本文摘于云游道士 链接:https://www.cnblogs.com/yyds/p/7288916.html
个人简化,便于查询.
命令行指令的执行通常有两个比较关注的结果:
- 命令执行的状态码--表示命令执行是否成功
- 命令执行的输出结果--命令执行成功后的输出
早期的Python版本中,主要是通过os.system()、os.popen().read()等函数来执行命令行指令的,另外还有一个很少使用的commands模块。从Python 2.4开始官方文档中建议使用的是subprocess模块,重要要介绍的是subprocess模块。subprocess是Python 2.4中新增的一个模块,它允许你生成新的进程,连接到它们的 input/output/error 管道,并获取它们的返回(状态)码。这个模块的目的在于替换几个旧的模块和方法.
subprocess常用参数:(初级应用)
| 方法 | 描述 |
|---|---|
| subprocess.run() | 执行指定的命令,等待命令执行完成后返回一个包含执行结果的CompletedProcess类的实例。 |
| subprocess.call() | 执行指定的命令,返回命令执行状态,其功能类似于os.system(cmd)。 |
| subprocess.check_call() | 执行指定的命令,如果执行成功则返回状态码,否则抛出异常。其功能等价于subprocess.run(..., check=True)。 |
| subprocess.check_output() | 执行指定的命令,如果执行状态码为0则返回命令执行结果,否则抛出异常。 |
| subprocess.getoutput(cmd) | 接收字符串格式的命令,执行命令并返回执行结果,其功能类似于os.popen(cmd).read()和commands.getoutput(cmd)。 |
| subprocess.getstatusoutput(cmd) | 执行cmd命令,返回一个元组(命令执行状态, 命令执行结果输出),其功能类似于commands.getstatusoutput()。 |
就使用目的,主要选了subprocess.getoutput(cmd) 和 subprocess.getstatusoutput(cmd) 参数为例.
>>> ret = subprocess.getoutput('ls -l') >>> print(ret) 总用量 160 drwxr-xr-x 2 wader wader 4096 12月 7 2015 公共的 drwxr-xr-x 2 wader wader 4096 12月 7 2015 模板 drwxr-xr-x 2 wader wader 4096 12月 7 2015 视频 ... >>> retcode, output = subprocess.getstatusoutput('ls -l') >>> print(retcode) 0 >>> print(output) 总用量 160 drwxr-xr-x 2 wader wader 4096 12月 7 2015 公共的 drwxr-xr-x 2 wader wader 4096 12月 7 2015 模板 drwxr-xr-x 2 wader wader 4096 12月 7 2015 视频 ... drwxr-xr-x 7 wader wader 4096 5月 26 2016 桌面 >>> retcode, output = subprocess.getstatusoutput('ls -l /test') >>> print(retcode) 2 >>> print(output) ls: 无法访问/test: 没有那个文件或目录
以上的都是 弱鸡!!! 以下的才是正解! 实际运用可全部跳过,看最后总结!!!!!!
subprocess.Popen
用于在一个新的进程中执行一个子程序。上面介绍的这些函数都是基于subprocess.Popen类实现的,通过使用这些被封装后的高级函数可以很方面的完成一些常见的需求。由于subprocess模块底层的进程创建和管理是由Popen类来处理的,因此,当无法通过上面哪些高级函数来实现一些不太常见的功能时就可以通过subprocess.Popen类提供的灵活的api来完成。
class subprocess.Popen(args, bufsize=-1, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=True, shell=False, cwd=None, env=None, universal_newlines=False, startup_info=None, creationflags=0, restore_signals=True, start_new_session=False, pass_fds=())
参数说明:
- args: 要执行的shell命令,可以是字符串,也可以是命令各个参数组成的序列。当该参数的值是一个字符串时,该命令的解释过程是与平台相关的,因此通常建议将args参数作为一个序列传递。
- bufsize: 指定缓存策略,0表示不缓冲,1表示行缓冲,其他大于1的数字表示缓冲区大小,负数 表示使用系统默认缓冲策略。
- stdin, stdout, stderr: 分别表示程序标准输入、输出、错误句柄。
- preexec_fn: 用于指定一个将在子进程运行之前被调用的可执行对象,只在Unix平台下有效。
- close_fds: 如果该参数的值为True,则除了0,1和2之外的所有文件描述符都将会在子进程执行之前被关闭。
- shell: 该参数用于标识是否使用shell作为要执行的程序,如果shell值为True,则建议将args参数作为一个字符串传递而不要作为一个序列传递。
- cwd: 如果该参数值不是None,则该函数将会在执行这个子进程之前改变当前工作目录。
- env: 用于指定子进程的环境变量,如果env=None,那么子进程的环境变量将从父进程中继承。如果env!=None,它的值必须是一个映射对象。
- universal_newlines: 如果该参数值为True,则该文件对象的stdin,stdout和stderr将会作为文本流被打开,否则他们将会被作为二进制流被打开。
- startupinfo和creationflags: 这两个参数只在Windows下有效,它们将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如主窗口的外观,进程优先级等。
subprocess.Popen类的方法
| 方法 | 描述 |
|---|---|
| Popen.poll() | 用于检查子进程(命令)是否已经执行结束,没结束返回None,结束后返回状态码。 |
| Popen.wait(timeout=None) | 等待子进程结束,并返回状态码;如果在timeout指定的秒数之后进程还没有结束,将会抛出一个TimeoutExpired异常。 |
| Popen.communicate(input=None, timeout=None) | 该方法可用来与进程进行交互,比如发送数据到stdin,从stdout和stderr读取数据,直到到达文件末尾。 |
| Popen.send_signal(signal) | 发送指定的信号给这个子进程。 |
| Popen.terminate() | 停止该子进程。 |
| Popen.kill() | 杀死该子进程。 |
关于communicate()方法的说明:
- 该方法中的可选参数 input 应该是将被发送给子进程的数据,或者如没有数据发送给子进程,该参数应该是None。input参数的数据类型必须是字节串,如果universal_newlines参数值为True,则input参数的数据类型必须是字符串。
- 该方法返回一个元组(stdout_data, stderr_data),这些数据将会是字节穿或字符串(如果universal_newlines的值为True)。
- 如果在timeout指定的秒数后该进程还没有结束,将会抛出一个TimeoutExpired异常。捕获这个异常,然后重新尝试通信不会丢失任何输出的数据。但是超时之后子进程并没有被杀死,为了合理的清除相应的内容,一个好的应用应该手动杀死这个子进程来结束通信。
- 需要注意的是,这里读取的数据是缓冲在内存中的,所以,如果数据大小非常大或者是无限的,就不应该使用这个方法。
subprocess.Popen使用实例
实例1:
import subprocess info = subprocess.Popen("ipconfig ",stdout=subprocess.PIPE,shell=True) print(info.stdout.read().decode("gbk")) print(type(info.stdout.read()))

实例二:
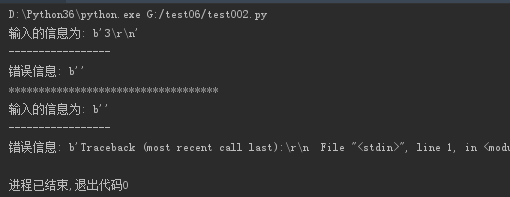
import subprocess #第一条 obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE) obj.stdin.write("print(1+2)".encode()) #out为执行后的结果,err为错误信息. out,err = obj.communicate() print("输入的信息为:",out) print("-----------------") print("错误信息:",err) print("*" * 35) #第二条 obj2 = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE) obj2.stdin.write("print(x+1)".encode()) out2,err2 = obj2.communicate() print("输入的信息为:",out2) print("-----------------") print("错误信息:",err2)
实例三:
实现类似df -Th | grep data命令的功能,实际上就是实现shell中管道的共功能。
>>> >>> p1 = subprocess.Popen(['df', '-Th'], stdout=subprocess.PIPE) >>> p2 = subprocess.Popen(['grep', 'data'], stdin=p1.stdout, stdout=subprocess.PIPE) >>> out,err = p2.communicate() >>> print(out) /dev/vdb1 ext4 493G 4.8G 463G 2% /data /dev/vdd1 ext4 1008G 420G 537G 44% /data1 /dev/vde1 ext4 985G 503G 432G 54% /data2 >>> print(err) None
总结:
import subprocess #subprocess 用于系统交互 #subprocess.Popen() #有三条管道: #stdout:输出管道,输出的结果会加入到这个管道中, .read()读取 #stdin:标准输入管道 #stderr:错误输出管道,输入的命令错误后,会将结果加入到这个管道中,.read()读取.当命令执行正常时,管道为None. #info.stdout.read()输出的结果为 二级制数据,在显示时,需要转码. re = input("输入命令:") info = subprocess.Popen(re,shell=True,stdout=subprocess.PIPE, stdin=subprocess.PIPE, stderr=subprocess.PIPE) print(info.stdout.read().decode("gbk"))