基础资料
1.1页
SQL Server 中数据存储的基本单位是页。编号0-n,所有IO 操作在页级执行,不论是磁盘IO或是缓存池IO(Buffer Pool).
下图是页的结构
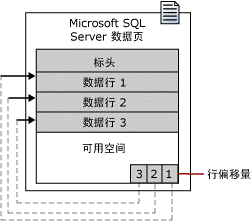
注:
1 每个页固定大小是8K,其中标头固定占96字节,页尾部行偏移信息占36字节,剩余空间8060字节是有效空间,存放数据以及开销。
2 如果数据行中包含数据类型为varchar、nvarchar、varbinary 和 sql_variant的列,导致该行超出8060字节,则该列会被移到ROW_OVERFLOW_DATA(行溢出数据) 分配单元中的页,而在原位置生成一个24字节的指针,此后该列长度减少,又会被移到原始数据页(IN_ROW_DATA,行内数据)。
另,varchar(max)、nvarchar(max)、varbinary(max)、ntext、text、image 或 xml列由表选项控制,直接存放在LOB类型页(LOB_DATA)或者存储16字节指针在原页实际数据存放LOB类型页。
开始验证,环境sqlserver 2008 r2,版本号10.50.1600,固定长度列的情况不再演示,仅仅演示下变长,且溢出的情况
1 行溢出列
CREATE TABLE test1(ID INT NOT NULL,col VARCHAR(8000),col1 CHAR(8000));
INSERT INTO test1
SELECT 1,REPLICATE('a',2000),'b'—col1是定长数据,为IN_ROW_DATA,col是变长,且此时该行数据长度超过8K页范围
--查看页数

--查看页ID以及实际数据情况
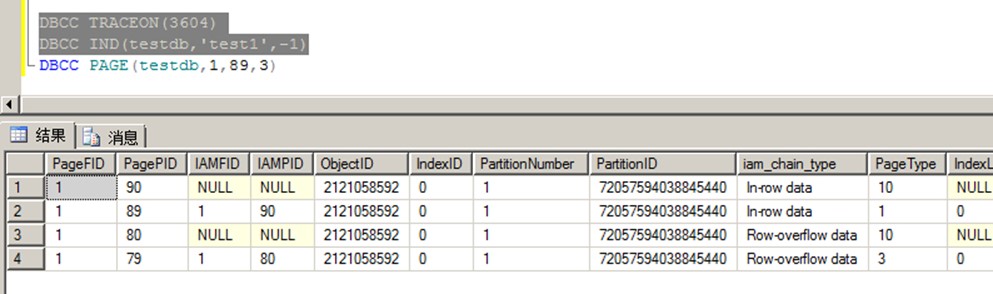
注:PageType 1 数据页 2 索引页 3 LOB页 10 IAM页(Index Allocation Map,每个表或者索引均有此类页,用来表示表或索引使用的区(extent,每8个连续页组成一个区)信息)
这几种页类型是数据页类型,其他管理类页此处暂不讨论。
页头部信息

数据信息
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 8039
Memory Dump @0x000000000EDFC060
0000000000000000: 3000481f 01000000 62202020 20202020 †0.H.....b
------此处略去n行
0000000000001F50: 00000001 0000009f 150000d0 0700004f †...............O (此处的变长数据存储区,因长度超出范围,存储24字节指针,下面可见)
0000000000001F60: 00000001 000000††††††††††††††††††††††.......
Slot 0 Column 1 Offset 0x4 Length 4 Length (physical) 4
ID= 1
col = [BLOB Inline Root] Slot 0 Column 2 Offset 0x1f4f Length 24 Length (physical) 24
Level = 0 Unused = 0 UpdateSeq = 1
TimeStamp = 362741760
Link 0
Size = 2000 RowId = (1:79:0) (指针指示的该变长列位置,从第一个图亦可看到,页79是行溢出数据)
2 LOB类型列
,text,ntext,image已经被varchar(max),nvarchar(max)取代,不再建议使用,此处以varchar(max)为例
--查看页数

注:可以看到,虽然插入的数据为4000个字符,但仍分配了一个LOB页,因为表选项已经开启,值为1
--查看页ID及实际数据

--页头略去
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 31
Memory Dump @0x000000000F99A060
0000000000000000: 30000800 01000000 0200e001 001f8000 †0...............
0000000000000010: 00d10700 00000072 00000001 000100††††.......r.......
Slot 0 Column 1 Offset 0x4 Length 4 Length (physical) 4
ID = 1
col = [Textpointer] Slot 0 Column 2 Offset 0xf Length 16 Length (physical) 16 (此处是指针,16字节)
TextTimeStamp = 131137536 RowId = (1:114:1)
然而,表的这个选项默认是0,即未开启,此时情况同varchar类型的行溢出列
1.2 索引
以下图是索引的结构

注:(1) 索引是一个B树结构,即从根节点到每一个叶子节点深度相同
(2) 每一个层级(根节点,中间节点,叶子节点)的页均被链接在双向链表中
(3) 不同的层级间,只能通过上级节点访问下一级节点
索引的root_page(根页),first_page(首页)可以通过sys.system_internals_allocation_units查看,详细内容不作介绍
2聚集索引键选择原则
2.1聚集索引所在的列或列的组合最好是唯一的
SQLServer操作数据的最小单元是页,所以,索引占用页数越少,读取索引速度越快
CREATE TABLE test4(ID INT NOT NULL ,col CHAR(200))
--创建聚集索引
CREATE CLUSTERED INDEX IXC_test4 ON test4(ID)
--插入20万条数据,每条重复2次
;WITH
L0 AS(SELECT 1 AS c UNION ALL SELECT 1),
L1 AS(SELECT 1 AS c FROM L0 AS A, L0 AS B),
L2 AS(SELECT 1 AS c FROM L1 AS A, L1 AS B),
L3 AS(SELECT 1 AS c FROM L2 AS A, L2 AS B),
L4 AS(SELECT 1 AS c FROM L3 AS A, L3 AS B),
L5 AS(SELECT 1 AS c FROM L4 AS A, L4 AS B),
Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY c) AS n FROM L5)
INSERT INTO test4
SELECT n,'a'
FROM Nums CROSS JOIN (SELECT 1 AS col UNION ALL SELECT 1) t
WHERE n <= 100000
--查看页数

--删除数据,再次插入20万条,不重复
TRUNCATE TABLE test4
;WITH
L0 AS(SELECT 1 AS c UNION ALL SELECT 1),
L1 AS(SELECT 1 AS c FROM L0 AS A, L0 AS B),
L2 AS(SELECT 1 AS c FROM L1 AS A, L1 AS B),
L3 AS(SELECT 1 AS c FROM L2 AS A, L2 AS B),
L4 AS(SELECT 1 AS c FROM L3 AS A, L3 AS B),
L5 AS(SELECT 1 AS c FROM L4 AS A, L4 AS B),
Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY c) AS n FROM L5)
INSERT INTO test4
SELECT n,'a'
FROM Nums
WHERE n <= 200000;
--再次查看

两次插入数据一样(int 4字节,char 200字节,都是定长),条数一样(200000),占用页数不同,为何?
--查看聚集索引有重复键值的情况,某个索引页

注:创建聚集索引不带UNIQUE关键字,则SQLServer会添加一个附加列uniquifier,用于区分唯一性,该列占用4字节
而使用了uniquifier后,对性能产生的影响如下:
(1)SQL Server必须在插入或者更新时对现在数据进行判断是否和现有的键重复,如果重复,则需要生成uniquifier。
(2)因为需要对相同值的键添加额外的uniquifier来区分,所以键的大小被额外的增加了。因此无论是叶子节点和非叶子节点,都需要更多的页进行存储。(这就是上述现象出现的原因)
从而还影响到了非聚集索引,使得非聚集索引的书签列变大,从而非聚集索引也需要更多的页进行存储。(因为非聚集索引要引用聚集索引的键列,下面环节2.3有演示)
以下是数据片段
0000000000000000: 1000d000 1d000000 61202020 20202020 †........a
--数据略去
00000000000000D0: 030000†††††††††††††††††††††††††††††††...
Slot 0 Column 0 Offset 0x0 Length 4 Length (physical) 0—-第一个值不加uniquifier
UNIQUIFIER = 0
Slot 0 Column 1 Offset 0x4 Length 4 Length (physical) 4
ID = 29
Slot 0 Column 2 Offset 0x8 Length 200 Length (physical) 200
col = a
Slot 0 Offset 0x0 Length 0 Length (physical) 0
KeyHashValue = (48f7cc7c34f7)
0000000000000000: 3000d000 1d000000 61202020 20202020 †0.......a
--数据略去
00000000000000D0: 03000001 00db0001 000000†††††††††††††...........
Slot 1 Column 0 Offset 0xd7 Length 4 Length (physical) 4—-第二个值加uniquifier,因为此时有重复数据了
UNIQUIFIER = 1
Slot 1 Column 1 Offset 0x4 Length 4 Length (physical) 4
ID = 29
Slot 1 Column 2 Offset 0x8 Length 200 Length (physical) 200
col = a
注:再次创建一样的表,建立唯一聚集索引 CREATE UNIQUE CLUSTERED INDEX IXC_test5 ON test5(ID)
结果和上述test4插入唯一数据的情况一样,占用5264个页
2.2使用窄列或窄列组合作为聚集索引列
这个道理和上面减少页的原理一样,窄列使得键的大小变小。使得聚集索引的非叶子节点减少,而非聚集索引的书签变小,从而叶子节点页变得更少。最终提高了性能。
2.3使用值很少变动的列或列的组合作为聚集索引列
为表创建聚集索引后,SQL Server按照键查找行。因为在B树中,数据是有序的,所以当聚集索引键发生改变时,不仅仅需要改变值本身,还需要改变这个键所在行的位置(RID,即磁盘上的位置,即上述图示常见的slot),因此有可能使得行从一页移动到另一页。 因此会带来如下问题:
行从一页移动到另一页,这个操作是需要开销的,不仅如此,这个操作还可能影响到其他行,使得其他行也需要移动位置,由此产生分页。
行在页之间的移动会产生索引碎片。
键的改变会影响到非聚集索引,使得非聚集索引的书签列也需要改变。
仅仅演示下非聚集索引引用聚集索引键列的情况,插入数据引起的行移动甚至页拆分暂不演示
CREATE TABLE test5(ID INT NOT NULL PRIMARY KEY ,ID1 INT NOT NULL )--主键默认是聚集索引,只要创建的时候是该表不存在其他索引,而且不加NONCLUSTERED关键字
--创建索引
CREATE INDEX IX_test5 ON test5(ID1)
--插入数据
;WITH
L0 AS(SELECT 1 AS c UNION ALL SELECT 1),
L1 AS(SELECT 1 AS c FROM L0 AS A, L0 AS B),
L2 AS(SELECT 1 AS c FROM L1 AS A, L1 AS B),
L3 AS(SELECT 1 AS c FROM L2 AS A, L2 AS B),
L4 AS(SELECT 1 AS c FROM L3 AS A, L3 AS B),
L5 AS(SELECT 1 AS c FROM L4 AS A, L4 AS B),
Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY c) AS n FROM L5)
INSERT INTO test5
SELECT n,n+1000
FROM Nums
WHERE n <= 10000;
--查看聚集索引
DBCC IND(testdb,'test5',1)

indexID>1的为非聚集索引,indexID=1的为聚集索引,indexlevel>0的为中间节点,PageType=2是索引页
页ID=10780是聚集索引中间节点,通过这个页可以查看叶子节点及起始键值
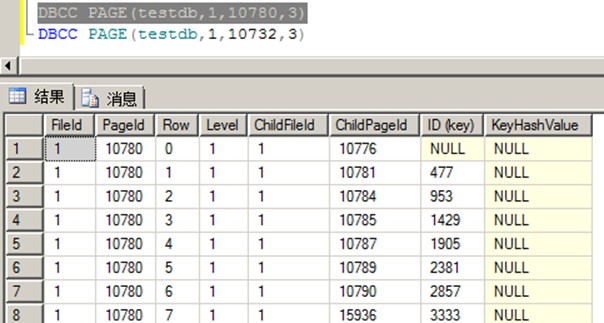
可以看到,没有uniquifier列,因为我们创建的聚集索引是主键,即PRIMARY KEY CLUSTERED
再次查询叶子节点childpageid即可看到索引页内容,不再演示
--查看非聚集索引
DBCC IND(testdb,'test5',-1)

indexID>1的为非聚集索引,indexlevel>0的为中间节点,10782
DBCC PAGE(testdb,1,10782,3)

可以看到,我们创建的非聚集索引键列是ID1,实际查到的有2个,其中一个是聚集索引的键列ID,正是通过这个键列才能找到不包含在非聚集索引中的其他列的数据
2.4最好使用自增列作为聚集索引列
同样推荐创建一个和数据本身无关的自增列作为聚集索引列。如上2.3所述,如果使用自增列,新行的插入则会大大的减少分页和碎片。
总结,聚集索引键列选择原则,唯,窄,增