(或实现类)的构造函数来创建抽象类或虚基类(接口)类型的对象实例。(比如说,如果题中的类A是抽象类,使用A *a=new A()是错误的,只能使用A *a=new B()来创建类A类型的对象实例。) |
● volatile关键字
|
volatile (adj. 挥发性的, 不稳定的, 可变的) volatile 影响编译器编译的结果,指出,volatile 变量是随时可能发生变化的,与volatile变量有关的运算,不要进行编译优化,以免出错,(VC++ 在产生release版可执行码时会进行编译优化,加volatile关键字的变量有关的运算,将不进行编译优化。)。 例如: volatile int i=10; int j = i; ... //这里的代码没有对i进行过操作 int k = i; volatile 告诉编译器i是随时可能发生变化的,每次使用它的时候必须从i的地址中读取,因而编译器生成的可执行码会重新从i的地址读取数据放在k中。 而优化做法是,由于编译器发现两次从i读数据的代码之间的代码没有对i进行过操作,它会自动把上次读的数据放在k中,而不是重新从i里面读。这样以来,如果i是一个寄存器变量或者表示一个端口数据就容易出错,所以说volatile可以保证对特殊地址的稳定访问,不会出错。 |
● Boost库
|
Boost库是一个经过千锤百炼、可移植、提供源代码的C++库,作为标准库的后备,是C++标准化进程的发动机之一。 Boost库由C++标准委员会库工作组成员发起,在C++社区中影响甚大,其成员已近2000人。 Boost库为我们带来了最新、最酷、最实用的技术,是不折不扣的"准"标准库。 |
● 随机数
|
srand()需要和和rand()配合使用才能产生伪随机数序列, srand()用来初始化随机种子, rand()用来产生随机数。 rand函数在产生随机数前,需要系统提供的生成伪随机数序列的种子,rand根据这个种子的值产生一系列随机数。如果系统提供的种子没有变化,每次调用rand函数生成的伪随机数序列都是一样的。 ※ 种子(seed, 一个整数), 我们可以自己设置, 如srand (1); 再如srand( (time(NULL) ); 其中time(NULL)函数是得到一个从1900年1月1日到现在的时间秒数. |
|
#include <stdio.h> /* printf, NULL */ #include <stdlib.h> /* srand, rand */ #include <time.h> /* time */
int main () { printf ("First number: %d ", rand()%100); srand (time(NULL)); printf ("Random number: %d ", rand()%100); srand (1); printf ("Again the first number: %d ", rand()%100); return 0; } 第一次运行:
第二次运行:
|


● explicit作用
|
在C++中,explicit关键字用来修饰类的构造函数,被修饰的构造函数的类,可防止以上隐式类型转换的发生,只能以显示的方式进行类型转换。 |
● 0和1的矛盾之处
|
① bool值的0和1: FALSE/TRUE与false/true的区别: false/true是标准C++语言里新增的关键字,而FALSE/TRUE是通过#define定义的,以下是FALSE/TRUE在windef.h的定义: #ifndef FALSE #define FALSE 0 #endif #ifndef TRUE #define TRUE 1 #endif 也就是说FALSE/TRUE是int类型,而false/true是bool类型;所以两者不一样的,只不过 我们在使用中没有这种感觉,因为C++会帮你做隐式转换。
※ BOOL和bool的区别 一、 1、类型不同 BOOL为int型 bool为布尔型 2、长度不同 bool只有一个字节 BOOL长度视实际环境来定,一般可认为是4个字节 3、取值不同 bool取值false和true,是0和1的区别 BOOL取值FALSE和TRUE,是0和非0的区别 二: bool是标准C++数据类型,可取值true和false。 BOOL是微软定义的typedef int BOOL。
return 0是正常退出,return 非零是异常退出,这是返回给控制台的,不在你编的程序的控制范围内,是给操作系统识别的,对你的程序无影响。 |
● What is class invariant(类不变项)?
|
A class invariant is a condition that defines all valid states for an object. It is a logical condition to ensure the correct working of a class. Class invariants must hold when an object is created, and they must be preserved under all operations of the class. In particular all class invariants are both preconditions and post-conditions for all operations or member functions of the class. |
● C++中虚析构函数的作用
|
析构函数加virtual关键字的目的是: 当用一个基类的指针删除一个派生类的对象时,派生类的析构函数会被调用, 从而释放内存资源, 防止内存泄漏. |
|
class ClxBase { public: ClxBase() {}; virtual ~ClxBase() {};
virtual void DoSomething() { cout << "Do something in class ClxBase!" << endl; }; };
class ClxDerived : public ClxBase { public: ClxDerived() {}; ~ClxDerived() { cout << "Output from the destructor of class ClxDerived!" << endl; };
void DoSomething() { cout << "Do something in class ClxDerived!" << endl; }; };
//主函数的代码 ClxBase *pTest = new ClxDerived; pTest->DoSomething(); delete pTest;
//输出结果是: Do something in class ClxDerived! Output from the destructor of class ClxDerived!
//如果把类ClxBase析构函数前的virtual去掉,那输出结果是: Do something in class ClxDerived! |
● 为什么内联函数,构造函数,静态成员函数不能为virtual函数?
|
1> 内联函数 内联函数是在编译时期展开,而虚函数的特性是运行时才动态联编,所以两者矛盾,不能定义内联函数为虚函数。
2> 构造函数 构造函数用来创建一个新的对象,而虚函数的运行是建立在对象的基础上,在构造函数执行时,对象尚未形成,所以不能将构造函数定义为虚函数。
3> 静态成员函数 静态成员函数属于一个类而非某一对象,没有this指针,它无法进行对象的判别。 |
● getch()、getche()和getchar()之间的区别
|
getch(): 从键盘上读入一个字符, 不会回显到显示屏幕上, 无需回车; getche(): 从键盘上读入一个字符, 而且将读入的字符回显到显示屏幕上; getchar():从键盘上读入字符, 直到按回车才结束, 回车前的所有输入字符都会逐个显示在屏幕上。但只有第一个字符作为函数的返回值。 |
|
Visual C++ 的源文件目录下不允许有两个源文件分别定义main,需要删除一个 |
|
|
|
注释: 先CTRL+K,然后CTRL+C 取消注释: 先CTRL+K,然后CTRL+U |
● char arr[] 和char* p的区别
|
char arr[]="abc"; arr[0]='c'; // 合法
char *p="abc"; p[0]='c'; // 非法 |
|
两个"abc"都是存储在静态存储区,即常量区。 ① 如果将"abc"赋值给char arr[], 那么, 程序在开始运行时, arr会在栈上申请空间,常量区的 "abc"会被拷贝到栈内存去,所以"xxxxx""就可写了。 PS. arr是一个常量指针,arr不可改变,但arr指向的内容可以发生改变 ② 如果将"abc"赋值给char *p, p仍指向"abc"这个常量的地址, 即"abc"仍不可写. PS. p是一个可变指针p,p可以指向其它对象(也就是拿另一个变量的地址赋给p), p本身可变, p指向的内容不可变.
※ 初始化数组把静态存储区的字符串拷贝到数组中;而初始化指针只把字符串的地址拷贝给指针。 |
|
① char arr[]定义了一个数组,arr是一个常量指针,arr不可改变,但arr指向的内容可以发生改变。 ② char *p定义了一个可变指针p,p可以指向其它对象(也就是拿另一个变量的地址赋给p), 但是对于char *p="xxxxx",p指向的是常量,故内容不能改变。 |
|
char arr[] = "xxxxx",arr会在栈上申请空间,将常量"xxxxx"内容复制进来,所以"xxxxx"变成了可以改变的局部变量。 char *p= "xxxxx",p指向"xxxx x"这个常量的地址。 |
● 类的访问控制
|
下面对类继承的访问控制比较详细:eee |
|
在派生类的定义中,每一种继承方式只限定紧跟其后的那个基类。如果不显式给出继承方式,系统默认为私有继承。 公有方式继承的特点: ① 基类的公有成员在派生类中仍然为公有成员,可以由派生类对象和派生类成员函数直接访问。 ② 基类的私有成员在派生类中,无论是派生类的成员还是派生类的对象都无法直接访问。 ③ 保护成员在派生类中仍是保护成员,可以通过派生类的成员函数访问,但不能由派生类的对象直接访问。
注意: 对基类成员的访问,一定要分清是通过派生类对象访问还是通过派生类成员函数访问。
私有方式继承的特点: ①基类的公有成员和保护成员被继承后作为派生类的私有成员,即基类的公有成员和保护成员被派生类吸收后,派生类的其他成员函数可以直接访问它们,但是在类外部,不能通过派生类的对象访问它们。 ②基类的私有成员在派生类中不能被直接访问。无论是派生类的成员还是通过派生类的对象,都无法访问从基类继承来的私有成员。 ③经过私有继承之后,所有基类的成员都成为了派生类的私有成员或不可访问的成员,如果进一步派生的,基类的全部成员将无法在新的派生类中被访问。因此,私有继承之后,基类的成员再也无法在以后的派生类中发挥作用,实际是相当于中止了基类的继续派生,出于这种原因,一般情况下私有继承的使用比较少。
保护继承的特点: ①基类的公有成员和保护成员被继承后作为派生类的保护成员。 ②基类的私有成员在派生类中不能被直接访问。 |
● 类型兼容
|
类型兼容是指在公有派生的情况下,一个派生类对象可以作为基类的对象来使用的情况。类型兼容又称为类型赋值兼容或类型适应。 |
|
#include<iostream> using namespace std; class Base1{ public: void diaplay() const{ cout<<"enter Base1::display"<<endl; } }; class Base2:public Base1{ public: void diaplay() const{ cout<<"enter Base2::display"<<endl;} }; class Base3:public Base2{ public: void diaplay() const{cout<<"enter Base3::display"<<endl;} }; void fun(Base1 *str){ //这里形参为基类类型Base1的对象, 但也可以用Base1的子类的对象作形参 str->diaplay(); } int main(){ Base1 bb1; Base2 bb2; Base3 bb3; fun(&bb1); fun(&bb2); fun(&bb3); return 0; } |
● 派生类构造函数的定义
|
派生类名(参数总表): 基类名1(参数表1),...,基类名m (参数表m), 成员对象名1(成员对象参数表1),...,成员对象名n(成员对象参数表n) { 派生类新增成员的初始化; } |
|
● C++类的构造函数后单冒号加基类
|
class A { A(int *x); ... } class B : public A { B(int *x); ... } //然后在构造B的时候 B::B(int *x) : A(x) { ... } |
|
B是A的子类,B类对象在构造过程中必须先构造出一个A类对象,而A类的构造函数需要一个参数,于是就在这个A(X)中把参数传递过去。这种写法叫"初始化列表",它会在B的构造函数的{...}之前执行。 如果不加,A又没有无参数的默认构造函数,不能通过编译. |
● 运算符重载机制
|
|

● 运算符 重载为类的友元函数 和 重载为类的成员函数 这两种重载形式的比较:
|
在多数情况下,既可将运算符重载为类的成员函数,也可以重载为类的友元函数。但成员函数运算符与友元函数运算符也具有各自的一些特点: (1) 一般情况下,单目运算符最好重载为类的成员函数;双目运算符则最好重载为类的友元函数。 (2) 一些双目运算符不能重载为类的友元函数:=、()、[]、->。 (3) 类型转换函数只能定义为一个类的成员函数而不能定义为类的友元函数。 (4) 若一个运算符的操作需要修改对象的状态,选择重载为成员函数较好。 (5) 若运算符所需的操作数(尤其是第一个操作数)希望有隐式类型转换,则只能选用友元函数。 (6) 当运算符函数是一个成员函数时,最左边的操作数(或者只有最左边的操作数)必须是运算符类的一个类对象(或者是对该类对象的引用)。如果左边的操作数必须是一个不同类的对象,或者是一个基本数据类型的对象,该运算符函数必须作为一个友元函数来实现。 (7) 当需要重载运算符的运算具有可交换性时,选择重载为友元函数。 |